聚合查询
注意:聚合查询和原始数据查询不能混合使用。下列语句是不支持的:
select a, count(a) from root.sg select sin(a), count(a) from root.sg select a, count(a) from root.sg group by ([10,100),10ms)
内置聚合函数
IoTDB 支持的聚合函数如下:
| 函数名 | 功能描述 | 允许的输入类型 | 输出类型 |
|---|---|---|---|
| SUM | 求和。 | INT32 INT64 FLOAT DOUBLE | DOUBLE |
| COUNT | 计算数据点数。 | 所有类型 | INT |
| AVG | 求平均值。 | INT32 INT64 FLOAT DOUBLE | DOUBLE |
| EXTREME | 求具有最大绝对值的值。如果正值和负值的最大绝对值相等,则返回正值。 | INT32 INT64 FLOAT DOUBLE | 与输入类型一致 |
| MAX_VALUE | 求最大值。 | INT32 INT64 FLOAT DOUBLE | 与输入类型一致 |
| MIN_VALUE | 求最小值。 | INT32 INT64 FLOAT DOUBLE | 与输入类型一致 |
| FIRST_VALUE | 求时间戳最小的值。 | 所有类型 | 与输入类型一致 |
| LAST_VALUE | 求时间戳最大的值。 | 所有类型 | 与输入类型一致 |
| MAX_TIME | 求最大时间戳。 | 所有类型 | Timestamp |
| MIN_TIME | 求最小时间戳。 | 所有类型 | Timestamp |
示例: 统计总点数
select count(status) from root.ln.wf01.wt01;结果:
+-------------------------------+
|count(root.ln.wf01.wt01.status)|
+-------------------------------+
| 10080|
+-------------------------------+
Total line number = 1
It costs 0.016s分层聚合查询
在时间序列层级结构中,分层聚合查询用于对某一层级下同名的序列进行聚合查询。
- 使用
GROUP BY LEVEL = INT来指定需要聚合的层级,并约定ROOT为第 0 层。若统计 "root.ln" 下所有序列则需指定 level 为 1。 - 分层聚合查询支持使用所有内置聚合函数。对于
sum,avg,min_value,max_value,extreme五种聚合函数,需保证所有聚合的时间序列数据类型相同。其他聚合函数没有此限制。
示例1: 不同存储组下均存在名为 status 的序列, 如 "root.ln.wf01.wt01.status", "root.ln.wf02.wt02.status", 以及 "root.sgcc.wf03.wt01.status", 如果需要统计不同存储组下 status 序列的数据点个数,使用以下查询:
select count(status) from root.** group by level = 1运行结果为:
+-------------------------+---------------------------+
|count(root.ln.*.*.status)|count(root.sgcc.*.*.status)|
+-------------------------+---------------------------+
| 20160| 10080|
+-------------------------+---------------------------+
Total line number = 1
It costs 0.003s示例2: 统计不同设备下 status 序列的数据点个数,可以规定 level = 3,
select count(status) from root.** group by level = 3运行结果为:
+---------------------------+---------------------------+
|count(root.*.*.wt01.status)|count(root.*.*.wt02.status)|
+---------------------------+---------------------------+
| 20160| 10080|
+---------------------------+---------------------------+
Total line number = 1
It costs 0.003s注意,这时会将存储组 ln 和 sgcc 下名为 wt01 的设备视为同名设备聚合在一起。
示例3: 统计不同存储组下的不同设备中 status 序列的数据点个数,可以使用以下查询:
select count(status) from root.** group by level = 1, 3运行结果为:
+----------------------------+----------------------------+------------------------------+
|count(root.ln.*.wt01.status)|count(root.ln.*.wt02.status)|count(root.sgcc.*.wt01.status)|
+----------------------------+----------------------------+------------------------------+
| 10080| 10080| 10080|
+----------------------------+----------------------------+------------------------------+
Total line number = 1
It costs 0.003s示例4: 查询所有序列下温度传感器 temperature 的最大值,可以使用下列查询语句:
select max_value(temperature) from root.** group by level = 0运行结果:
+---------------------------------+
|max_value(root.*.*.*.temperature)|
+---------------------------------+
| 26.0|
+---------------------------------+
Total line number = 1
It costs 0.013s示例5: 上面的查询都是针对某一个传感器,特别地,如果想要查询某一层级下所有传感器拥有的总数据点数,则需要显式规定测点为 *
select count(*) from root.ln.** group by level = 2运行结果:
+----------------------+----------------------+
