1. 监控框架
当前用户可以使用多种手段对正在运行的IoTDB进程进行系统监控,包括使用 Java 的 Jconsole 工具对正在运行的 IoTDB 进程进行系统状态监控,使用 IoTDB 为用户开发的接口查看数据统计量,使用监控框架进行 IoTDB 的运行状态监控
1. 监控框架
在IoTDB运行过程中,我们希望对IoTDB的状态进行观测,以便于排查系统问题或者及时发现系统潜在的风险。能反映系统运行状态的一系列指标就是系统监控指标。
1.1. 什么场景下会使用到监控框架?
那么什么时候会用到监控框架呢?下面列举一些常见的场景。
系统变慢了
系统变慢几乎是最常见也最头疼的问题,这时候我们需要尽可能多的信息来帮助我们找到系统变慢的原因,比如:
- JVM信息:是不是有FGC?GC耗时多少?GC后内存有没有恢复?是不是有大量的线程?
- 系统信息:CPU使用率是不是太高了?磁盘IO是不是很频繁?
- 连接数:当前连接是不是太多?
- 接口:当前TPS是多少?各个接口耗时有没有变化?
- 线程池:系统中各种任务是否有积压?
- 缓存命中率
磁盘快满了
这时候我们迫切想知道最近一段时间数据文件的增长情况,看看是不是某种文件有突增。
系统运行是否正常
此时我们可能需要通过错误日志的数量、集群节点的状态等指标来判断系统是否在正常运行。
1.2. 什么人需要使用监控框架?
所有关注系统状态的人员都可以使用,包括但不限于研发、测试、运维、DBA等等
1.3. IoTDB都有哪些监控指标?
目前,IoTDB对外提供一些主要模块的metrics,并且随着新功能的开发以及系统优化或者重构,metrics也会同步添加和更新。
1.3.1. 名词解释
在进一步了解这些指标之前,我们先来看几个名词解释:
Metric Name
指标名称,比如logback_events_total表示日志事件发生的总次数。
Tag
每个指标下面可以有0到多个分类,比如logback_events_total下有一个
level的分类,用来表示特定级别下的日志数量。
1.3.2. 数据格式
IoTDB对外提供JMX和Prometheus格式的监控指标,对于JMX,可以通过org.apache.iotdb.metrics获取系统监控指标指标。
接下来我们以Prometheus格式为例对目前已有监控项进行说明。
1.3.3. IoTDB 默认指标
1.3.3.1. 接入层
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| entry_seconds_count | name="" | important | 接口累计访问次数 | entry_seconds_count{name="openSession",} 1.0 |
| entry_seconds_sum | name="" | important | 接口累计耗时(s) | entry_seconds_sum{name="openSession",} 0.024 |
| entry_seconds_max | name="" | important | 接口最大耗时(s) | entry_seconds_max{name="openSession",} 0.024 |
| quantity_total | name="pointsIn" | important | 系统累计写入点数 | quantity_total{name="pointsIn",} 1.0 |
| thrift_connections | name="" | core | thrift当前连接数 | thrift_connections{name="RPC",} 1.0 |
1.3.3.2. Task
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| queue | name="compaction_inner/compaction_cross/flush", status="running/waiting" | important | 当前时间任务数 | queue{name="flush",status="waiting",} 0.0 queue{name="compaction/flush",status="running",} 0.0 |
| cost_task_seconds_count | name="compaction/flush" | important | 任务累计发生次数 | cost_task_seconds_count{name="flush",} 1.0 |
| cost_task_seconds_max | name="compaction/flush" | important | 到目前为止任务耗时(s)最大的一次 | cost_task_seconds_max{name="flush",} 0.363 |
| cost_task_seconds_sum | name="compaction/flush" | important | 任务累计耗时(s) | cost_task_seconds_sum{name="flush",} 0.363 |
| data_written_total | name="compaction", type="aligned/not-aligned/total" | important | 合并文件时写入量 | data_written{name="compaction",type="total",} 10240 |
| data_read_total | name="compaction" | important | 合并文件时的读取量 | data_read={name="compaction",} 10240 |
1.3.3.3. 内存占用
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| mem | name="chunkMetaData/storageGroup/schemaUsage/schemaRemaining" | important | chunkMetaData 占用/storageGroup 占用/schema 占用/schema 剩余的内存(byte) | mem{name="chunkMetaData",} 2050.0 |
