7/10/23About 3 min
Spark-IoTDB
Version
The versions required for Spark and Java are as follow:
| Spark Version | Scala Version | Java Version | TsFile |
|---|---|---|---|
2.4.0-3.2.0 | 2.12 | 1.8 | 0.13.0 |
Notice
Spark IoTDB Connectoronly supports Spark2.4.5to3.2.0withScala 2.12.
If you need to support other versions, you can modify the Scala version of the POM file in the modulespark-iotdb-connectorin the source code and then recompile it.- There is a conflict of thrift version between IoTDB and Spark.
Therefore, if you want to debug in spark-shell, you need to executerm -f $SPARK_HOME/jars/libthrift*andcp $IOTDB_HOME/lib/libthrift* $SPARK_HOME/jars/to resolve it.
Otherwise, you can only debug the code in IDE. If you want to run your task byspark-submit, you must package with dependency.
Install
mvn clean scala:compile compile installMaven Dependency
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>spark-iotdb-connector</artifactId>
<version>0.13.0</version>
</dependency>spark-shell user guide
spark-shell --jars spark-iotdb-connector-0.13.0.jar,iotdb-jdbc-0.13.0-jar-with-dependencies.jar,iotdb-session-0.13.0-jar-with-dependencies.jar
import org.apache.iotdb.spark.db._
val df = spark.read.format("org.apache.iotdb.spark.db").option("url","jdbc:iotdb://127.0.0.1:6667/").option("sql","select * from root").load
df.printSchema()
df.show()To partition rdd:
spark-shell --jars spark-iotdb-connector-0.13.0.jar,iotdb-jdbc-0.13.0-jar-with-dependencies.jar,iotdb-session-0.13.0-jar-with-dependencies.jar
import org.apache.iotdb.spark.db._
val df = spark.read.format("org.apache.iotdb.spark.db").option("url","jdbc:iotdb://127.0.0.1:6667/").option("sql","select * from root").
option("lowerBound", [lower bound of time that you want query(include)]).option("upperBound", [upper bound of time that you want query(include)]).
option("numPartition", [the partition number you want]).load
df.printSchema()
df.show()Schema Inference
Take the following TsFile structure as an example: There are three Measurements in the TsFile schema: status, temperature, and hardware. The basic information of these three measurements is as follows:
| Name | Type | Encode |
|---|---|---|
| status | Boolean | PLAIN |
| temperature | Float | RLE |
| hardware | Text | PLAIN |
The existing data in the TsFile is as follows:
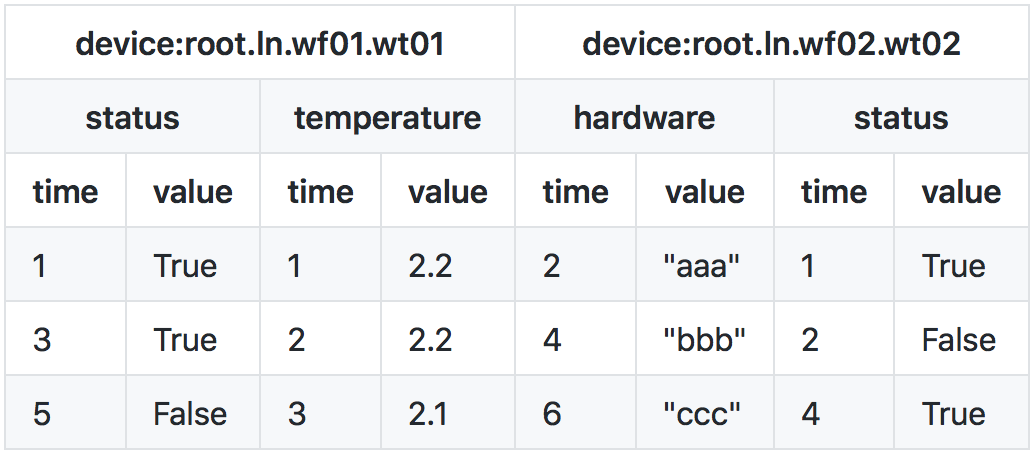
The wide(default) table form is as follows:
| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
|---|---|---|---|---|---|---|
| 1 | null | true | null | 2.2 | true | null |
| 2 | null | false | aaa | 2.2 | null | null |
| 3 | null | null | null | 2.1 | true | null |
| 4 | null | true | bbb | null | null | null |
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
You can also use narrow table form which as follows: (You can see part 4 about how to use narrow form)
| time | device_name | status | hardware | temperature |