|count(root.*.wf01.*.*)|count(root.*.wf02.*.*)|
+----------------------+----------------------+
| 20160| 20160|
+----------------------+----------------------+
Total line number = 1
It costs 0.013s时间区间分段聚合
分段聚合是一种时序数据典型的查询方式,数据以高频进行采集,需要按照一定的时间间隔进行聚合计算,如计算每天的平均气温,需要将气温的序列按天进行分段,然后计算平均值。
降采样查询是指使用比数据采集的时间频率更低的频率进行的一种查询方式,是分段聚合的一种特例。例如,数据采集的频率是一秒,想按照1分钟对数据进行展示,则需要使用降采样查询。
在 IoTDB 中,可以使用 Group by 子句来进行时间区间分段聚合,支持根据时间间隔和自定义的滑动步长(默认值与时间间隔相同,自定义的值必须大于等于时间间隔)对结果集进行划分,默认结果按照时间升序排列。
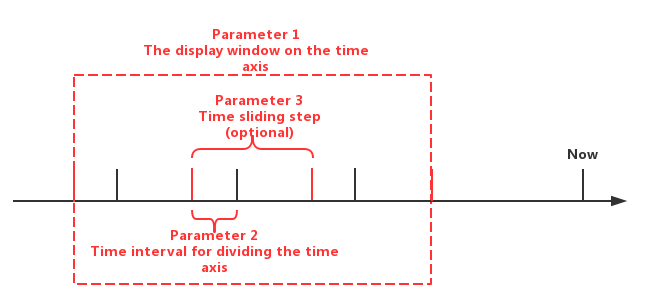
GROUP BY 语句为用户提供三类指定参数:
- 参数 1:时间轴显示时间窗参数
- 参数 2:划分时间轴的时间间隔参数(必须为正数)
- 参数 3:滑动步长(可选参数,默认值与时间间隔相同,自定义的值必须大于等于时间间隔)
三类参数的实际含义已经在下图中指出,这三类参数里,第三个参数是可选的。
接下来,我们将给出三种典型的降频聚合查询的例子:
未指定滑动步长的时间区间分组聚合查询
对应的 SQL 语句是:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);这条查询的含义是:
由于用户没有指定滑动步长,滑动步长将会被默认设置为跟时间间隔参数相同,也就是1d。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1d当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[0,1d), [1d, 2d), [2d, 3d) 等等。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2017-11-07 T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2017-11-07T23:00:00:00 的每一天)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 1440| 26.0|
|2017-11-02T00:00:00.000+08:00| 1440| 26.0|
|2017-11-03T00:00:00.000+08:00| 1440| 25.99|
|2017-11-04T00:00:00.000+08:00| 1440| 26.0|
|2017-11-05T00:00:00.000+08:00| 1440| 26.0|
|2017-11-06T00:00:00.000+08:00| 1440| 25.99|
|2017-11-07T00:00:00.000+08:00| 1380| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.024s指定滑动步长的时间区间分组聚合查询
对应的 SQL 语句是:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);这条查询的含义是:
由于用户指定了滑动步长为1d,GROUP BY 语句执行时将会每次把时间间隔往后移动一天的步长,而不是默认的 3 小时。
也就意味着,我们想要取从 2017-11-01 到 2017-11-07 每一天的凌晨 0 点到凌晨 3 点的数据。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将3h当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-11-01T03:00:00), [2017-11-02T00:00:00, 2017-11-02T03:00:00), [2017-11-03T00:00:00, 2017-11-03T03:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2017-11-07 T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2017-11-07T23:00:00:00 的每一天的凌晨 0 点到凌晨 3 点)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 180| 25.98|
|2017-11-02T00:00:00.000+08:00| 180| 25.98|
|2017-11-03T00:00:00.000+08:00| 180| 25.96|
|2017-11-04T00:00:00.000+08:00| 180| 25.96|
|2017-11-05T00:00:00.000+08:00| 180| 26.0|
|2017-11-06T00:00:00.000+08:00| 180| 25.85|
|2017-11-07T00:00:00.000+08:00| 180| 25.99|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.006s按照自然月份的时间区间分组聚合查询
对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 group by([2017-11-01T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);这条查询的含义是:
由于用户指定了滑动步长为2mo,GROUP BY 语句执行时将会每次把时间间隔往后移动 2 个自然月的步长,而不是默认的 1 个自然月。
也就意味着,我们想要取从 2017-11-01 到 2019-11-07 每 2 个自然月的第一个月的数据。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2019-11-07T23:00:00)。
起始时间为 2017-11-01T00:00:00,滑动步长将会以起始时间作为标准按月递增,取当月的 1 号作为时间间隔的起始时间。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1mo当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-12-01T00:00:00), [2018-02-01T00:00:00, 2018-03-01T00:00:00), [2018-05-03T00:00:00, 2018-06-01T00:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2019-11-07T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2019-11-07T23:00:00:00 的每两个自然月的第一个月)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-01T00:00:00.000+08:00| 259|
