Basic Concepts
Basic Concepts
1. General Time Series Database Concepts
This section introduces basic concepts commonly used in time series databases, including time series data, time series, devices, timeseries or fields, data points, collection frequency, TTL, schema, encoding, and compression.
1.1 Time Series Data
In scenarios such as IoT, industrial production, energy and power, connected vehicles, and infrastructure monitoring, devices usually use sensors to continuously collect status data about themselves or their environment. For example, motors collect voltage and current, wind turbines collect blade speed, angular velocity, and power generation, vehicles collect longitude, latitude, speed, and fuel consumption, and bridges collect vibration frequency, deflection, and displacement.

The common feature of this type of data is that it is related to time: the same collection object continuously generates new records as time passes. Data that is continuously generated and recorded in chronological order is called time series data.
1.2 Time Series
In time series data scenarios, a collection point continuously generates data points over time. When these data points are arranged in ascending timestamp order, they form a time series. In table form, a time series can be represented as a data table made up of time and value. In graph form, a time series can be represented as a trend curve that changes over time, and can also be described figuratively as the "electrocardiogram" of a device.
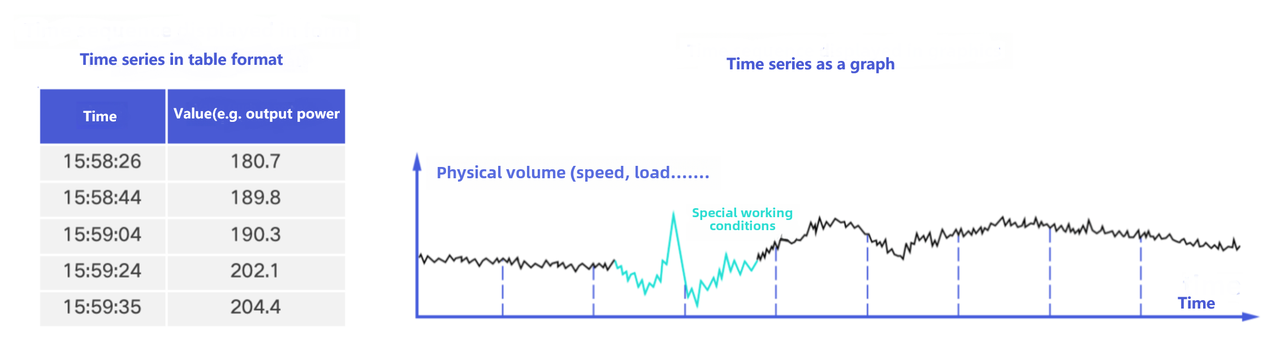
1.3 Device
A device, also called an entity or equipment, is a device or apparatus with physical quantities in a real-world scenario. It can be a physical device, a measurement apparatus, or a collection of sensors.
Common examples are as follows:
| Scenario | Device Example | Identifier Example |
|---|---|---|
| Energy | Wind turbine | Region, station, line, model, instance, etc. |
| Factory | Robotic arm | Unique ID generated by an IoT platform |
| Connected vehicle | Vehicle | Vehicle identification number (VIN) |
| Monitoring | CPU | Equipment room, rack, hostname, device type, etc. |
1.4 Timeseries / Field
A timeseries or field can also be called a physical quantity, time series, timeline, signal, metric, point, or measured value. It is the measurement information recorded by a detection device in a real-world scenario. Usually, one physical quantity represents one collection point that can periodically collect a physical quantity from its environment or device. When the data points generated by a timeseries or field are arranged in ascending timestamp order, they form a time series.
Common examples are as follows:
| Scenario | Timeseries / Field Example |
|---|---|
| Energy and power | Current, voltage, wind speed, rotational speed |
| Connected vehicle | Fuel level, vehicle speed, longitude, latitude |
| Factory | Temperature, humidity |
1.5 Data Point
A data point consists of a timestamp and a value. The timestamp indicates when the data was generated, and the value indicates the collection result of the timeseries or field at that time. The value can be of various types, such as BOOLEAN, FLOAT, and INT32.
A row in a tabular time series, or a point in a trend chart, can be understood as a data point.
