User Defined Function (UDF)
User Defined Function (UDF)
IoTDB provides a variety of built-in functions to meet your computing needs, and you can also create user defined functions to meet more computing needs.
This document describes how to write, register and use a UDF.
UDF Types
In IoTDB, you can expand two types of UDF:
| UDF Class | Description |
|---|---|
| UDTF(User Defined Timeseries Generating Function) | This type of function can take multiple time series as input, and output one time series, which can have any number of data points. |
| UDAF(User Defined Aggregation Function) | Under development, please stay tuned. |
UDF Development Dependencies
If you use Maven, you can search for the development dependencies listed below from the Maven repository . Please note that you must select the same dependency version as the target IoTDB server version for development.
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>iotdb-server</artifactId>
<version>0.13.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>UDTF(User Defined Timeseries Generating Function)
To write a UDTF, you need to inherit the org.apache.iotdb.db.query.udf.api.UDTF class, and at least implement the beforeStart method and a transform method.
The following table shows all the interfaces available for user implementation.
| Interface definition | Description | Required to Implement |
|---|---|---|
void validate(UDFParameterValidator validator) throws Exception | This method is mainly used to validate UDFParameters and it is executed before beforeStart(UDFParameters, UDTFConfigurations) is called. | Optional |
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception | The initialization method to call the user-defined initialization behavior before a UDTF processes the input data. Every time a user executes a UDTF query, the framework will construct a new UDF instance, and beforeStart will be called. | Required |
void transform(Row row, PointCollector collector) throws Exception | This method is called by the framework. This data processing method will be called when you choose to use the RowByRowAccessStrategy strategy (set in beforeStart) to consume raw data. Input data is passed in by Row, and the transformation result should be output by PointCollector. You need to call the data collection method provided by collector to determine the output data. | Required to implement at least one transform method |
void transform(RowWindow rowWindow, PointCollector collector) throws Exception | This method is called by the framework. This data processing method will be called when you choose to use the SlidingSizeWindowAccessStrategy or SlidingTimeWindowAccessStrategy strategy (set in beforeStart) to consume raw data. Input data is passed in by RowWindow, and the transformation result should be output by PointCollector. You need to call the data collection method provided by collector to determine the output data. | Required to implement at least one transform method |
void terminate(PointCollector collector) throws Exception | This method is called by the framework. This method will be called once after all transform calls have been executed. In a single UDF query, this method will and will only be called once. You need to call the data collection method provided by collector to determine the output data. | Optional |
void beforeDestroy() | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
In the life cycle of a UDTF instance, the calling sequence of each method is as follows:
void validate(UDFParameterValidator validator) throws Exceptionvoid beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exceptionvoid transform(Row row, PointCollector collector) throws Exceptionorvoid transform(RowWindow rowWindow, PointCollector collector) throws Exceptionvoid terminate(PointCollector collector) throws Exceptionvoid beforeDestroy()
Note that every time the framework executes a UDTF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDTF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDTF without considering the influence of concurrency and other factors.
The usage of each interface will be described in detail below.
void validate(UDFParameterValidator validator) throws Exception
The validate method is used to validate the parameters entered by the user.
In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
Please refer to the Javadoc for the usage of UDFParameterValidator.
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception
This method is mainly used to customize UDTF. In this method, the user can do the following things:
- Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
- Set the strategy to access the raw data and set the output data type in UDTFConfigurations.
- Create resources, such as establishing external connections, opening files, etc.
UDFParameters
UDFParameters is used to parse UDF parameters in SQL statements (the part in parentheses after the UDF function name in SQL). The input parameters have two parts. The first part is the paths (measurements) and their data types of the time series that the UDF needs to process, and the second part is the key-value pair attributes for customization. Only the second part can be empty.
Example:
SELECT UDF(s1, s2, 'key1'='iotdb', 'key2'='123.45') FROM root.sg.d;Usage:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
for (PartialPath path : parameters.getPaths()) {
TSDataType dataType = parameters.getDataType(path);
// do something
}
String stringValue = parameters.getString("key1"); // iotdb
Float floatValue = parameters.getFloat("key2"); // 123.45
Double doubleValue = parameters.getDouble("key3"); // null
int intValue = parameters.getIntOrDefault("key4", 678); // 678
// do something
// configurations
// ...
