基础概念
基础概念
1. 时序数据库通用概念
本节介绍时序数据库领域中常见的基础概念,包括时序数据、时间序列、设备、测点、数据点、采集频率、TTL、元数据、编码和压缩。
1.1 时序数据
在物联网、工业生产、能源电力、车联网、基础设施监测等场景中,设备通常会通过传感器持续采集自身或环境的状态数据。例如,电机采集电压和电流,风机采集叶片转速、角速度和发电功率,车辆采集经纬度、速度和油耗,桥梁采集振动频率、挠度和位移量。

这类数据的共同特点是与时间相关:同一采集对象会随着时间推移不断产生新的记录。按时间顺序持续产生并记录的数据,称为时序数据。
1.2 时间序列
在时序数据场景中,一个采集点位会随着时间不断产生数据点,这些数据点按时间戳递增排列后,形成一条时间序列。从表格形式看,一条时间序列可以表示为由时间和值组成的数据表;从图形形式看,一条时间序列可以表示为随时间变化的趋势曲线。也可以形象的称之为设备的“心电图”。
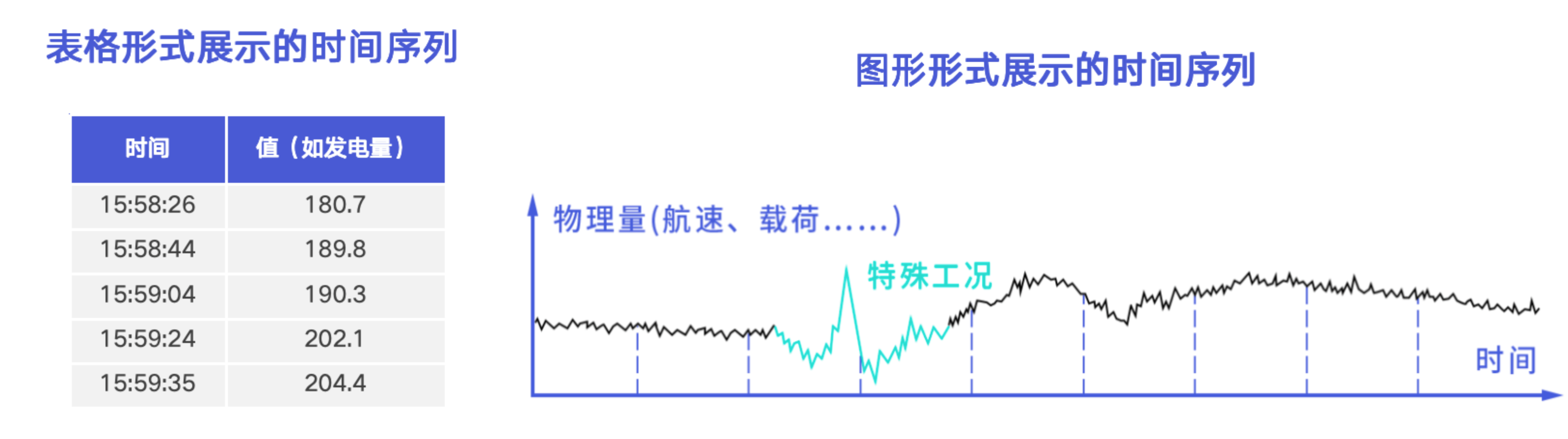
1.3 设备(Device)
设备也称为实体、装备等,是实际场景中拥有物理量的设备或装置,可以是物理设备、测量装置或传感器集合。
常见示例如下:
| 场景 | 设备示例 | 标识方式示例 |
|---|---|---|
| 能源场景 | 风机 | 区域、场站、线路、机型、实例等 |
| 工厂场景 | 机械臂 | 物联网平台生成的唯一 ID |
| 车联网场景 | 车辆 | 车辆识别代码 VIN |
| 监控场景 | CPU | 机房、机架、Hostname、设备类型等 |
1.4 测点(Timeseries / Field)
测点也可称为物理量、时间序列、时间线、信号量、指标、点位或测量值,是实际场景中检测装置记录的测量信息。通常,一个物理量代表一个采集点位,能够定期采集所在环境或设备的物理量。一个测点随时间产生的数据点按时间戳递增排列后,即形成一条时间序列。
常见示例如下:
| 场景 | 测点示例 |
|---|---|
| 能源电力场景 | 电流、电压、风速、转速 |
| 车联网场景 | 油量、车速、经度、纬度 |
| 工厂场景 | 温度、湿度 |
1.5 数据点(Data Point)
数据点由一个时间戳和一个数值组成。时间戳用于表示数据产生的时间,数值用于表示该测点在该时间的采集结果。数值可以为 BOOLEAN、FLOAT、INT32 等多种类型。
表格形式的时间序列中的一行,或趋势图中的一个点,都可以理解为一个数据点。
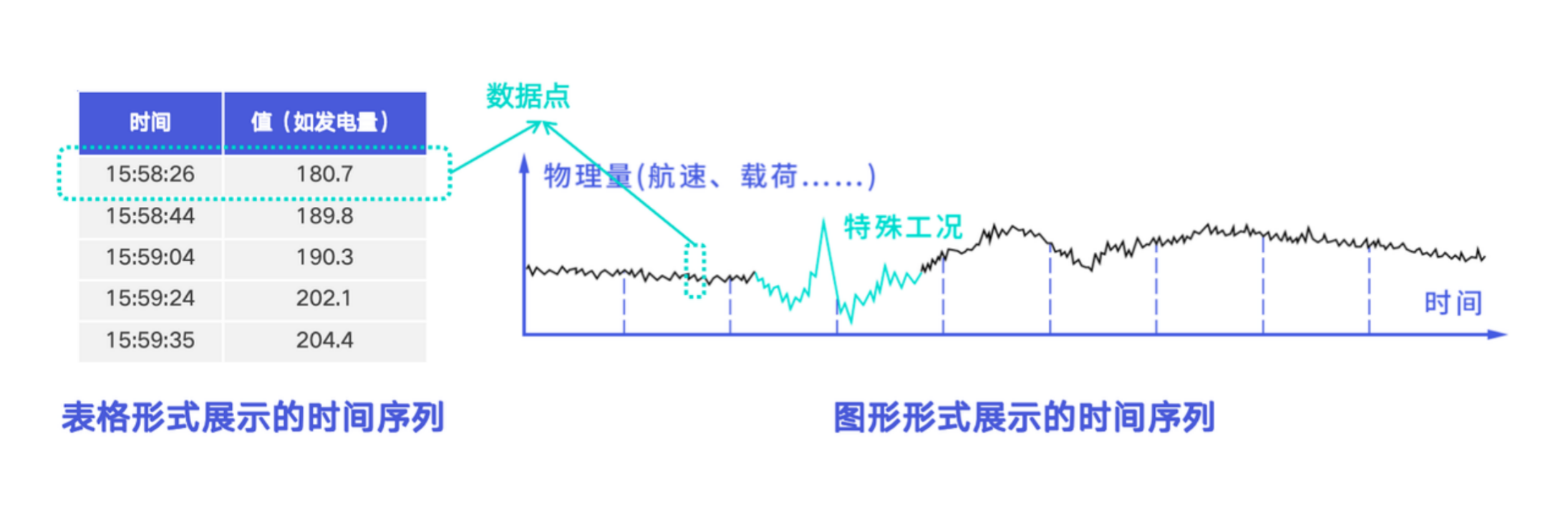
1.6 采集频率(Frequency)
采集频率指物理量在一定时间内产生数据的次数。例如,一个温度传感器每秒采集一次温度数据,则采集频率为 1Hz,即每秒 1 次。