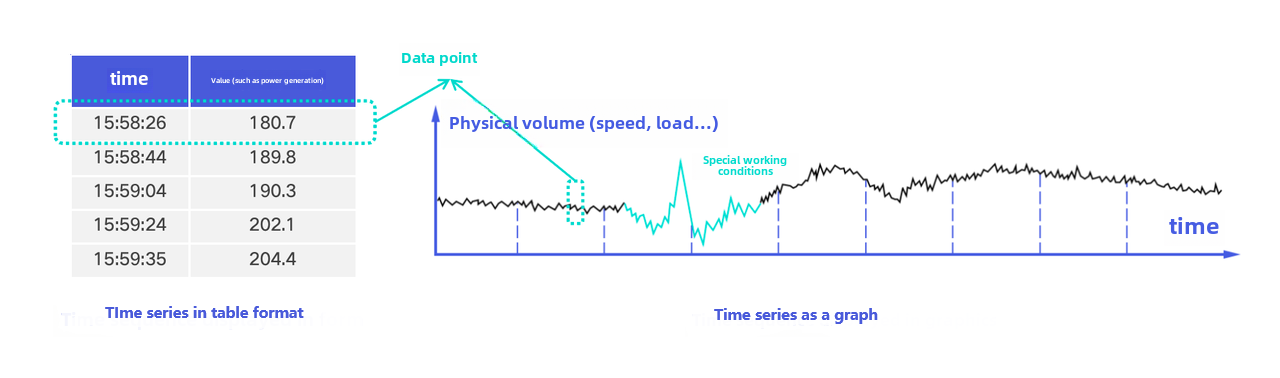
1.6 Collection Frequency
Collection frequency refers to the number of times a physical quantity generates data within a certain period. For example, if a temperature sensor collects temperature data once per second, its collection frequency is 1 Hz, that is, once per second.
The higher the collection frequency, the more data points are generated per unit of time, and the higher the requirements for write, storage, and query capabilities.
1.7 Data Retention Time (TTL)
TTL specifies the retention time of data. Data beyond the TTL will be automatically deleted.
Using TTL properly can control disk space usage, avoid exceptions such as disks becoming full, and help maintain query performance and reduce memory usage.
1.8 Schema
Schema is the data model information of a database and is used to describe the structure and definition of data. For time series data, schema usually includes devices, timeseries or fields, data types, and other information.
1.9 Encoding and Compression
Encoding is a compression technique used to represent data in binary form and improve storage efficiency. Compression further compresses the encoded binary data to improve storage efficiency.
For details about encoding and compression supported by IoTDB, see Compression and Encoding.
2. Common IoTDB Concepts
This section introduces common concepts in IoTDB data models, distributed architecture, and deployment. These concepts explain how IoTDB organizes, manages, and deploys time series data.
2.1 Data Model Concepts
2.1.1 Data Model (sql_dialect)
IoTDB supports two data models: tree model and table model. The core objects managed by both models are devices and timeseries, but their organization methods and syntax are different.
Tree model: Manages data through hierarchical paths, where one path corresponds to one timeseries of one device.
Table model: Manages data through relational tables. It is recommended that one table correspond to one type of device.
Both model spaces can exist in the same cluster instance. Different models use different syntax and database naming methods, and are not visible to each other by default.
2.1.2 Database
In the table model, a database is the upper-level organizational structure and can manage multiple types of devices and their tables. Before creating tables, writing data, or querying data, you usually need to create a database first.
2.1.3 Table
In the table model, it is recommended that one table correspond to one type of device and be used to organize the time series data of that type of device. Devices of the same type usually have the same or similar sets of fields.
2.1.4 Time Column, Tag Column, Attribute Column, and Field Column
Columns in the table model can be divided by purpose into time columns, tag columns, attribute columns, and field columns.
| Concept | Description |
|---|---|
| Time column (TIME) | Each table must contain one time column whose data type is TIMESTAMP |
| Tag column (TAG) | Used to identify devices. It can serve as the composite primary key of devices and usually does not change over time |
| Attribute column (ATTRIBUTE) | Used to describe static attributes of devices. It does not change over time and can be updated or added |
| Field column (FIELD) | Used to store field values collected by devices. Values change over time |
In terms of data filtering efficiency, the usual order can be understood as: time columns and tag columns first, then attribute columns, and finally field columns.
2.2 Distributed Concepts
IoTDB supports cluster deployment. Common concepts in a cluster include nodes, Regions, and multiple replicas. A common cluster deployment mode is 3C3D, that is, 3 ConfigNodes and 3 DataNodes.