}UDTFConfigurations
You must use UDTFConfigurations to specify the strategy used by UDF to access raw data and the type of output sequence.
Usage:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
// ...
// configurations
configurations
.setAccessStrategy(new RowByRowAccessStrategy())
.setOutputDataType(TSDataType.INT32);
}The setAccessStrategy method is used to set the UDF's strategy for accessing the raw data, and the setOutputDataType method is used to set the data type of the output sequence.
setAccessStrategy
Note that the raw data access strategy you set here determines which transform method the framework will call. Please implement the transform method corresponding to the raw data access strategy. Of course, you can also dynamically decide which strategy to set based on the attribute parameters parsed by UDFParameters. Therefore, two transform methods are also allowed to be implemented in one UDF.
The following are the strategies you can set:
| Interface definition | Description | The transform Method to Call |
|---|---|---|
RowByRowAccessStrategy | Process raw data row by row. The framework calls the transform method once for each row of raw data input. When UDF has only one input sequence, a row of input is one data point in the input sequence. When UDF has multiple input sequences, one row of input is a result record of the raw query (aligned by time) on these input sequences. (In a row, there may be a column with a value of null, but not all of them are null) | void transform(Row row, PointCollector collector) throws Exception |
SlidingTimeWindowAccessStrategy | Process a batch of data in a fixed time interval each time. We call the container of a data batch a window. The framework calls the transform method once for each raw data input window. There may be multiple rows of data in a window, and each row is a result record of the raw query (aligned by time) on these input sequences. (In a row, there may be a column with a value of null, but not all of them are null) | void transform(RowWindow rowWindow, PointCollector collector) throws Exception |
SlidingSizeWindowAccessStrategy | The raw data is processed batch by batch, and each batch contains a fixed number of raw data rows (except the last batch). We call the container of a data batch a window. The framework calls the transform method once for each raw data input window. There may be multiple rows of data in a window, and each row is a result record of the raw query (aligned by time) on these input sequences. (In a row, there may be a column with a value of null, but not all of them are null) | void transform(RowWindow rowWindow, PointCollector collector) throws Exception |
RowByRowAccessStrategy: The construction of RowByRowAccessStrategy does not require any parameters.
SlidingTimeWindowAccessStrategy: SlidingTimeWindowAccessStrategy has many constructors, you can pass 3 types of parameters to them:
- Parameter 1: The display window on the time axis
- Parameter 2: Time interval for dividing the time axis (should be positive)
- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
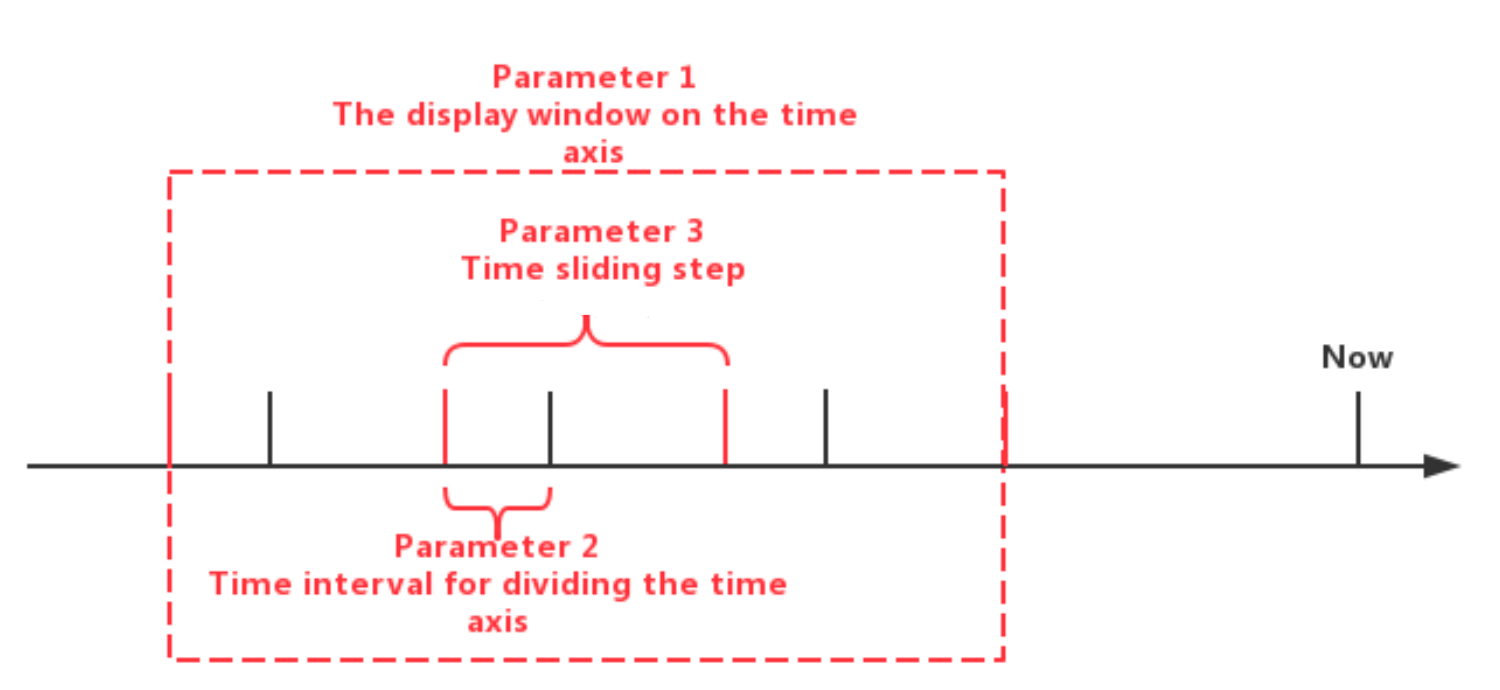
Note that the actual time interval of some of the last time windows may be less than the specified time interval parameter. In addition, there may be cases where the number of data rows in some time windows is 0. In these cases, the framework will also call the transform method for the empty windows.