1.3.3.4. 缓存
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| cache_hit | name="chunk/timeSeriesMeta/bloomFilter" | important | chunk/timeSeriesMeta缓存命中率,bloomFilter拦截率 | cache_hit{name="chunk",} 80 |
1.3.3.5. 业务数据
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| quantity | name="timeSeries/storageGroup/device/deviceUsingTemplate", type="total/normal/template/template" | important | 当前时间timeSeries/storageGroup/device/激活了模板的device的数量 | quantity{name="timeSeries",type="normal"} 1.0 |
| points | sg="", type="flush" | core | 最新一个刷盘的memtale的点数 | quantity{name="memtable",type="flush"} 1.0 |
1.3.3.6. 集群
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| cluster_node_leader_count | name="" | important | 节点上dataGroupLeader的数量,用来观察leader是否分布均匀 | cluster_node_leader_count{name="127.0.0.1",} 2.0 |
| cluster_uncommitted_log | name="" | important | 节点uncommitted_log的数量 | cluster_uncommitted_log{name="127.0.0.1_Data-127.0.0.1-40010-raftId-0",} 0.0 |
| cluster_node_status | name="" | important | 节点状态,1=online 2=offline | cluster_node_status{name="127.0.0.1",} 1.0 |
| cluster_elect_total | name="",status="fail/win" | important | 节点参与选举的次数及结果 | cluster_elect_total{name="127.0.0.1",status="win",} 1.0 |
1.3.4. IoTDB 预定义指标集
用户可以在iotdb-metric.yml文件中,修改predefinedMetrics的值来启用预定义指标集,目前有JVM、LOGBACK、FILE、PROCESS、SYSYTEM这五种。
1.3.4.1. JVM
1.3.4.1.1. 线程
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| jvm_threads_live_threads | 无 | important | 当前线程数 | jvm_threads_live_threads 25.0 |
| jvm_threads_daemon_threads | 无 | important | 当前daemon线程数 | jvm_threads_daemon_threads 12.0 |
| jvm_threads_peak_threads | 无 | important | 峰值线程数 | jvm_threads_peak_threads 28.0 |
| jvm_threads_states_threads | state="runnable/blocked/waiting/timed-waiting/new/terminated" | important | 当前处于各种状态的线程数 | jvm_threads_states_threads{state="runnable",} 10.0 |
1.3.4.1.2. 垃圾回收
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| jvm_gc_pause_seconds_count | action="end of major GC/end of minor GC",cause="xxxx" | important | YGC/FGC发生次数及其原因 | jvm_gc_pause_seconds_count{action="end of major GC",cause="Metadata GC Threshold",} 1.0 |
| jvm_gc_pause_seconds_sum | action="end of major GC/end of minor GC",cause="xxxx" | important | YGC/FGC累计耗时及其原因 | jvm_gc_pause_seconds_sum{action="end of major GC",cause="Metadata GC Threshold",} 0.03 |
| jvm_gc_pause_seconds_max | action="end of major GC",cause="Metadata GC Threshold" | important | YGC/FGC最大耗时及其原因 | jvm_gc_pause_seconds_max{action="end of major GC",cause="Metadata GC Threshold",} 0.0 |
| jvm_gc_memory_promoted_bytes_total | 无 | important | 从GC之前到GC之后老年代内存池大小正增长的累计 | jvm_gc_memory_promoted_bytes_total 8425512.0 |
