数据处理
数据处理
用户定义函数 (UDF)
UDF(User Defined Function)即用户自定义函数。IoTDB 提供多种内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足更多的计算需求。
根据此文档,您将会很快学会 UDF 的编写、注册、使用等操作。
UDF 类型
IoTDB 支持两种类型的 UDF 函数,如下表所示。
| UDF 分类 | 描述 |
|---|---|
| UDTF(User Defined Timeseries Generating Function) | 自定义时间序列生成函数。该类函数允许接收多条时间序列,最终会输出一条时间序列,生成的时间序列可以有任意多数量的数据点。 |
| UDAF(User Defined Aggregation Function) | 正在开发,敬请期待。 |
UDF 依赖
如果您使用 Maven,可以从 Maven 库 中搜索下面示例中的依赖。请注意选择和目标 IoTDB 服务器版本相同的依赖版本。
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>iotdb-server</artifactId>
<version>0.13.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>UDTF(User Defined Timeseries Generating Function)
编写一个 UDTF 需要继承org.apache.iotdb.db.query.udf.api.UDTF类,并至少实现beforeStart方法和一种transform方法。
下表是所有可供用户实现的接口说明。
| 接口定义 | 描述 | 是否必须 |
|---|---|---|
void validate(UDFParameterValidator validator) throws Exception | 在初始化方法beforeStart调用前执行,用于检测UDFParameters中用户输入的参数是否合法。 | 否 |
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception | 初始化方法,在 UDTF 处理输入数据前,调用用户自定义的初始化行为。用户每执行一次 UDTF 查询,框架就会构造一个新的 UDF 类实例,该方法在每个 UDF 类实例被初始化时调用一次。在每一个 UDF 类实例的生命周期内,该方法只会被调用一次。 | 是 |
void transform(Row row, PointCollector collector) throws Exception | 这个方法由框架调用。当您在beforeStart中选择以RowByRowAccessStrategy的策略消费原始数据时,这个数据处理方法就会被调用。输入参数以Row的形式传入,输出结果通过PointCollector输出。您需要在该方法内自行调用collector提供的数据收集方法,以决定最终的输出数据。 | 与下面的方法二选一 |
void transform(RowWindow rowWindow, PointCollector collector) throws Exception | 这个方法由框架调用。当您在beforeStart中选择以SlidingSizeWindowAccessStrategy或者SlidingTimeWindowAccessStrategy的策略消费原始数据时,这个数据处理方法就会被调用。输入参数以RowWindow的形式传入,输出结果通过PointCollector输出。您需要在该方法内自行调用collector提供的数据收集方法,以决定最终的输出数据。 | 与上面的方法二选一 |
void terminate(PointCollector collector) throws Exception | 这个方法由框架调用。该方法会在所有的transform调用执行完成后,在beforeDestory方法执行前被调用。在一个 UDF 查询过程中,该方法会且只会调用一次。您需要在该方法内自行调用collector提供的数据收集方法,以决定最终的输出数据。 | 否 |
void beforeDestroy() | UDTF 的结束方法。此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后被调用。 | 否 |
在一个完整的 UDTF 实例生命周期中,各个方法的调用顺序如下:
void validate(UDFParameterValidator validator) throws Exceptionvoid beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exceptionvoid transform(Row row, PointCollector collector) throws Exception或者void transform(RowWindow rowWindow, PointCollector collector) throws Exceptionvoid terminate(PointCollector collector) throws Exceptionvoid beforeDestroy()
注意,框架每执行一次 UDTF 查询,都会构造一个全新的 UDF 类实例,查询结束时,对应的 UDF 类实例即被销毁,因此不同 UDTF 查询(即使是在同一个 SQL 语句中)UDF 类实例内部的数据都是隔离的。您可以放心地在 UDTF 中维护一些状态数据,无需考虑并发对 UDF 类实例内部状态数据的影响。
下面将详细介绍各个接口的使用方法。
- void validate(UDFParameterValidator validator) throws Exception
validate方法能够对用户输入的参数进行验证。
您可以在该方法中限制输入序列的数量和类型,检查用户输入的属性或者进行自定义逻辑的验证。
UDFParameterValidator的使用方法请见 Javadoc。
- void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception
beforeStart方法有两个作用:
- 帮助用户解析 SQL 语句中的 UDF 参数
- 配置 UDF 运行时必要的信息,即指定 UDF 访问原始数据时采取的策略和输出结果序列的类型
- 创建资源,比如建立外部链接,打开文件等。
UDFParameters
UDFParameters的作用是解析 SQL 语句中的 UDF 参数(SQL 中 UDF 函数名称后括号中的部分)。参数包括路径(及其序列类型)参数和字符串 key-value 对形式输入的属性参数。
例子:
SELECT UDF(s1, s2, 'key1'='iotdb', 'key2'='123.45') FROM root.sg.d;用法:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
for (PartialPath path : parameters.getPaths()) {
TSDataType dataType = parameters.getDataType(path);
// do something
}
String stringValue = parameters.getString("key1"); // iotdb
Float floatValue = parameters.getFloat("key2"); // 123.45
Double doubleValue = parameters.getDouble("key3"); // null
int intValue = parameters.getIntOrDefault("key4", 678); // 678
// do something
// configurations
// ...
}UDTFConfigurations
您必须使用 UDTFConfigurations 指定 UDF 访问原始数据时采取的策略和输出结果序列的类型。
用法:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
// ...
// configurations
configurations
.setAccessStrategy(new RowByRowAccessStrategy())
.setOutputDataType(TSDataType.INT32);
}其中setAccessStrategy方法用于设定 UDF 访问原始数据时采取的策略,setOutputDataType用于设定输出结果序列的类型。
- setAccessStrategy
注意,您在此处设定的原始数据访问策略决定了框架会调用哪一种transform方法 ,请实现与原始数据访问策略对应的transform方法。当然,您也可以根据UDFParameters解析出来的属性参数,动态决定设定哪一种策略,因此,实现两种transform方法也是被允许的。
下面是您可以设定的访问原始数据的策略:
| 接口定义 | 描述 | 调用的transform方法 |
|---|---|---|
RowByRowAccessStrategy | 逐行地处理原始数据。框架会为每一行原始数据输入调用一次transform方法。当 UDF 只有一个输入序列时,一行输入就是该输入序列中的一个数据点。当 UDF 有多个输入序列时,一行输入序列对应的是这些输入序列按时间对齐后的结果(一行数据中,可能存在某一列为null值,但不会全部都是null)。 | void transform(Row row, PointCollector collector) throws Exception |
SlidingTimeWindowAccessStrategy | 以滑动时间窗口的方式处理原始数据。框架会为每一个原始数据输入窗口调用一次transform方法。一个窗口可能存在多行数据,每一行数据对应的是输入序列按时间对齐后的结果(一行数据中,可能存在某一列为null值,但不会全部都是null)。 | void transform(RowWindow rowWindow, PointCollector collector) throws Exception |
SlidingSizeWindowAccessStrategy | 以固定行数的方式处理原始数据,即每个数据处理窗口都会包含固定行数的数据(最后一个窗口除外)。框架会为每一个原始数据输入窗口调用一次transform方法。一个窗口可能存在多行数据,每一行数据对应的是输入序列按时间对齐后的结果(一行数据中,可能存在某一列为null值,但不会全部都是null)。 | void transform(RowWindow rowWindow, PointCollector collector) throws Exception |
RowByRowAccessStrategy的构造不需要任何参数。
SlidingTimeWindowAccessStrategy有多种构造方法,您可以向构造方法提供 3 类参数:
- 时间轴显示时间窗开始和结束时间
- 划分时间轴的时间间隔参数(必须为正数)
- 滑动步长(不要求大于等于时间间隔,但是必须为正数)
时间轴显示时间窗开始和结束时间不是必须要提供的。当您不提供这类参数时,时间轴显示时间窗开始时间会被定义为整个查询结果集中最小的时间戳,时间轴显示时间窗结束时间会被定义为整个查询结果集中最大的时间戳。
滑动步长参数也不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为划分时间轴的时间间隔。
3 类参数的关系可见下图。策略的构造方法详见 Javadoc。
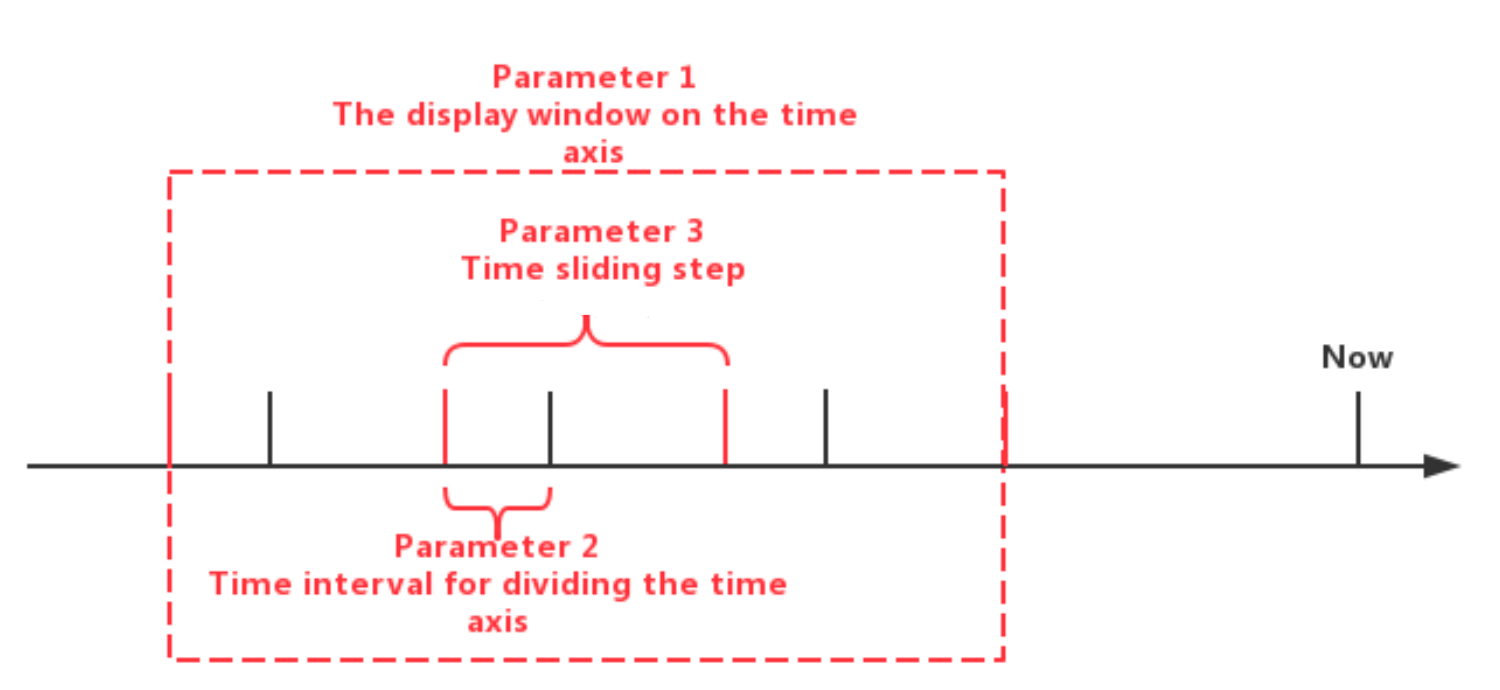
注意,最后的一些时间窗口的实际时间间隔可能小于规定的时间间隔参数。另外,可能存在某些时间窗口内数据行数量为 0 的情况,这种情况框架也会为该窗口调用一次transform方法。
SlidingSizeWindowAccessStrategy有多种构造方法,您可以向构造方法提供 2 个参数:
- 窗口大小,即一个数据处理窗口包含的数据行数。注意,最后一些窗口的数据行数可能少于规定的数据行数。
- 滑动步长,即下一窗口第一个数据行与当前窗口第一个数据行间的数据行数(不要求大于等于窗口大小,但是必须为正数)
滑动步长参数不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为窗口大小。
策略的构造方法详见 Javadoc。
- setOutputDataType
注意,您在此处设定的输出结果序列的类型,决定了transform方法中PointCollector实际能够接收的数据类型。setOutputDataType中设定的输出类型和PointCollector实际能够接收的数据输出类型关系如下:
setOutputDataType中设定的输出类型 | PointCollector实际能够接收的输出类型 |
|---|---|
INT32 | int |
INT64 | long |
FLOAT | float |
DOUBLE | double |
BOOLEAN | boolean |
TEXT | java.lang.String 和 org.apache.iotdb.tsfile.utils.Binary |
UDTF 输出序列的类型是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
下面是一个简单的例子:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// do something
// ...
configurations
.setAccessStrategy(new RowByRowAccessStrategy())
.setOutputDataType(parameters.getDataType(0));
}- void transform(Row row, PointCollector collector) throws Exception
当您在beforeStart方法中指定 UDF 读取原始数据的策略为 RowByRowAccessStrategy,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
该方法每次处理原始数据的一行。原始数据由Row读入,由PointCollector输出。您可以选择在一次transform方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在beforeStart方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
下面是一个实现了void transform(Row row, PointCollector collector) throws Exception方法的完整 UDF 示例。它是一个加法器,接收两列时间序列输入,当这两个数据点都不为null时,输出这两个数据点的代数和。
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.Row;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Adder implements UDTF {
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT64)
.setAccessStrategy(new RowByRowAccessStrategy());
}
@Override
public void transform(Row row, PointCollector collector) throws Exception {
if (row.isNull(0) || row.isNull(1)) {
return;
}
collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
}
}- void transform(RowWindow rowWindow, PointCollector collector) throws Exception
当您在beforeStart方法中指定 UDF 读取原始数据的策略为 SlidingTimeWindowAccessStrategy或者SlidingSizeWindowAccessStrategy时,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
该方法每次处理固定行数或者固定时间间隔内的一批数据,我们称包含这一批数据的容器为窗口。原始数据由RowWindow读入,由PointCollector输出。RowWindow能够帮助您访问某一批次的Row,它提供了对这一批次的Row进行随机访问和迭代访问的接口。您可以选择在一次transform方法调用中输出任意数量的数据点,需要注意的是,输出数据点的类型必须与您在beforeStart方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
下面是一个实现了void transform(RowWindow rowWindow, PointCollector collector) throws Exception方法的完整 UDF 示例。它是一个计数器,接收任意列数的时间序列输入,作用是统计并输出指定时间范围内每一个时间窗口中的数据行数。
import java.io.IOException;
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.RowWindow;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Counter implements UDTF {
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT32)
.setAccessStrategy(new SlidingTimeWindowAccessStrategy(
parameters.getLong("time_interval"),
parameters.getLong("sliding_step"),
parameters.getLong("display_window_begin"),
parameters.getLong("display_window_end")));
}
@Override
public void transform(RowWindow rowWindow, PointCollector collector) throws Exception {
if (rowWindow.windowSize() != 0) {
collector.putInt(rowWindow.getRow(0).getTime(), rowWindow.windowSize());
}
}
}- void terminate(PointCollector collector) throws Exception
在一些场景下,UDF 需要遍历完所有的原始数据后才能得到最后的输出结果。terminate接口为这类 UDF 提供了支持。
该方法会在所有的transform调用执行完成后,在beforeDestory方法执行前被调用。您可以选择使用transform方法进行单纯的数据处理,最后使用terminate将处理结果输出。
结果需要由PointCollector输出。您可以选择在一次terminate方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在beforeStart方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
下面是一个实现了void terminate(PointCollector collector) throws Exception方法的完整 UDF 示例。它接收一个INT32类型的时间序列输入,作用是输出该序列的最大值点。
import java.io.IOException;
import org.apache.iotdb.db.query.udf.api.UDTF;
import org.apache.iotdb.db.query.udf.api.access.Row;
import org.apache.iotdb.db.query.udf.api.collector.PointCollector;
import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class Max implements UDTF {
private Long time;
private int value;
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations
.setOutputDataType(TSDataType.INT32)
.setAccessStrategy(new RowByRowAccessStrategy());
}
@Override
public void transform(Row row, PointCollector collector) {
int candidateValue = row.getInt(0);
if (time == null || value < candidateValue) {
time = row.getTime();
value = candidateValue;
}
}
@Override
public void terminate(PointCollector collector) throws IOException {
if (time != null) {
collector.putInt(time, value);
}
}
}- void beforeDestroy()
UDTF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
完整 Maven 项目示例
如果您使用 Maven,可以参考我们编写的示例项目** udf-example**。您可以在 这里 找到它。
UDF 注册
注册一个 UDF 可以按如下流程进行:
实现一个完整的 UDF 类,假定这个类的全类名为
org.apache.iotdb.udf.UDTFExample将项目打成 JAR 包,如果您使用 Maven 管理项目,可以参考上述 Maven 项目示例的写法
将 JAR 包放置到目录
iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf(也可以是iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf的子目录)下。
注意,在部署集群的时候,需要保证每一个节点的 UDF JAR 包路径下都存在相应的 JAR 包。您可以通过修改配置文件中的
udf_root_dir来指定 UDF 加载 Jar 的根路径。使用 SQL 语句注册该 UDF,假定赋予该 UDF 的名字为
example
注册 UDF 的 SQL 语法如下:
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME>例子中注册 UDF 的 SQL 语句如下:
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample'由于 IoTDB 的 UDF 是通过反射技术动态装载的,因此您在装载过程中无需启停服务器。
注意:UDF 函数名称是大小写不敏感的。
注意:请不要给 UDF 函数注册一个内置函数的名字。使用内置函数的名字给 UDF 注册会失败。
注意:不同的 JAR 包中最好不要有全类名相同但实现功能逻辑不一样的类。例如 UDF(UDAF/UDTF):udf1、udf2分别对应资源udf1.jar、udf2.jar。如果两个 JAR 包里都包含一个org.apache.iotdb.udf.UDTFExample类,当同一个 SQL 中同时使用到这两个 UDF 时,系统会随机加载其中一个类,导致 UDF 执行行为不一致。
UDF 卸载
卸载 UDF 的 SQL 语法如下:
DROP FUNCTION <UDF-NAME>可以通过如下 SQL 语句卸载上面例子中的 UDF:
DROP FUNCTION exampleUDF 查询
UDF 的使用方法与普通内建函数的类似。
支持的基础 SQL 语法
SLIMIT/SOFFSETLIMIT/OFFSETNON ALIGN- 支持值过滤
- 支持时间过滤
对齐时间序列查询
UDF 查询目前不支持对对齐时间序列(Aligned Timeseries)进行查询,当您在SELECT子句中选择的序列中包含对齐时间序列时,会提示错误。
带 * 查询
假定现在有时间序列 root.sg.d1.s1和 root.sg.d1.s2。
- 执行
SELECT example(*) from root.sg.d1
那么结果集中将包括example(root.sg.d1.s1)和example(root.sg.d1.s2)的结果。
- 执行
SELECT example(s1, *) from root.sg.d1
那么结果集中将包括example(root.sg.d1.s1, root.sg.d1.s1)和example(root.sg.d1.s1, root.sg.d1.s2)的结果。
- 执行
SELECT example(*, *) from root.sg.d1
那么结果集中将包括example(root.sg.d1.s1, root.sg.d1.s1),example(root.sg.d1.s2, root.sg.d1.s1),example(root.sg.d1.s1, root.sg.d1.s2) 和 example(root.sg.d1.s2, root.sg.d1.s2)的结果。
带自定义输入参数的查询
您可以在进行 UDF 查询的时候,向 UDF 传入任意数量的键值对参数。键值对中的键和值都需要被单引号或者双引号引起来。注意,键值对参数只能在所有时间序列后传入。下面是一组例子:
SELECT example(s1, 'key1'='value1', 'key2'='value2'), example(*, 'key3'='value3') FROM root.sg.d1;
SELECT example(s1, s2, 'key1'='value1', 'key2'='value2') FROM root.sg.d1;与其他查询的嵌套查询
SELECT s1, s2, example(s1, s2) FROM root.sg.d1;
SELECT *, example(*) FROM root.sg.d1 DISABLE ALIGN;
SELECT s1 * example(* / s1 + s2) FROM root.sg.d1;
SELECT s1, s2, s1 + example(s1, s2), s1 - example(s1 + example(s1, s2) / s2) FROM root.sg.d1;查看所有注册的 UDF
SHOW FUNCTIONS用户权限管理
用户在使用 UDF 时会涉及到 3 种权限:
CREATE_FUNCTION:具备该权限的用户才被允许执行 UDF 注册操作DROP_FUNCTION:具备该权限的用户才被允许执行 UDF 卸载操作READ_TIMESERIES:具备该权限的用户才被允许使用 UDF 进行查询
更多用户权限相关的内容,请参考 权限管理语句。
配置项
在 SQL 语句中使用自定义函数时,可能提示内存不足。这种情况下,您可以通过更改配置文件iotdb-engine.properties中的udf_initial_byte_array_length_for_memory_control,udf_memory_budget_in_mb和udf_reader_transformer_collector_memory_proportion并重启服务来解决此问题。
贡献 UDF
该部分主要讲述了外部用户如何将自己编写的 UDF 贡献给 IoTDB 社区。
前提条件
UDF 具有通用性。
通用性主要指的是:UDF 在某些业务场景下,可以被广泛使用。换言之,就是 UDF 具有复用价值,可被社区内其他用户直接使用。
如果您不确定自己写的 UDF 是否具有通用性,可以发邮件到
dev@iotdb.apache.org或直接创建 ISSUE 发起讨论。UDF 已经完成测试,且能够正常运行在用户的生产环境中。
贡献清单
- UDF 的源代码
- UDF 的测试用例
- UDF 的使用说明
源代码
- 在
src/main/java/org/apache/iotdb/db/query/udf/builtin或者它的子文件夹中创建 UDF 主类和相关的辅助类。 - 在
src/main/java/org/apache/iotdb/db/query/udf/builtin/BuiltinFunction.java中注册您编写的 UDF。
测试用例
您至少需要为您贡献的 UDF 编写集成测试。
您可以在server/src/test/java/org/apache/iotdb/db/integration中为您贡献的 UDF 新增一个测试类进行测试。
使用说明
使用说明需要包含:UDF 的名称、UDF 的作用、执行函数必须的属性参数、函数的适用的场景以及使用示例等。
使用说明需包含中英文两个版本。应分别在 docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md 和 docs/UserGuide/Operation Manual/DML Data Manipulation Language.md 中新增使用说明。
提交 PR
当您准备好源代码、测试用例和使用说明后,就可以将 UDF 贡献到 IoTDB 社区了。在 Github 上面提交 Pull Request (PR) 即可。具体提交方式见:Pull Request Guide。
当 PR 评审通过并被合并后,您的 UDF 就已经贡献给 IoTDB 社区了!
已知的 UDF 库实现
- IoTDB-Quality,一个关于数据质量的 UDF 库实现,包括数据画像、数据质量评估与修复等一系列函数。
Q&A
Q1: 如何修改已经注册的 UDF?
A1: 假设 UDF 的名称为example,全类名为org.apache.iotdb.udf.UDTFExample,由example.jar引入
- 首先卸载已经注册的
example函数,执行DROP FUNCTION example - 删除
iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf目录下的example.jar - 修改
org.apache.iotdb.udf.UDTFExample中的逻辑,重新打包,JAR 包的名字可以仍然为example.jar - 将新的 JAR 包上传至
iotdb-server-0.13.0-SNAPSHOT-all-bin/ext/udf目录下 - 装载新的 UDF,执行
CREATE FUNCTION example AS "org.apache.iotdb.udf.UDTFExample"