建模方案设计
建模方案设计
本章节主要介绍如何将时序数据应用场景转化为IoTDB时序建模。
1. 时序数据模型
在构建IoTDB建模方案前,需要先了解时序数据和时序数据模型,详细内容见此页面:基础概念
2. IoTDB 的树表孪生模型
IoTDB 提供了树表孪生模型的方式,其特点分别如下:
树模型:以测点为对象进行管理,每个测点对应一条时间序列,测点名按.分割可形成一个树形目录结构,与物理世界一一对应,对测点的读写操作简单直观。
- 数据建模时,为了足够的性能要求,建议数据路径(Path)的倒数第二层节点(对应设备数量)不少于 1000 个,且设备数量与并发处理能力挂钩,设备数量充足时,并发读写效率更优。
若遇到“设备数量较少但单设备测点数量较多”的场景(如仅 3 台设备,每台设备含 10000 个测点),推荐在最后层级新增.value,以此提升倒数第二层节点总数,示例:root.db.device01.metric.value。- 在构建树模型路径时,节点命名若存在包含非标准字符或特殊符号的可能性,则建议对所有层级节点实施反引号封装策略。这样可以有效规避因字符解析异常导致的测点注册失败及数据写入中断问题,确保路径标识符在语法解析层面的准确性。
表模型:推荐为每类设备创建一张表,同类设备的物理量采集都具备一定共性(如都采集温度和湿度物理量),数据分析灵活丰富。
2.1 模型特点
树表孪生模型有各自的适用场景。
以下表格从适用场景、典型操作等多个维度对树模型和表模型进行了对比。用户可以根据具体的使用需求,选择适合的模型,从而实现数据的高效存储和管理。
| 对比维度 | 树模型 | 表模型 |
| 适用场景 | 测点管理,监控场景 | 设备管理,分析场景 |