|2018-01-01T00:00:00.000+08:00| 250|
|2018-03-01T00:00:00.000+08:00| 259|
|2018-05-01T00:00:00.000+08:00| 251|
|2018-07-01T00:00:00.000+08:00| 242|
|2018-09-01T00:00:00.000+08:00| 225|
|2018-11-01T00:00:00.000+08:00| 216|
|2019-01-01T00:00:00.000+08:00| 207|
|2019-03-01T00:00:00.000+08:00| 216|
|2019-05-01T00:00:00.000+08:00| 207|
|2019-07-01T00:00:00.000+08:00| 199|
|2019-09-01T00:00:00.000+08:00| 181|
|2019-11-01T00:00:00.000+08:00| 60|
+-----------------------------+-------------------------------+对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 group by([2017-10-31T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);这条查询的含义是:
由于用户指定了滑动步长为2mo,GROUP BY 语句执行时将会每次把时间间隔往后移动 2 个自然月的步长,而不是默认的 1 个自然月。
也就意味着,我们想要取从 2017-10-31 到 2019-11-07 每 2 个自然月的第一个月的数据。
与上述示例不同的是起始时间为 2017-10-31T00:00:00,滑动步长将会以起始时间作为标准按月递增,取当月的 31 号(即最后一天)作为时间间隔的起始时间。若起始时间设置为 30 号,滑动步长会将时间间隔的起始时间设置为当月 30 号,若不存在则为最后一天。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-10-31T00:00:00, 2019-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1mo当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-10-31T00:00:00, 2017-11-31T00:00:00), [2018-02-31T00:00:00, 2018-03-31T00:00:00), [2018-05-31T00:00:00, 2018-06-31T00:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-10-31T00:00:00, 2019-11-07T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-10-31T00:00:00 到 2019-11-07T23:00:00:00 的每两个自然月的第一个月)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-10-31T00:00:00.000+08:00| 251|
|2017-12-31T00:00:00.000+08:00| 250|
|2018-02-28T00:00:00.000+08:00| 259|
|2018-04-30T00:00:00.000+08:00| 250|
|2018-06-30T00:00:00.000+08:00| 242|
|2018-08-31T00:00:00.000+08:00| 225|
|2018-10-31T00:00:00.000+08:00| 216|
|2018-12-31T00:00:00.000+08:00| 208|
|2019-02-28T00:00:00.000+08:00| 216|
|2019-04-30T00:00:00.000+08:00| 208|
|2019-06-30T00:00:00.000+08:00| 199|
|2019-08-31T00:00:00.000+08:00| 181|
|2019-10-31T00:00:00.000+08:00| 69|
+-----------------------------+-------------------------------+左开右闭区间
每个区间的结果时间戳为区间右端点,对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);这条查询语句的时间区间是左开右闭的,结果中不会包含时间点 2017-11-01 的数据,但是会包含时间点 2017-11-07 的数据。
SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------------+
Total line number = 7
It costs 0.004s时间区间和路径层级混合聚合查询
除此之外,还可以通过定义 LEVEL 来统计指定层级下的数据点个数。
例如:
统计降采样后的数据点个数
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d), level=1;结果:
+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.006s加上滑动 Step 的降采样后的结果也可以汇总
select count(status) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d), level=1;+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-01T00:00:00.000+08:00| 180|
|2017-11-02T00:00:00.000+08:00| 180|
|2017-11-03T00:00:00.000+08:00| 180|
|2017-11-04T00:00:00.000+08:00| 180|
|2017-11-05T00:00:00.000+08:00| 180|
|2017-11-06T00:00:00.000+08:00| 180|
|2017-11-07T00:00:00.000+08:00| 180|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.004s