SlidingSizeWindowAccessStrategy: SlidingSizeWindowAccessStrategy has many constructors, you can pass 2 types of parameters to them:
- Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
- Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
Please see the Javadoc for more details.
setOutputDataType
Note that the type of output sequence you set here determines the type of data that the PointCollector can actually receive in the transform method. The relationship between the output data type set in setOutputDataType and the actual data output type that PointCollector can receive is as follows:
Output Data Type Set in setOutputDataType | Data Type that PointCollector Can Receive |
|---|---|
INT32 | int |
INT64 | long |
FLOAT | float |
DOUBLE | double |
BOOLEAN | boolean |
TEXT | java.lang.String and org.apache.iotdb.tsfile.utils.Binary |
The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
Here is a simple example:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// do something
// ...
configurations
.setAccessStrategy(new RowByRowAccessStrategy())
.setOutputDataType(parameters.getDataType(0));
}void transform(Row row, PointCollector collector) throws Exception
You need to implement this method when you specify the strategy of UDF to read the original data as RowByRowAccessStrategy.
This method processes the raw data one row at a time. The raw data is input from Row and output by PointCollector. You can output any number of data points in one transform method call. It should be noted that the type of output data points must be the same as you set in the beforeStart method, and the timestamps of output data points must be strictly monotonically increasing.
The following is a complete UDF example that implements the void transform(Row row, PointCollector collector) throws Exception method. It is an adder that receives two columns of time series as input. When two data points in a row are not null, this UDF will output the algebraic sum of these two data points.
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.Row;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Adder implements UDTF {
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT64)
.setAccessStrategy(new RowByRowAccessStrategy());
}
@Override
public void transform(Row row, PointCollector collector) throws Exception {
if (row.isNull(0) || row.isNull(1)) {
return;
}
collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
}
}void transform(RowWindow rowWindow, PointCollector collector) throws Exception
You need to implement this method when you specify the strategy of UDF to read the original data as SlidingTimeWindowAccessStrategy or SlidingSizeWindowAccessStrategy.
This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from RowWindow and output by PointCollector. RowWindow can help you access a batch of Row, it provides a set of interfaces for random access and iterative access to this batch of Row. You can output any number of data points in one transform method call. It should be noted that the type of output data points must be the same as you set in the beforeStart method, and the timestamps of output data points must be strictly monotonically increasing.