| jvm_gc_max_data_size_bytes | 无 | important | 老年代内存的历史最大值 | jvm_gc_max_data_size_bytes 2.863661056E9 |
| jvm_gc_live_data_size_bytes | 无 | important | GC后老年代内存的大小 | jvm_gc_live_data_size_bytes 8450088.0 |
| jvm_gc_memory_allocated_bytes_total | 无 | important | 在一个GC之后到下一个GC之前年轻代增加的内存 | jvm_gc_memory_allocated_bytes_total 4.2979144E7 |
1.3.4.1.3. 内存
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| jvm_buffer_memory_used_bytes | id="direct/mapped" | important | 已经使用的缓冲区大小 | jvm_buffer_memory_used_bytes{id="direct",} 3.46728099E8 |
| jvm_buffer_total_capacity_bytes | id="direct/mapped" | important | 最大缓冲区大小 | jvm_buffer_total_capacity_bytes{id="mapped",} 0.0 |
| jvm_buffer_count_buffers | id="direct/mapped" | important | 当前缓冲区数量 | jvm_buffer_count_buffers{id="direct",} 183.0 |
| jvm_memory_committed_bytes | {area="heap/nonheap",id="xxx",} | important | 当前向JVM申请的内存大小 | jvm_memory_committed_bytes{area="heap",id="Par Survivor Space",} 2.44252672E8 jvm_memory_committed_bytes{area="nonheap",id="Metaspace",} 3.9051264E7 |
| jvm_memory_max_bytes | {area="heap/nonheap",id="xxx",} | important | JVM最大内存 | jvm_memory_max_bytes{area="heap",id="Par Survivor Space",} 2.44252672E8 jvm_memory_max_bytes{area="nonheap",id="Compressed Class Space",} 1.073741824E9 |
| jvm_memory_used_bytes | {area="heap/nonheap",id="xxx",} | important | JVM已使用内存大小 | jvm_memory_used_bytes{area="heap",id="Par Eden Space",} 1.000128376E9 jvm_memory_used_bytes{area="nonheap",id="Code Cache",} 2.9783808E7 |
1.3.4.1.4. Classes
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| jvm_classes_unloaded_classes_total | 无 | important | jvm累计卸载的class数量 | jvm_classes_unloaded_classes_total 680.0 |
| jvm_classes_loaded_classes | 无 | important | jvm累计加载的class数量 | jvm_classes_loaded_classes 5975.0 |
| jvm_compilation_time_ms_total | {compiler="HotSpot 64-Bit Tiered Compilers",} | important | jvm耗费在编译上的时间 | jvm_compilation_time_ms_total{compiler="HotSpot 64-Bit Tiered Compilers",} 107092.0 |
1.3.4.2. 文件(File)
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| file_size | name="wal/seq/unseq" | important | 当前时间wal/seq/unseq文件大小(byte) | file_size{name="wal",} 67.0 |
| file_count | name="wal/seq/unseq" | important | 当前时间wal/seq/unseq文件个数 | file_count{name="seq",} 1.0 |
1.3.4.3. 日志(logback)
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| logback_events_total | {level="trace/debug/info/warn/error",} | important | trace/debug/info/warn/error日志累计数量 | logback_events_total{level="warn",} 0.0 |
1.3.4.3.1. 进程(Process)
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| process_cpu_load | name="cpu" | core | process当前CPU占用率(%) | process_cpu_load{name="process",} 5.0 |