|---|---|---|---|---|
| 1 | root.ln.wf02.wt01 | true | null | 2.2 |
| 1 | root.ln.wf02.wt02 | true | null | null |
| 2 | root.ln.wf02.wt01 | null | null | 2.2 |
| 2 | root.ln.wf02.wt02 | false | aaa | null |
| 3 | root.ln.wf02.wt01 | true | null | 2.1 |
| 4 | root.ln.wf02.wt02 | true | bbb | null |
| 5 | root.ln.wf02.wt01 | false | null | null |
| 6 | root.ln.wf02.wt02 | null | ccc | null |
Transform between wide and narrow table
- from wide to narrow
import org.apache.iotdb.spark.db._
val wide_df = spark.read.format("org.apache.iotdb.spark.db").option("url", "jdbc:iotdb://127.0.0.1:6667/").option("sql", "select * from root where time < 1100 and time > 1000").load
val narrow_df = Transformer.toNarrowForm(spark, wide_df)- from narrow to wide
import org.apache.iotdb.spark.db._
val wide_df = Transformer.toWideForm(spark, narrow_df)Java user guide
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.iotdb.spark.db.*;
public class Example {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Build a DataFrame from Scratch")
.master("local[*]")
.getOrCreate();
Dataset<Row> df = spark.read().format("org.apache.iotdb.spark.db")
.option("url","jdbc:iotdb://127.0.0.1:6667/")
.option("sql","select * from root").load();
df.printSchema();
df.show();
Dataset<Row> narrowTable = Transformer.toNarrowForm(spark, df);
narrowTable.show();
}
}Write Data to IoTDB
User Guide
// import narrow table
val df = spark.createDataFrame(List(
(1L, "root.test.d0",1, 1L, 1.0F, 1.0D, true, "hello"),
(2L, "root.test.d0", 2, 2L, 2.0F, 2.0D, false, "world")))
val dfWithColumn = df.withColumnRenamed("_1", "Time")
.withColumnRenamed("_2", "device_name")
.withColumnRenamed("_3", "s0")
.withColumnRenamed("_4", "s1")
.withColumnRenamed("_5", "s2")
.withColumnRenamed("_6", "s3")
.withColumnRenamed("_7", "s4")
.withColumnRenamed("_8", "s5")
dfWithColumn
.write
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.save
// import wide table
val df = spark.createDataFrame(List(
(1L, 1, 1L, 1.0F, 1.0D, true, "hello"),
(2L, 2, 2L, 2.0F, 2.0D, false, "world")))
val dfWithColumn = df.withColumnRenamed("_1", "Time")
.withColumnRenamed("_2", "root.test.d0.s0")
.withColumnRenamed("_3", "root.test.d0.s1")
.withColumnRenamed("_4", "root.test.d0.s2")
.withColumnRenamed("_5", "root.test.d0.s3")
.withColumnRenamed("_6", "root.test.d0.s4")
.withColumnRenamed("_7", "root.test.d0.s5")
dfWithColumn.write.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("numPartition", "10")
.saveNotes
- You can directly write data to IoTDB whatever the dataframe contains a wide table or a narrow table.
- The parameter
numPartitionis used to set the number of partitions. The dataframe that you want to save will be repartition based on this parameter before writing data. Each partition will open a session to write data to increase the number of concurrent requests.