Below is a complete UDF example that implements the void transform(RowWindow rowWindow, PointCollector collector) throws Exception method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
import java.io.IOException;
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.RowWindow;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Counter implements UDTF {
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT32)
.setAccessStrategy(new SlidingTimeWindowAccessStrategy(
parameters.getLong("time_interval"),
parameters.getLong("sliding_step"),
parameters.getLong("display_window_begin"),
parameters.getLong("display_window_end")));
}
@Override
public void transform(RowWindow rowWindow, PointCollector collector) {
if (rowWindow.windowSize() != 0) {
collector.putInt(rowWindow.getRow(0).getTime(), rowWindow.windowSize());
}
}
}void terminate(PointCollector collector) throws Exception
In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The terminate interface provides support for those scenarios.
This method is called after all transform calls are executed and before the beforeDestory method is executed. You can implement the transform method to perform pure data processing (without outputting any data points), and implement the terminate method to output the processing results.
The processing results need to be output by the PointCollector. You can output any number of data points in one terminate method call. It should be noted that the type of output data points must be the same as you set in the beforeStart method, and the timestamps of output data points must be strictly monotonically increasing.
Below is a complete UDF example that implements the void terminate(PointCollector collector) throws Exception method. It takes one time series whose data type is INT32 as input, and outputs the maximum value point of the series.
import java.io.IOException;
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.Row;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Max implements UDTF {
private Long time;
private int value;
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT32)
.setAccessStrategy(new RowByRowAccessStrategy());
}
@Override
public void transform(Row row, PointCollector collector) {
int candidateValue = row.getInt(0);
if (time == null || value < candidateValue) {
time = row.getTime();
value = candidateValue;
}
}
@Override
public void terminate(PointCollector collector) throws IOException {
if (time != null) {
collector.putInt(time, value);
}
}
}void beforeDestroy()
The method for terminating a UDF.
This method is called by the framework. For a UDF instance, beforeDestroy will be called after the last record is processed. In the entire life cycle of the instance, beforeDestroy will only be called once.
Maven Project Example
If you use Maven, you can build your own UDF project referring to our udf-example module. You can find the project here.
UDF Registration
The process of registering a UDF in IoTDB is as follows:
Implement a complete UDF class, assuming the full class name of this class is
org.apache.iotdb.udf.ExampleUDTF.Package your project into a JAR. If you use Maven to manage your project, you can refer to the Maven project example above.
Place the JAR package in the directory
iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udfor in a subdirectory ofiotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf.
**Note that when deploying a cluster, you need to ensure that there is a corresponding JAR package in the UDF JAR package path of each node. **You can specify the root path for the UDF to load the Jar by modifying the 'udf_root_dir' in the configuration file.
Register the UDF with the SQL statement, assuming that the name given to the UDF is
example.
The following shows the SQL syntax of how to register a UDF.
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME>Here is an example:
CREATE FUNCTION example AS 'org.apache.iotdb.udf.ExampleUDTF'Since UDF instances are dynamically loaded through reflection technology, you do not need to restart the server during the UDF registration process.
Note: UDF function names are not case sensitive.
Note: Please ensure that the function name given to the UDF is different from all built-in function names. A UDF with the same name as a built-in function cannot be registered.
Note: We recommend that you do not use classes that have the same class name but different function logic in different JAR packages. For example, in UDF(UDAF/UDTF): udf1, udf2, the JAR package of udf1 is udf1.jar and the JAR package of udf2 is udf2.jar. Assume that both JAR packages contain the org.apache.iotdb.udf.ExampleUDTF class. If you use two UDFs in the same SQL statement at the same time, the system will randomly load either of them and may cause inconsistency in UDF execution behavior.
UDF Deregistration
The following shows the SQL syntax of how to deregister a UDF.
DROP FUNCTION <UDF-NAME>Here is an example:
DROP FUNCTION exampleUDF Queries
The usage of UDF is similar to that of built-in aggregation functions.
Basic SQL syntax support
- Support
SLIMIT/SOFFSET - Support
LIMIT/OFFSET - Support
NON ALIGN - Support queries with time filters
- Support queries with value filters
Queries with Aligned Timeseries
Aligned Timeseries has not been supported in UDF queries yet. An error message is expected if you use UDF functions with Aligned Timeseries selected.
Queries with * in SELECT Clauses
Assume that there are 2 time series (root.sg.d1.s1 and root.sg.d1.s2) in the system.
SELECT example(*) from root.sg.d1
Then the result set will include the results of example (root.sg.d1.s1) and example (root.sg.d1.s2).