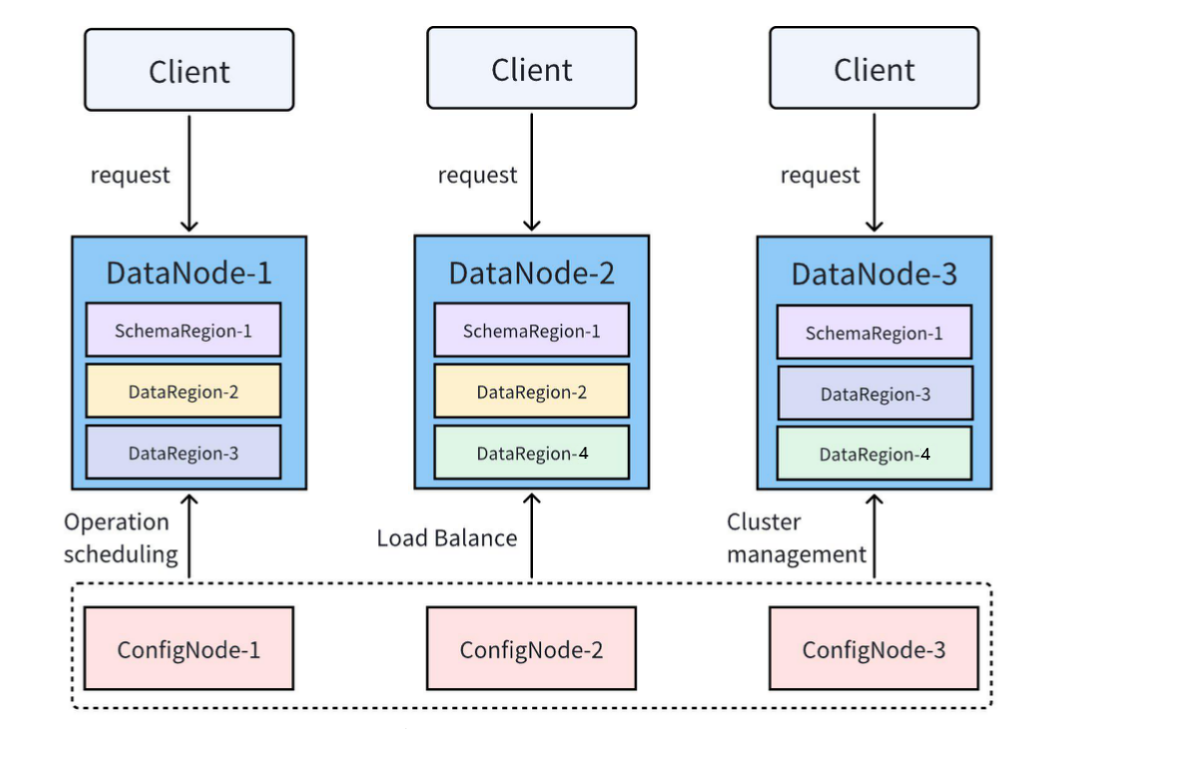
2.2.1 Node
An IoTDB cluster includes three types of nodes: ConfigNode, DataNode, and AINode.
ConfigNode: Manages node information, configuration information, user permissions, schema, partition information, and other cluster information. It is responsible for scheduling distributed operations and load balancing. All ConfigNodes are full backups of each other.
DataNode: Serves client requests and is responsible for data storage and computation.
AINode: Provides machine learning capabilities. It supports registering trained machine learning models and invoking models for inference through SQL.
2.2.2 Data Partition (Region)
In IoTDB, both schema and data are divided into smaller partitions, namely Regions, and are managed by DataNodes in the cluster.
SchemaRegion: A schema partition used to manage the schema of some devices and timeseries or fields.
DataRegion: A data partition used to manage the data of some devices within a period of time.
Regions with the same RegionID on different DataNodes are replicas of each other.
2.2.3 Multiple Replicas
The number of replicas for data and schema is configurable. Multiple replicas can provide high-availability services.
| Category | Configuration Item | Recommended Standalone Configuration | Recommended Cluster Configuration |
|---|---|---|---|
| Schema | schema_replication_factor | 1 | 3 |
| Data | data_replication_factor | 1 | 2 |
2.3 Deployment Concepts
IoTDB has two running modes: standalone mode and cluster mode.
2.3.1 Standalone Mode
An IoTDB standalone instance includes 1 ConfigNode and 1 DataNode, that is, 1C1D.
Features: Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
Applicable scenarios: Scenarios with limited resources or low high-availability requirements, such as edge servers.
Deployment method: Standalone deployment.
2.3.2 Cluster Mode
An IoTDB cluster instance consists of 3 ConfigNodes and no fewer than 3 DataNodes, usually 3 DataNodes, that is, 3C3D. When some nodes fail, the remaining nodes can still provide services externally, ensuring high availability of database services. Database performance can also be improved by adding nodes.
Features: High availability and high scalability. System performance can be improved by adding DataNodes.
Applicable scenarios: Enterprise application scenarios that require high availability and reliability.
Deployment method: Cluster deployment.
2.3.3 Feature Summary
| Dimension | Standalone Mode | Cluster Mode |
|---|---|---|
| Applicable scenarios | Edge deployment; low high-availability requirements | High-availability services; disaster recovery scenarios, etc. |
| Required number of machines | 1 | >= 3 |
| Safety and reliability | Cannot tolerate a single point of failure | High; can tolerate a single point of failure |
| Scalability | Can scale DataNodes to improve performance | Can scale DataNodes to improve performance |
| Performance | Can scale with the number of DataNodes | Can scale with the number of DataNodes |
Standalone mode and cluster mode have similar deployment steps: ConfigNodes and DataNodes are added one by one. The differences are only in the number of replicas and the minimum number of nodes that can provide services.