| process_cpu_time | name="cpu" | core | process累计占用CPU时间(ns) | process_cpu_time{name="process",} 3.265625E9 |
| process_max_mem | name="memory" | core | JVM最大可用内存 | process_max_mem{name="process",} 3.545759744E9 |
| process_used_mem | name="memory" | core | JVM当前使用内存 | process_used_mem{name="process",} 4.6065456E7 |
| process_total_mem | name="memory" | core | JVM当前已申请内存 | process_total_mem{name="process",} 2.39599616E8 |
| process_free_mem | name="memory" | core | JVM当前剩余可用内存 | process_free_mem{name="process",} 1.94035584E8 |
| process_mem_ratio | name="memory" | core | 进程的内存占用比例 | process_mem_ratio{name="process",} 0.0 |
| process_threads_count | name="process" | core | 当前线程数 | process_threads_count{name="process",} 11.0 |
| process_status | name="process" | core | 进程存活状态,1.0为存活,0.0为终止 | process_status{name="process",} 1.0 |
1.3.4.5. 系统(System)
| Metric | Tag | level | 说明 | 示例 |
|---|---|---|---|---|
| sys_cpu_load | name="cpu" | core | system当前CPU占用率(%) | sys_cpu_load{name="system",} 15.0 |
| sys_cpu_cores | name="cpu" | core | jvm可用处理器数 | sys_cpu_cores{name="system",} 16.0 |
| sys_total_physical_memory_size | name="memory" | core | system最大物理内存 | sys_total_physical_memory_size{name="system",} 1.5950999552E10 |
| sys_free_physical_memory_size | name="memory" | core | system当前剩余可用内存 | sys_free_physical_memory_size{name="system",} 4.532396032E9 |
| sys_total_swap_space_size | name="memory" | core | system交换区最大空间 | sys_total_swap_space_size{name="system",} 2.1051273216E10 |
| sys_free_swap_space_size | name="memory" | core | system交换区剩余可用空间 | sys_free_swap_space_size{name="system",} 2.931576832E9 |
| sys_committed_vm_size | name="memory" | important | system保证可用于正在运行的进程的虚拟内存量 | sys_committed_vm_size{name="system",} 5.04344576E8 |
| sys_disk_total_space | name="disk" | core | 磁盘总大小 | sys_disk_total_space{name="system",} 5.10770798592E11 |
| sys_disk_free_space | name="disk" | core | 磁盘可用大小 | sys_disk_free_space{name="system",} 3.63467845632E11 |
1.3.5. 自定义添加埋点
- 如果想自己在IoTDB中添加更多系统监控指标埋点,可以参考IoTDB Metrics Framework使用说明
- Metric 埋点定义规则
Metric:监控项的名称,比如entry_seconds_count为接口累计访问次数,file_size 为文件总数。Tags:Key-Value对,用来明确被监控项,可选项name = xxx:被监控项的名称,比如对entry_seconds_count这个监控项,name 的含义是被监控的接口名称。status = xxx:被监控项的状态细分,比如监控 Task 的监控项可以通过该参数,将运行的 Task 和停止的 Task 分开。user = xxx:被监控项和某个特定用户相关,比如统计root用户的写入总次数。- 根据具体情况自定义......
- 监控指标级别含义:
- 线上运行默认启动级别为
Important级,线下调试默认启动级别为Normal级,审核严格程度Core > Important > Normal > All Core:系统的核心指标,供运维人员使用,关乎系统的性能、稳定性、安全性,比如实例的状况,系统的负载等。Important:模块的重要指标,供运维和测试人员使用,直接关乎每个模块的运行状态,比如合并文件个数、执行情况等。Normal:模块的一般指标,供开发人员使用,方便在出现问题时定位模块,比如合并中的特定关键操作情况。All:模块的全部指标,供模块开发人员使用,往往在复现问题的时候使用,从而快速解决问题。
- 线上运行默认启动级别为
1.4. 怎样获取这些系统监控指标?