| 典型操作 | 指定点位路径进行读写 | 通过标签进行数据筛选分析 |
| 结构特点 | 和文件系统一样灵活增删 | 模板化管理,便于数据治理 |
| 语法特点 | 简洁灵活 | 分析丰富 |
| 性能对比 | 相同 | |
注意:
- 同一个集群实例中可以存在两种模型空间,不同模型的语法、数据库命名方式不同,默认不互相可见。
2.2 模型选择
IoTDB 支持通过多种客户端工具与数据库建立连接,不同客户端下进行模型选择的方式说明如下:
通过 CLI 建立连接时,需要通过 sql_dialect 参数指定使用的模型(默认使用树模型)。
# 树模型
start-cli.sh(bat)
start-cli.sh(bat) -sql_dialect tree
# 表模型
start-cli.sh(bat) -sql_dialect table在使用 SQL 语言进行数据操作时,可通过 set 语句切换使用的模型。
-- 指定为树模型
IoTDB> SET SQL_DIALECT=TREE
-- 指定为表模型
IoTDB> SET SQL_DIALECT=TABLE- 应用编程接口
通过多语言应用编程接口建立连接时,可通过模型对应的 session/sessionpool 创建连接池实例,简单示例如下:
// 树模型
SessionPool sessionPool =
new SessionPool.Builder()
.nodeUrls(nodeUrls)
.user(username)
.password(password)
.maxSize(3)
.build();
//表模型
ITableSessionPool tableSessionPool =