SELECT example(s1, *) from root.sg.d1
Then the result set will include the results of example(root.sg.d1.s1, root.sg.d1.s1) and example(root.sg.d1.s1, root.sg.d1.s2).
SELECT example(*, *) from root.sg.d1
Then the result set will include the results of example(root.sg.d1.s1, root.sg.d1.s1), example(root.sg.d1.s2, root.sg.d1.s1), example(root.sg.d1.s1, root.sg.d1.s2) and example(root.sg.d1.s2, root.sg.d1.s2).
Queries with Key-value Attributes in UDF Parameters
You can pass any number of key-value pair parameters to the UDF when constructing a UDF query. The key and value in the key-value pair need to be enclosed in single or double quotes. Note that key-value pair parameters can only be passed in after all time series have been passed in. Here is a set of examples:
SELECT example(s1, 'key1'='value1', 'key2'='value2'), example(*, 'key3'='value3') FROM root.sg.d1;
SELECT example(s1, s2, 'key1'='value1', 'key2'='value2') FROM root.sg.d1;Nested Queries
SELECT s1, s2, example(s1, s2) FROM root.sg.d1;
SELECT *, example(*) FROM root.sg.d1 DISABLE ALIGN;
SELECT s1 * example(* / s1 + s2) FROM root.sg.d1;
SELECT s1, s2, s1 + example(s1, s2), s1 - example(s1 + example(s1, s2) / s2) FROM root.sg.d1;Show All Registered UDFs
SHOW FUNCTIONSUser Permission Management
There are 3 types of user permissions related to UDF:
CREATE_FUNCTION: Only users with this permission are allowed to register UDFsDROP_FUNCTION: Only users with this permission are allowed to deregister UDFsREAD_TIMESERIES: Only users with this permission are allowed to use UDFs for queries
For more user permissions related content, please refer to Account Management Statements.
Configurable Properties
When querying by a UDF, IoTDB may prompt that there is insufficient memory. You can resolve the issue by configuring udf_initial_byte_array_length_for_memory_control, udf_memory_budget_in_mb and udf_reader_transformer_collector_memory_proportion in iotdb-engine.properties and restarting the server.
Contribute UDF
This part mainly introduces how external users can contribute their own UDFs to the IoTDB community.
Prerequisites
UDFs must be universal.
The "universal" mentioned here refers to: UDFs can be widely used in some scenarios. In other words, the UDF function must have reuse value and may be directly used by other users in the community.
If you are not sure whether the UDF you want to contribute is universal, you can send an email to
dev@iotdb.apache.orgor create an issue to initiate a discussion.The UDF you are going to contribute has been well tested and can run normally in the production environment.
What you need to prepare
- UDF source code
- Test cases
- Instructions
UDF Source Code
- Create the UDF main class and related classes in
src/main/java/org/apache/iotdb/db/query/udf/builtinor in its subfolders. - Register your UDF in
src/main/java/org/apache/iotdb/db/query/udf/builtin/BuiltinFunction.java.
Test Cases
At a minimum, you need to write integration tests for the UDF.
You can add a test class in server/src/test/java/org/apache/iotdb/db/integration.
Instructions
The instructions need to include: the name and the function of the UDF, the attribute parameters that must be provided when the UDF is executed, the applicable scenarios, and the usage examples, etc.
The instructions should be added in docs/UserGuide/Operation Manual/DML Data Manipulation Language.md.
Submit a PR
When you have prepared the UDF source code, test cases, and instructions, you are ready to submit a Pull Request (PR) on Github. You can refer to our code contribution guide to submit a PR: Pull Request Guide.
Known Implementation UDF Libraries
- IoTDB-Quality, a UDF library about data quality, including data profiling, data quality evalution and data repairing, etc.
Q&A
Q1: How to modify the registered UDF?
A1: Assume that the name of the UDF is example and the full class name is org.apache.iotdb.udf.ExampleUDTF, which is introduced by example.jar.
- Unload the registered function by executing
DROP FUNCTION example. - Delete
example.jarunderiotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf. - Modify the logic in
org.apache.iotdb.udf.ExampleUDTFand repackage it. The name of the JAR package can still beexample.jar. - Upload the new JAR package to
iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf. - Load the new UDF by executing
CREATE FUNCTION example AS "org.apache.iotdb.udf.ExampleUDTF".