metric采集默认是关闭的,需要先到conf/iotdb-metric.yml中打开后启动server,目前也支持启动后,通过load configuration热加载。
1.4.1. 配置文件
# 是否启动监控模块,默认为false
enableMetric: false
# 是否启用操作延迟统计
enablePerformanceStat: false
# 数据提供方式,对外部通过jmx和prometheus协议提供metrics的数据, 可选参数:[JMX, PROMETHEUS, IOTDB],IOTDB是默认关闭的。
metricReporterList:
- JMX
- PROMETHEUS
# 底层使用的metric架构,可选参数:[MICROMETER, DROPWIZARD]
monitorType: MICROMETER
# 初始化metric的级别,可选参数: [CORE, IMPORTANT, NORMAL, ALL]
metricLevel: IMPORTANT
# 预定义的指标集, 可选参数: [JVM, LOGBACK, FILE, PROCESS, SYSTEM]
predefinedMetrics:
- JVM
- FILE
# Prometheus Reporter 使用的端口
prometheusExporterPort: 9091
# 是否将预设置的监控指标写回 IoTDB
isStoreToLocal: false
# IoTDB Reporter相关的配置
ioTDBReporterConfig:
host: 127.0.0.1
port: 6667
username: root
password: root
database: _metric
pushPeriodInSecond: 15然后按照下面的操作获取监控指标数据
- 打开配置文件中的metric开关
- 其他参数使用默认配置即可
- 启动IoTDB
- 打开浏览器或者用
curl访问http://servier_ip:9091/metrics, 就能看到metric数据了:
...
# HELP file_count
# TYPE file_count gauge
file_count{name="wal",} 0.0
file_count{name="unseq",} 0.0
file_count{name="seq",} 2.0
# HELP file_size
# TYPE file_size gauge
file_size{name="wal",} 0.0
file_size{name="unseq",} 0.0
file_size{name="seq",} 560.0
# HELP queue
# TYPE queue gauge
queue{name="flush",status="waiting",} 0.0