new TableSessionPoolBuilder()
.nodeUrls(nodeUrls)
.user(username)
.password(password)
.maxSize(1)
.build();# 树模型
session = Session(
ip=ip,
port=port,
user=username,
password=password,
fetch_size=1024,
zone_id="UTC+8",
enable_redirection=True
)
# 表模型
config = TableSessionPoolConfig(
node_urls=node_urls,
username=username,
password=password,
database=database,
max_pool_size=max_pool_size,
fetch_size=fetch_size,
wait_timeout_in_ms=wait_timeout_in_ms,
)
session_pool = TableSessionPool(config)// 树模型
session = new Session(hostip, port, username, password);
// 表模型
session = (new TableSessionBuilder())
->host(ip)
->rpcPort(port)
->username(username)
->password(password)
->build();//树模型
config := &client.PoolConfig{
Host: host,
Port: port,
UserName: user,
Password: password,
}
sessionPool = client.NewSessionPool(config, 3, 60000, 60000, false)
defer sessionPool.Close()
//表模型
config := &client.PoolConfig{
Host: host,
Port: port,
UserName: user,
Password: password,
Database: dbname,
}
sessionPool := client.NewTableSessionPool(config, 3, 60000, 4000, false)
defer sessionPool.Close()//树模型
var session_pool = new SessionPool(host, port, pool_size);
//表模型
var tableSessionPool = new TableSessionPool.Builder()
.SetNodeUrls(nodeUrls)
.SetUsername(username)
.SetPassword(password)
.SetFetchSize(1024)
.Build();使用表模型,必须在 url 中指定 sql_dialect 参数为 table。
// 树模型
Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");
Connection connection = DriverManager.getConnection(