采集频率越高,单位时间内产生的数据点越多,对写入、存储和查询能力的要求也越高。
1.7 数据保存时间(TTL)
TTL 用于指定数据的保存时间。超过 TTL 的数据将被自动删除。
合理使用 TTL 可以控制磁盘空间占用,避免磁盘写满等异常,并有助于维持查询性能、减少内存资源占用。
1.8 元数据(Schema)
元数据是数据库的数据模型信息,用于描述数据的结构和定义。对于时序数据,元数据通常包括设备、测点、数据类型等信息。
1.9 编码(Encoding)和压缩(Compression)
编码是一种压缩技术,用于将数据以二进制形式表示,从而提高存储效率。压缩是在编码后进一步压缩二进制数据,以提升存储效率。
IoTDB 支持的编码和压缩详细信息请查看:压缩和编码。
2. IoTDB 常见概念
本节介绍 IoTDB 数据模型、分布式和部署中的常见概念。这些概念用于说明 IoTDB 如何组织、管理和部署时序数据。
2.1 数据模型相关概念
2.1.1 数据模型(sql_dialect)
IoTDB 支持树模型和表模型两种数据模型。两种模型管理的核心对象均为设备和测点,但组织方式和使用语法不同。
树模型:以层级路径的方式管理数据,一条路径对应一个设备的一个测点。
表模型:以关系表的方式管理数据,推荐一张表对应一类设备。
同一个集群实例中可以存在两种模型空间。不同模型的语法、数据库命名方式不同,默认不互相可见。
2.1.2 数据库
在表模型中,数据库是表模型中的上层组织结构,可管理多类设备及其表。创建表、写入数据或查询数据前,通常需要先创建数据库。
2.1.3 表
在表模型中,建模时推荐一张表对应一类设备,用于组织该类设备的时序数据。同类设备通常具有相同或相近的测点集合。
2.1.4 时间列、标签列、属性列和测点列
表模型中的列按照用途可分为时间列、标签列、属性列和测点列。
| 概念 | 说明 |
|---|---|
| 时间列(TIME) | 每张表必须包含一个时间列,数据类型为 TIMESTAMP |
| 标签列(TAG) | 用于标识设备,可作为设备的联合主键,通常不随时间变化 |
| 属性列(ATTRIBUTE) | 用于描述设备的静态属性,不随时间变化,可更新或新增 |
| 测点列(FIELD) | 用于存储设备采集的测点值,值随时间变化 |
在数据筛选效率上,通常可理解为:时间列和标签列优先,其次是属性列,最后是测点列。
2.2 分布式相关概念
IoTDB 支持以集群方式运行。集群中常见概念包括节点、Region 和多副本。一个常见的集群部署模式是 3C3D,即 3 个 ConfigNode 和 3 个 DataNode。
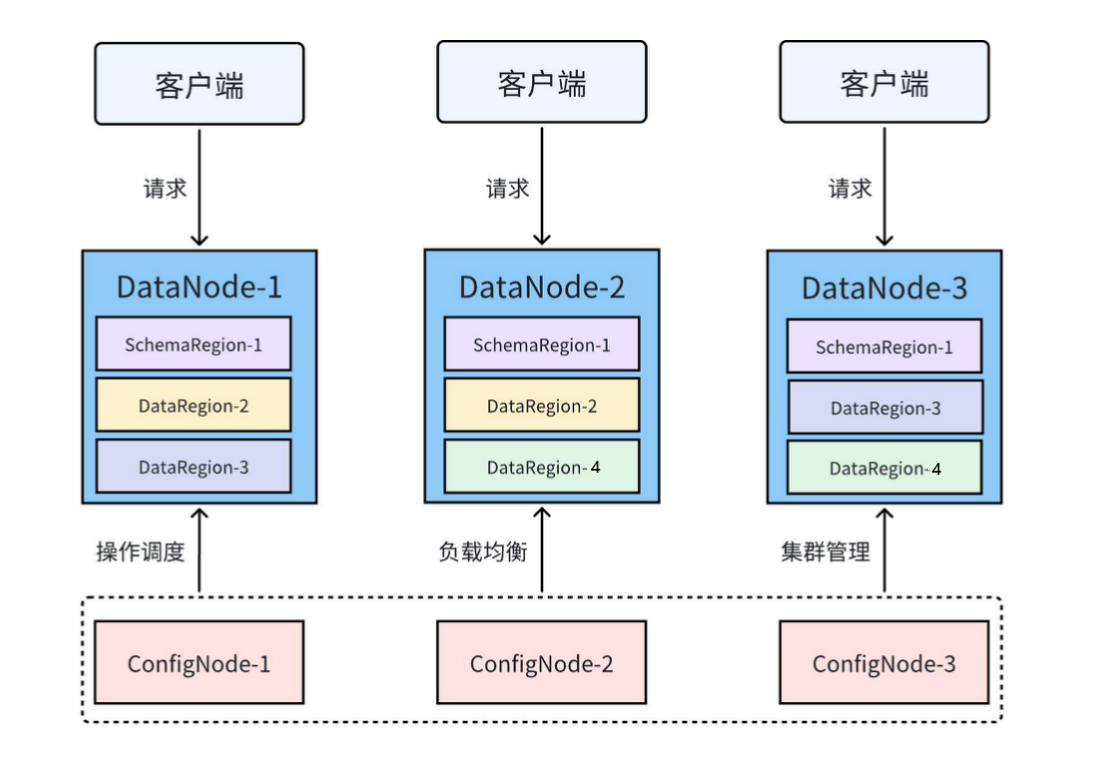
2.2.1 节点
IoTDB 集群包括 ConfigNode、DataNode 和 AINode 三类节点。
ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡。所有 ConfigNode 之间互为全量备份。
DataNode:服务客户端请求,负责数据的存储和计算。
AINode:提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理。
2.2.2 数据分区(Region)
在 IoTDB 中,元数据和数据都被划分为较小的分区,即 Region,并由集群中的各个 DataNode 管理。
SchemaRegion:元数据分区,用于管理一部分设备和测点的元数据。
DataRegion:数据分区,用于管理一部分设备在一段时间内的数据。
不同 DataNode 上相同 RegionID 的 Region 互为副本。
2.2.3 多副本
数据和元数据的副本数可配置。多副本可提供高可用服务。
| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
|---|---|---|---|
| 元数据 | schema_replication_factor | 1 | 3 |
| 数据 | data_replication_factor | 1 | 2 |
2.3 部署相关概念
IoTDB 有两种运行模式:单机模式和集群模式。
2.3.1 单机模式
IoTDB 单机实例包括 1 个 ConfigNode、1 个 DataNode,即 1C1D。
- 特点:便于开发者安装部署,部署和维护成本较低,操作方便。
- 适用场景:资源有限或对高可用要求不高的场景,例如边缘端服务器。
- 部署方法:单机版部署
2.3.2 集群模式
IoTDB 集群实例为 3 个 ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即 3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
- 特点:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
- 适用场景:需要提供高可用和可靠性的企业级应用场景。
- 部署方法:集群版部署
2.3.3 特点总结
| 维度 | 单机模式 | 集群模式 |
|---|---|---|
| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
| 所需机器数量 | 1 | ≥3 |
| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。