queue{name="flush",status="running",} 0.0
# HELP quantity
# TYPE quantity gauge
quantity{name="timeSeries",} 1.0
quantity{name="storageGroup",} 1.0
quantity{name="device",} 1.0
# HELP logback_events_total Number of error level events that made it to the logs
# TYPE logback_events_total counter
logback_events_total{level="warn",} 0.0
logback_events_total{level="debug",} 2760.0
logback_events_total{level="error",} 0.0
logback_events_total{level="trace",} 0.0
logback_events_total{level="info",} 71.0
# HELP mem
# TYPE mem gauge
mem{name="storageGroup",} 0.0
mem{name="mtree",} 1328.0
...1.4.2. 对接Prometheus和Grafana
如上面所述,IoTDB对外暴露出标准Prometheus格式的监控指标数据,可以直接和Prometheus以及Grafana集成。
IoTDB、Prometheus、Grafana三者的关系如下图所示:

- IoTDB在运行过程中持续收集监控指标数据。
- Prometheus以固定的间隔(可配置)从IoTDB的HTTP接口拉取监控指标数据。
- Prometheus将拉取到的监控指标数据存储到自己的TSDB中。
- Grafana以固定的间隔(可配置)从Prometheus查询监控指标数据并绘图展示。
从交互流程可以看出,我们需要做一些额外的工作来部署和配置Prometheus和Grafana。
比如,你可以对Prometheus进行如下的配置(部分参数可以自行调整)来从IoTDB获取监控数据
job_name: pull-metrics
honor_labels: true
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
follow_redirects: true
static_configs:
- targets:
- localhost:9091更多细节可以参考下面的文档:
Prometheus从HTTP接口拉取metrics数据的配置说明
1.4.3. Apache IoTDB Dashboard