"jdbc:iotdb://127.0.0.1:6667/", username, password);
// 表模型
Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");
Connection connection = DriverManager.getConnection(
"jdbc:iotdb://127.0.0.1:6667?sql_dialect=table", username, password);2.3 树转表
IoTDB 提供了树转表功能,如下图所示:
该功能支持通过创建表视图的方式,将已存在的树模型数据转化为表视图,进而通过表视图进行查询,实现了对同一份数据的树模型和表模型协同处理。更详细的功能介绍可参考树转表视图,需要注意的是:创建树转表视图的 SQL 语句只允许在表模型下执行。
3. 应用场景
应用场景主要包括两类:
场景一:使用树模型进行数据的读写
场景二:使用表模型进行数据的读写
3.1 场景一:树模型
3.1.1 特点
简单直观,和物理世界的监测点位一一对应
类似文件系统一样灵活,可以设计任意分支结构
适用 DCS、SCADA 等工业监控场景
3.1.2 基础概念
| 概念 | 定义 |
|---|---|
| 数据库 | 定义:一个以 root. 为前缀的路径 命名推荐:仅包含 root 的下一级节点,如 root.db 数量推荐:上限和内存相关,一个数据库也可以充分利用机器资源,无需为性能原因创建多个数据库 创建方式:推荐手动创建,也可创建时间序列时自动创建(默认为 root 的下一级节点) |
| 时间序列(测点) | 定义: 1. 一个以数据库路径为前缀的、由 . 分割的路径,可包含任意多个层级,如 root.db.turbine.device1.metric1 2. 每个时间序列可以有不同的数据类型。 命名推荐: 1. 仅将唯一定位时间序列的标签(类似联合主键)放入路径中,一般不超过10层 2. 通常将基数(不同的取值数量)少的标签放在前面,便于系统将公共前缀进行压缩 数量推荐: 1. 集群可管理的时间序列总量和总内存相关,可参考资源推荐章节 2. 任一层级的子节点数量没有限制 创建方式:可手动创建或在数据写入时自动创建。 |
| 设备 | 定义:倒数第二级为设备,如 root.db.turbine.device1.metric1中的“device1”这一层级即为设备 创建方式:无法仅创建设备,随时间序列创建而存在 |
3.1.3 建模示例
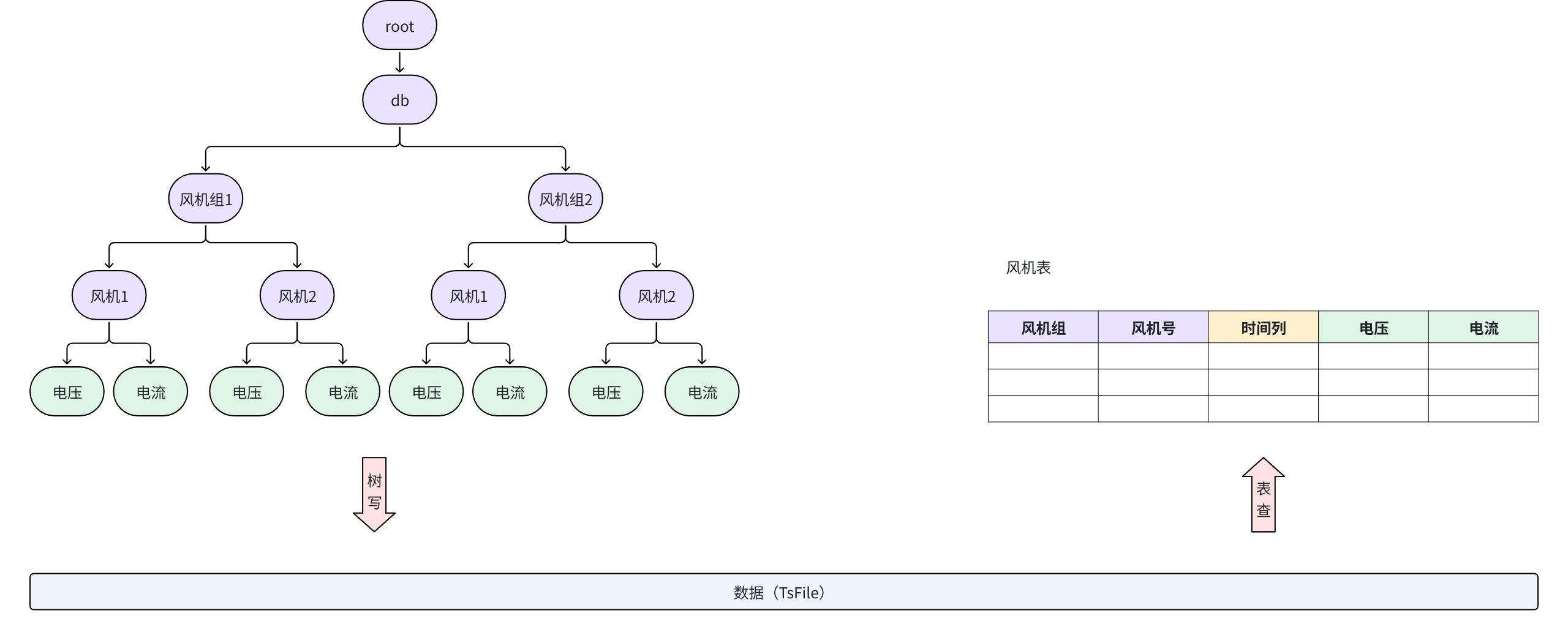
3.1.3.1 有多种类型的设备需要管理,如何建模?
- 如场景中不同类型的设备具备不同的层级路径和测点集合,可以在数据库节点下按设备类型创建分支。每种设备下可以有不同的测点结构。
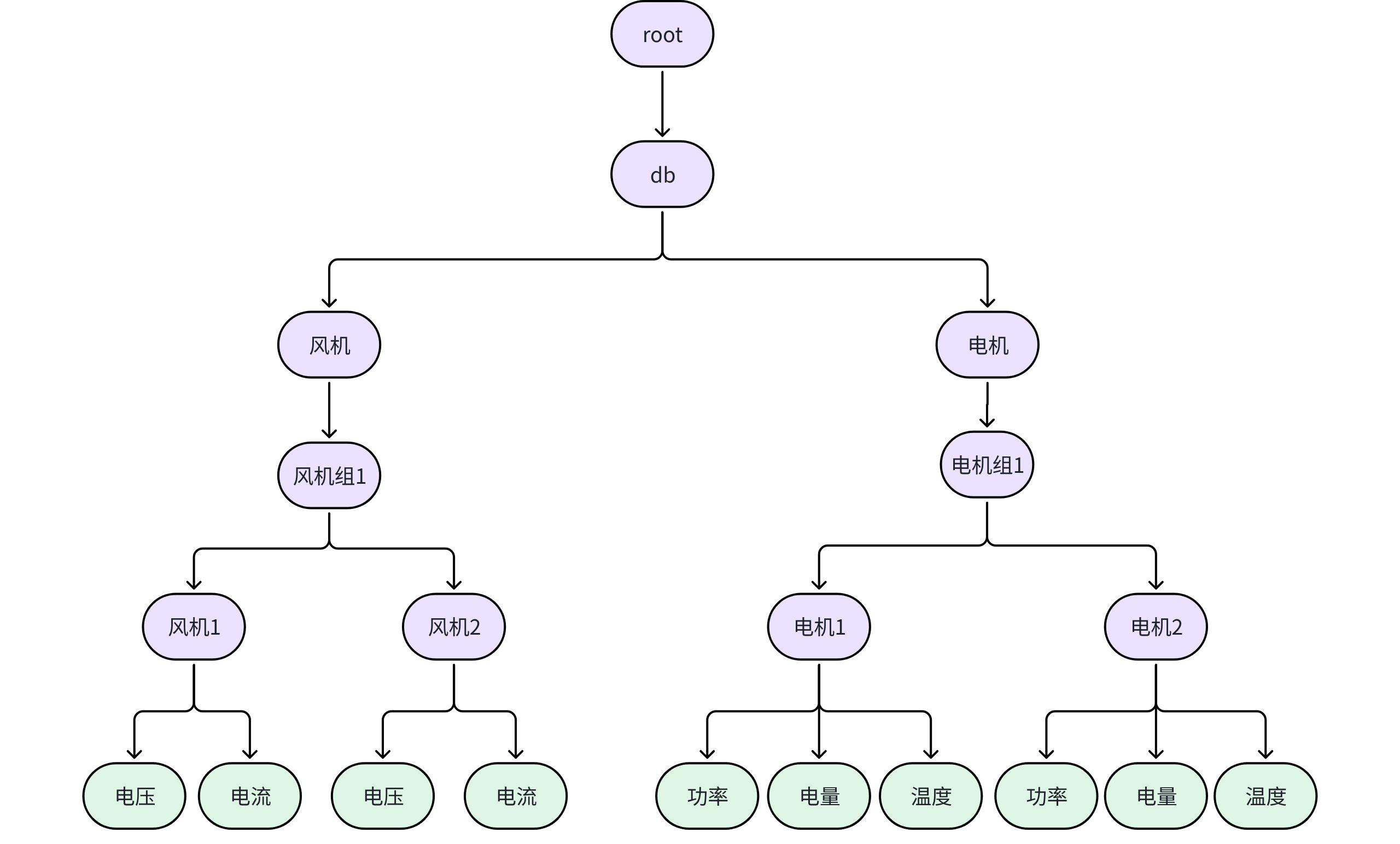
3.1.3.2 如果场景中没有设备,只有测点,如何建模?
- 如场站的监控系统中,每个测点都有唯一编号,但无法对应到某些设备。
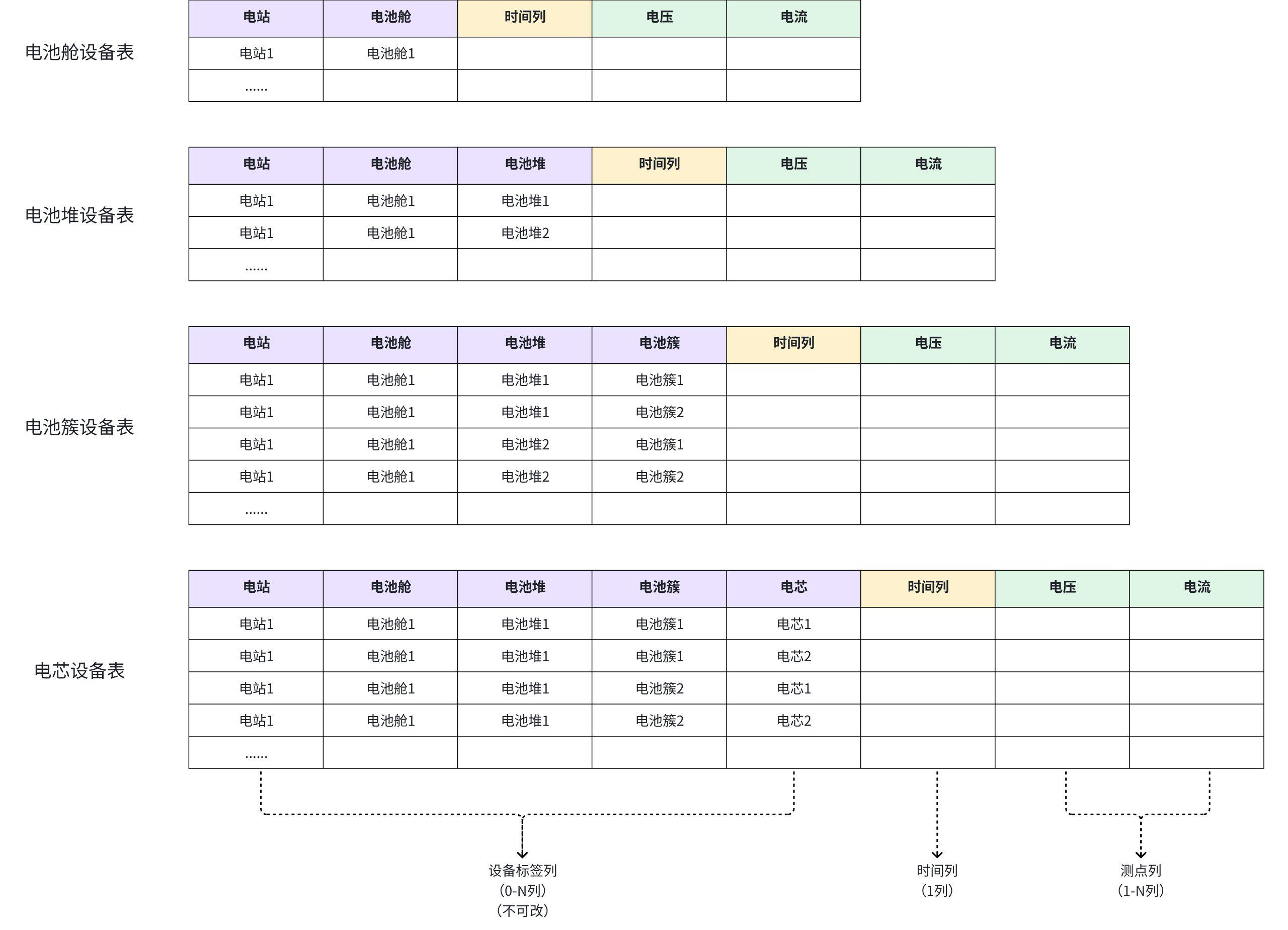
3.1.3.3 如果在一个设备下,既有子设备,也有测点,如何建模?
- 如在储能场景中,每一层结构都要监控其电压和电流,可以采用如下建模方式。
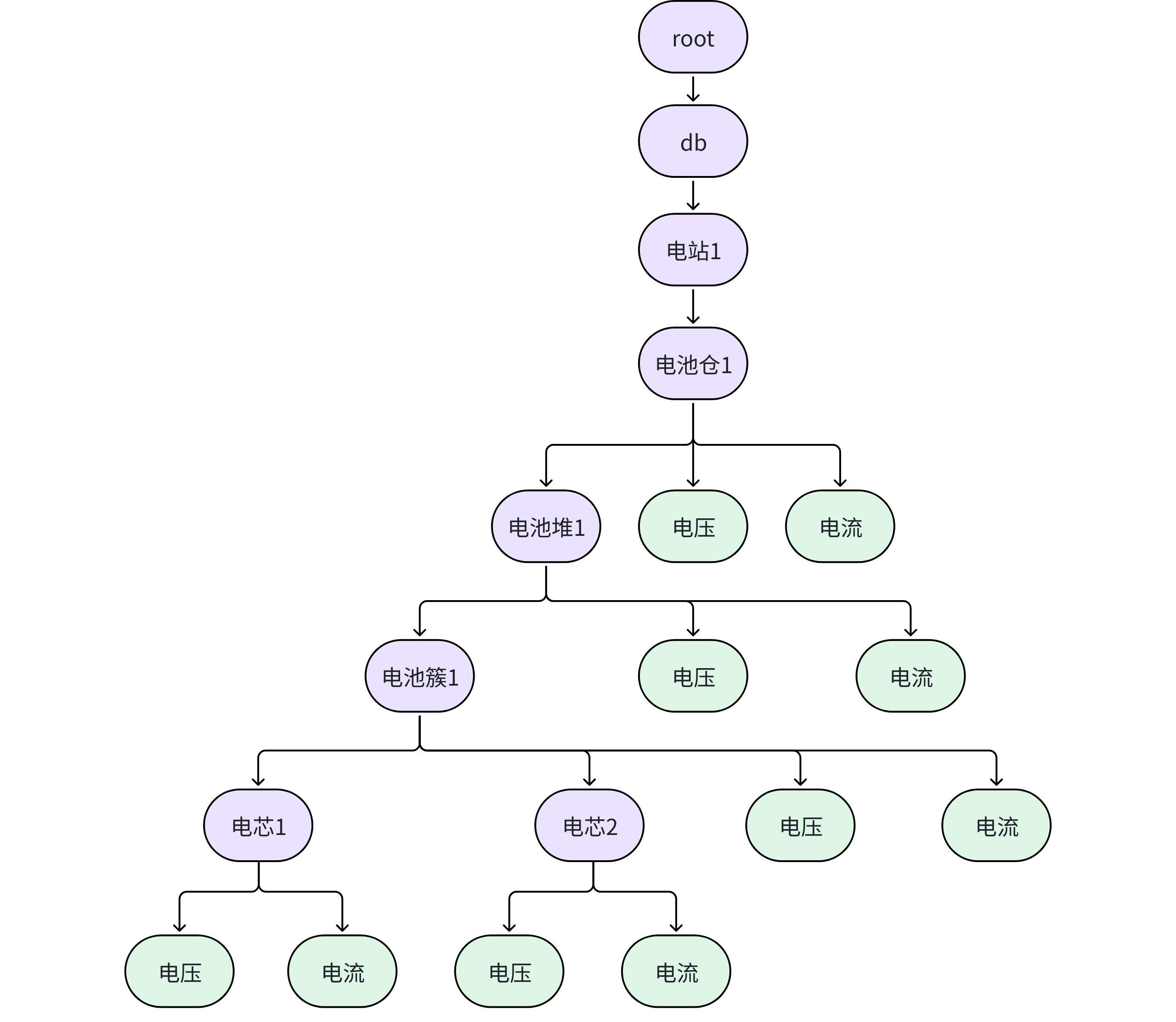
3.2 场景二:表模型
3.2.1 特点
以时序表建模管理设备时序数据,便于使用标准 SQL 进行分析
适用于设备数据分析或从其他数据库迁移至 IoTDB 的场景
3.2.2 基础概念
数据库:可管理多类设备
时序表:对应一类设备
| 列类别 | 定义 |
|---|---|
| 时间列(TIME) | 每个时序表必须有一个时间列,且列名必须为 time,数据类型为 TIMESTAMP |
| 标签列(TAG) | 设备的唯一标识(联合主键),可以为 0 至多个 标签信息不可修改和删除,但允许增加 推荐按粒度由大到小进行排列 |
| 测点列(FIELD) | 一个设备采集的测点可以有1个至多个,值随时间变化 表的测点列没有数量限制,可以达到数十万以上 |
| 属性列(ATTRIBUTE) | 对设备的补充描述,不随时间变化 设备属性信息可以有0个或多个,可以更新或新增 少量希望修改的静态属性可以存至此列 |
数据筛选效率:时间列=标签列>属性列>测点列
3.2.3 建模示例
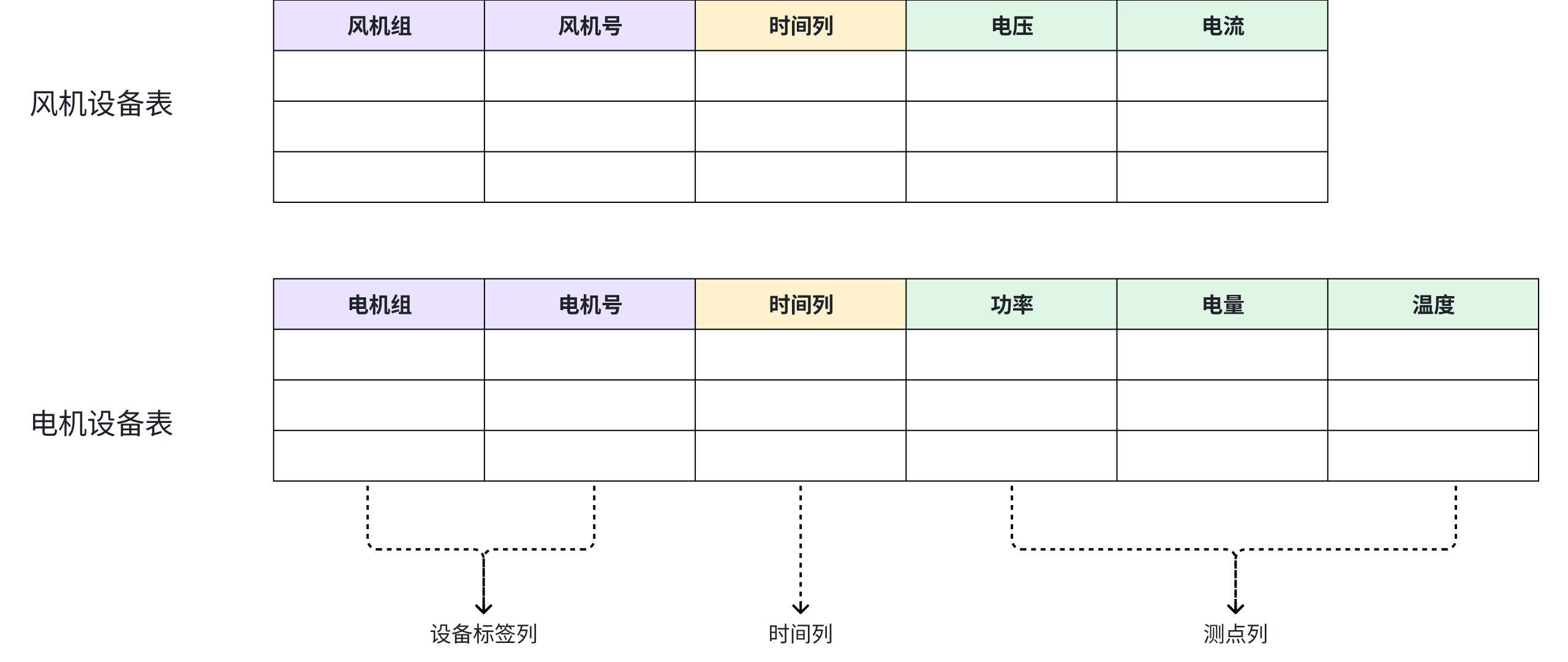
3.2.3.1 有多种类型的设备需要管理,如何建模?
- 推荐为每一类型的设备建立一张表,每个表可以具有不同的标签和测点集合。
- 即使设备之间有联系,或有层级关系,也推荐为每一类设备建一张表。
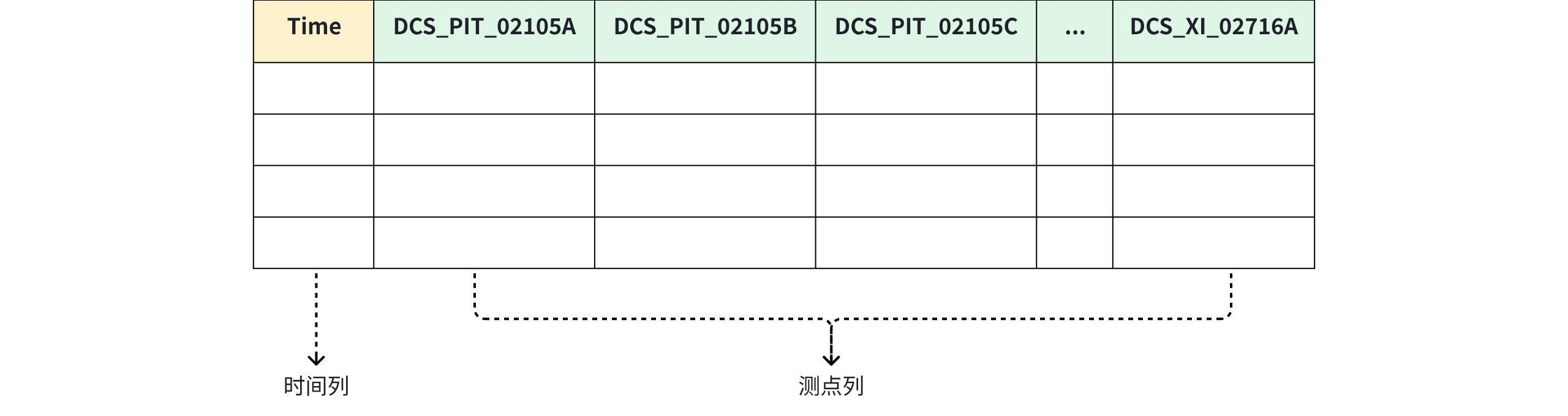
3.2.3.2 如果没有设备标识列和属性列,如何建模?
- 列数没有数量限制,可以达到数十万以上。
3.2.3.3 如果在一个设备下,既有子设备,也有测点,如何建模?
- 每个设备有多个子设备及测点信息,推荐为每类设备建一个表进行管理。