我们提供了Apache IoTDB Dashboard,在Grafana中显示的效果图如下所示:

Apache IoTDB Dashboard的获取方式:
方式一: 您可以在grafana-metrics-example文件夹下获取到对应不同iotdb版本的Dashboard的json文件。
方式二: 您可以访问Grafana Dashboard官网,点击下载 Apache IoTDB Dashboard。
在创建Grafana时,您可以选择Import刚刚下载的json文件,并为Apache IoTDB Dashboard选择对应目标数据源。
2. 系统状态监控
进入 Jconsole 监控页面后,首先看到的是 IoTDB 各类运行情况的概览。在这里,您可以看到堆内存信息、线程信息、类信息以及服务器的 CPU 使用情况。
3. JMX MBean 监控
通过使用 JConsole 工具并与 JMX 连接,您可以查看一些系统统计信息和参数。
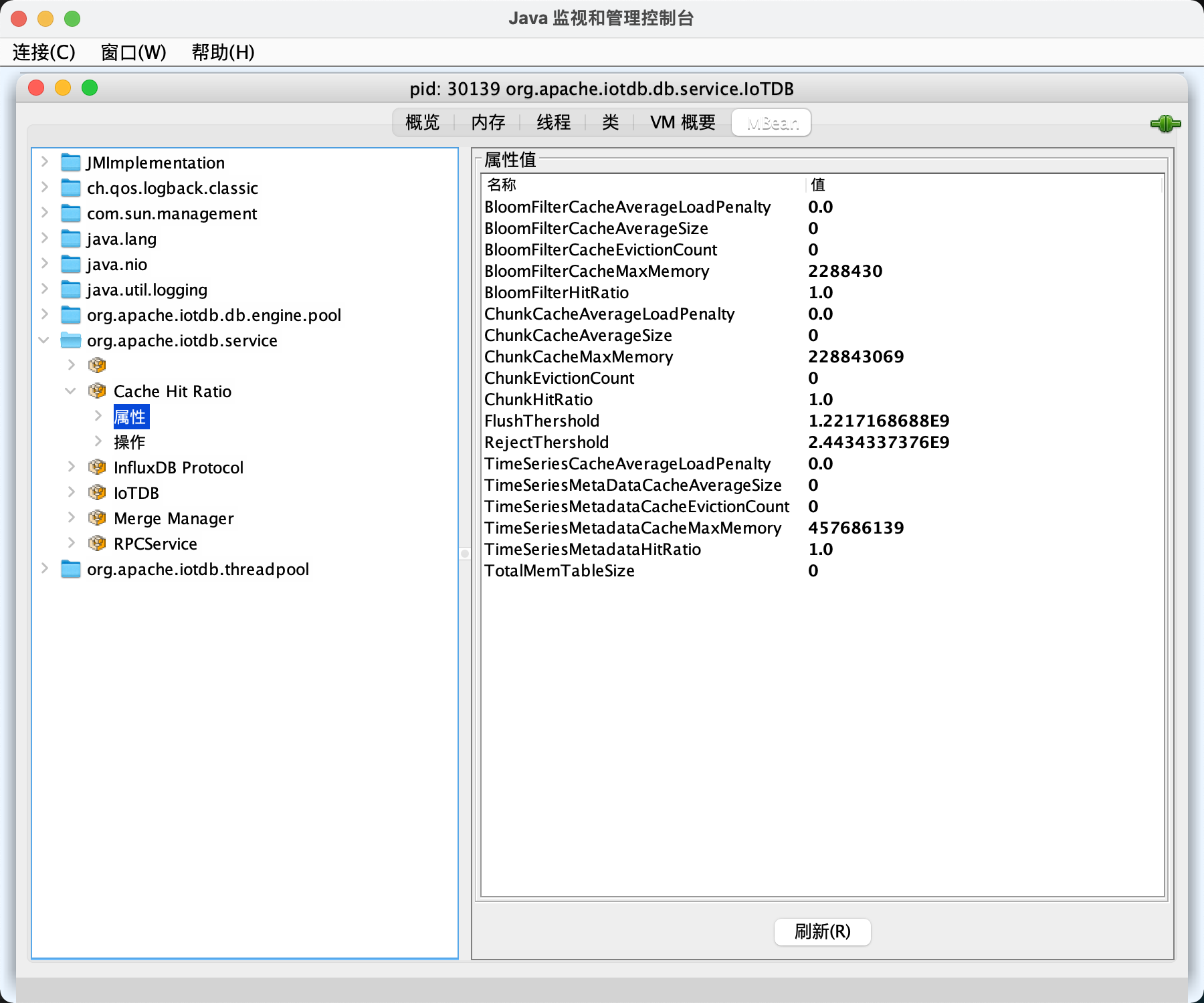
本节描述如何使用 JConsole 的 "Mbean" 选项卡来监视 IoTDB 的一些系统配置、写入数据统计等等。 连接到 JMX 后,您可以通过 "MBeans" 标签找到名为 "org.apache.iotdb.service" 的 "MBean",如下图所示。
4. 性能监控
4.1. 介绍
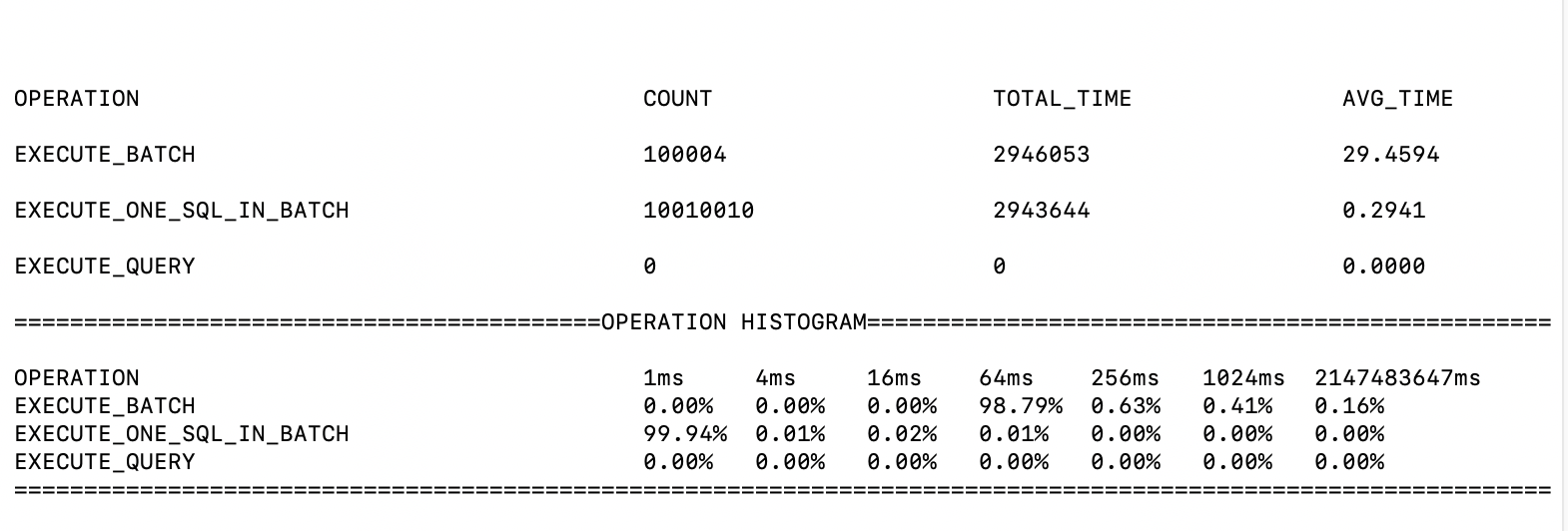
性能监控模块用来监控 IOTDB 每一个操作的耗时,以便用户更好的了解数据库的整体性能。此模块会统计每一种操作的平均耗时,以及耗时在一定时间区间内(1ms,4ms,16ms,64ms,256ms,1024ms,以上)的操作的比例。输出文件在 log_measure.log 中。输出样例如下:
4.2. 配置参数
配置文件位置:conf/iotdb-datanode.properties
表 -配置参数以及描述项
| 参数 | 默认值 | 描述 |
|---|---|---|
| enable_performance_stat | false | 是否开启性能监控模块 |
5. Cache 命中率统计
为了提高查询性能,IOTDB 对 ChunkMetaData 和 TsFileMetaData 进行了缓存。用户可以通过 debug 级别的日志以及 MXBean 两种方式来查看缓存的命中率,并根据缓存命中率以及系统内存来调节缓存所使用的内存大小。使用 MXBean 查看缓存命中率的方法为:
- 通过端口 31999 连接 jconsole,并在上方菜单项中选择‘MBean’.
- 展开侧边框并选择 'org.apache.iotdb.db.service'. 将会得到如下图所示结果:
