Data Partitioning & Load Balancing
Data Partitioning & Load Balancing
This document introduces the partitioning strategies and load balance strategies in IoTDB. According to the characteristics of time series data, IoTDB partitions them by series and time dimensions. Combining a series partition with a time partition creates a partition, the unit of division. To enhance throughput and reduce management costs, these partitions are evenly allocated to RegionGroups, which serve as the unit of replication. The RegionGroup's Regions then determine the storage location, with the leader Region managing the primary load. During this process, the Region placement strategy determines which nodes will host the replicas, while the leader selection strategy designates which Region will act as the leader.
1. Partitioning Strategy & Partition Allocation
IoTDB implements tailored partitioning algorithms for time series data. Building on this foundation, the partition information cached on both ConfigNodes and DataNodes is not only manageable in size but also clearly differentiated between hot and cold. Subsequently, balanced partitions are evenly allocated across the cluster's RegionGroups to achieve storage balance.
1.1 Partitioning Strategy
IoTDB maps each sensor in the production environment to a time series. The time series are then partitioned using the series partitioning algorithm to manage their schema, and combined with the time partitioning algorithm to manage their data. The following figure illustrates how IoTDB partitions time series data.
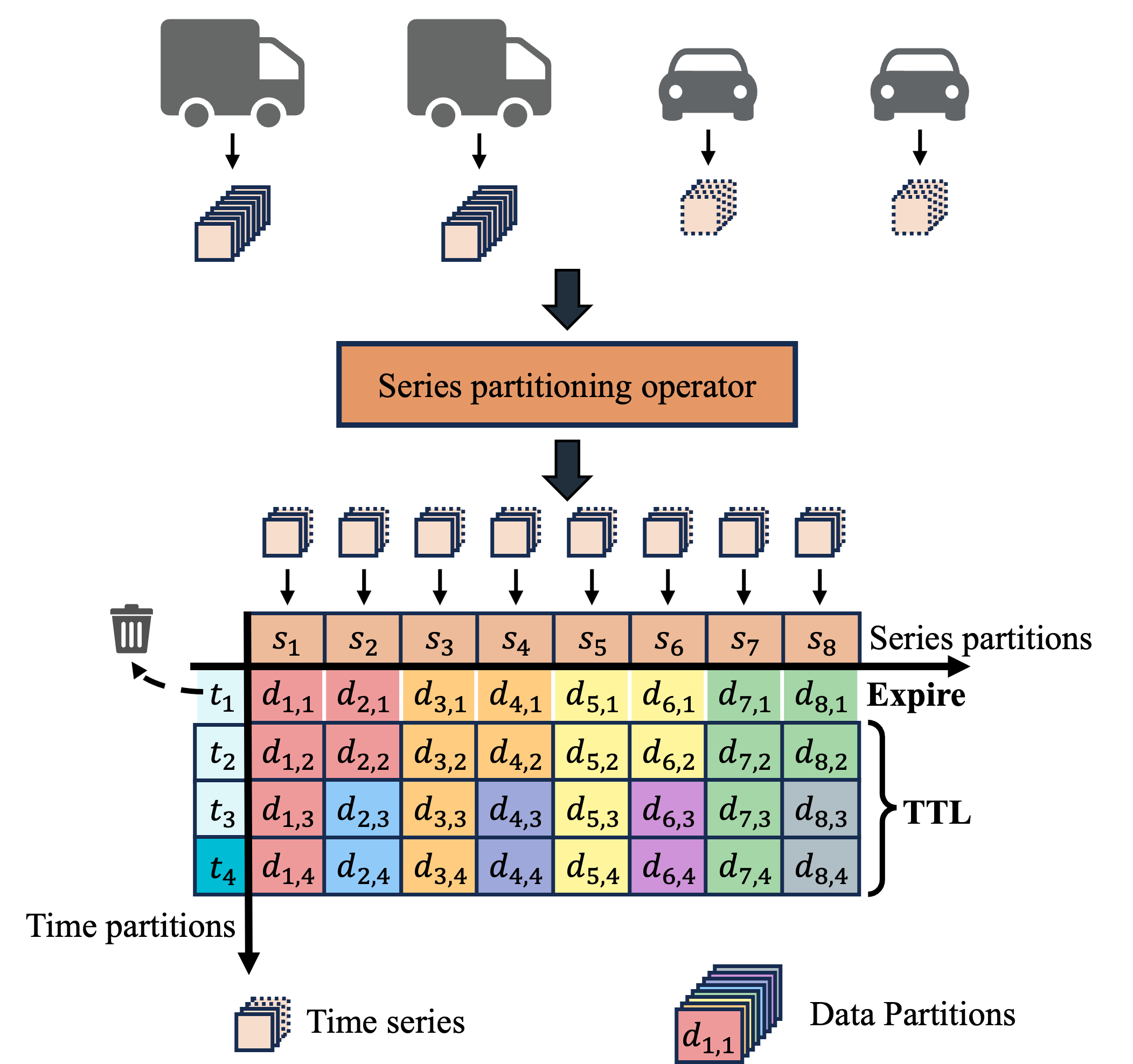
Partitioning Algorithm
Because numerous devices and sensors are commonly deployed in production environments, IoTDB employs a series partitioning algorithm to ensure the size of partition information is manageable. Since the generated time series associated with timestamps, IoTDB uses a time partioning algorithm to clearly distinguish between hot and cold partitions.
Series Partitioning Algorithm
By default, IoTDB limits the number of series partitions to 1000 and configures the series partitioning algorithm to use a hash partitioning algorithm. This leads to the following outcomes:
- Since the number of series partitions is a fixed constant, the mapping between series and series partitions remains stable. As a result, IoTDB does not require frequent data migrations.
- The load across series partitions is relatively balanced because the number of series partitions is much smaller than the number of sensors deployed in the production environment.
Furthermore, if a more accurate estimate of the actual load in the production environment is available, the series partitioning algorithm can be configured to use a customized hash partitioning or a list partitioning to achieve a more uniform load distribution across all series partitions.
Time Partitioning Algorithm
The time partitioning algorithm converts a given timestamp to the corresponding time partition by
In this equation, both and are configurable parameters to accommodate various production environments. The represents the starting time of the first time partition, while the defines the duration of each time partition. By default, the is set to seven day.
Schema Partitioning
Since the series partitioning algorithm evenly partitions the time series, each series partition corresponds to a schema partition. These schema partitions are then evenly allocated across the SchemaRegionGroups to achieve a balanced schema distribution.
Data Partitioning
Combining a series partition with a time partition creates a data partition. Since the series partitioning algorithm evenly partitions the time series, the load of data partitions within a specified time partition remains balanced. These data partitions are then evenly allocated across the DataRegionGroups to achieve balanced data distribution.
1.2 Partition Allocation
IoTDB uses RegionGroups to enable elastic storage of time series, with the number of RegionGroups in the cluster determined by the total resources available across all DataNodes. Since the number of RegionGroups is dynamic, IoTDB can easily scale out. Both the SchemaRegionGroup and DataRegionGroup follow the same partition allocation algorithm, which evenly splits all series partitions. The following figure demonstrates the partition allocation process, where the dynamic RegionGroups match the variously expending time series and cluster.
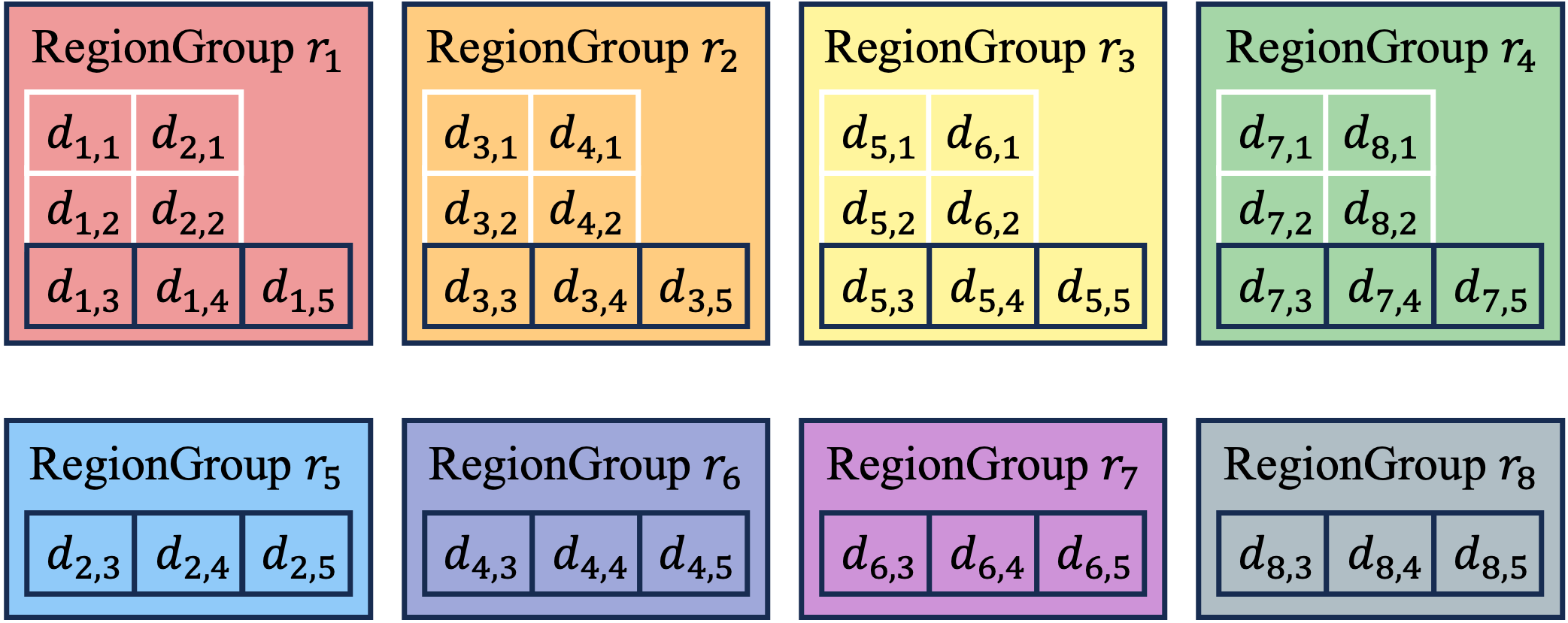
RegionGroup Expansion
The number of RegionGroups is given by
In this equation, represents the number of Regions expected to be hosted on the -th DataNode, while denotes the number of Regions within each RegionGroup. Both and are configurable parameters. The can be determined by the available hardware resources---such as CPU cores, memory sizes, etc.---on the -th DataNode to accommodate different physical servers. The can be adjusted to ensure diverse levels of fault tolerance.
Allocation Algorithm
Both the SchemaRegionGroup and the DataRegionGroup follow the same allocation algorithm--splitting all series partitions evenly. As a result, each SchemaRegionGroup holds the same number of schema partitions, ensuring balanced schema storage. Similarly, for each time partition, each DataRegionGroup acquires the data partitions corresponding to the series partitions it holds. Consequently, the data partitions within a time partition are evenly distributed across all DataRegionGroups, ensuring balanced data storage in each time partition.
Notably, IoTDB effectively leverages the characteristics of time series data. When the TTL (Time to Live) is configured, IoTDB enables migration-free elastic storage for time series data. This feature facilitates cluster expansion while minimizing the impact on online operations. The figures above illustrate an instance of this feature: newborn data partitions are evenly allocated to each DataRegion, and expired data are automatically archived. As a result, the cluster's storage will eventually remain balanced.
2. Balance Strategy
To enhance the cluster's availability and performance, IoTDB employs sophisticated storage load and computing load balance algorithms.
2.1 Storage Load Balance
The number of Regions held by a DataNode reflects its storage load. If the difference in the number of Regions across DataNodes is relatively large, the DataNode with more Regions is likely to become a storage bottleneck. Although a straightforward Round Robin placement algorithm can achieve storage balance by ensuring that each DataNode hosts an equal number of Regions, it compromises the cluster's fault tolerance, as illustrated below:
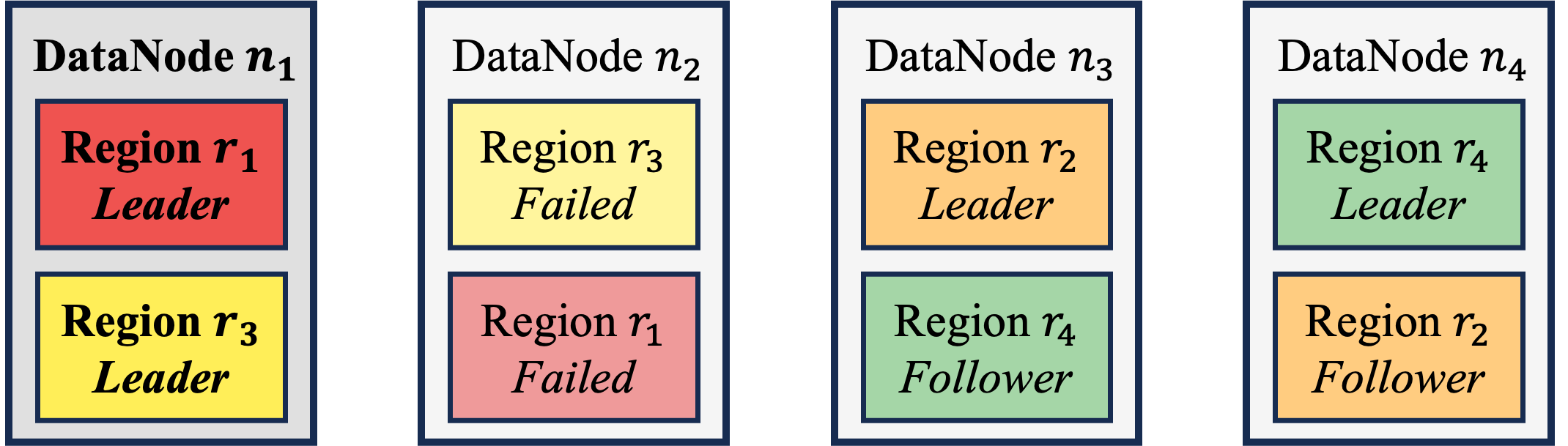
- Assume the cluster has 4 DataNodes, 4 RegionGroups and a replication factor of 2.
- Place RegionGroup 's 2 Regions on DataNodes and .
- Place RegionGroup 's 2 Regions on DataNodes and .
- Place RegionGroup 's 2 Regions on DataNodes and .
- Place RegionGroup 's 2 Regions on DataNodes and .
In this scenario, if DataNode fails, the load previously handled by DataNode would be transferred solely to DataNode , potentially overloading it.
To address this issue, IoTDB employs a Region placement algorithm that not only evenly distributes Regions across all DataNodes but also ensures that each DataNode can offload its storage to sufficient other DataNodes in the event of a failure. As a result, the cluster achieves balanced storage distribution and a high level of fault tolerance, ensuring its availability.
2.2 Computing Load Balance
The number of leader Regions held by a DataNode reflects its Computing load. If the difference in the number of leaders across DataNodes is relatively large, the DataNode with more leaders is likely to become a Computing bottleneck. If the leader selection process is conducted using a transparent Greedy algorithm, the result may be an unbalanced leader distribution when the Regions are fault-tolerantly placed, as demonstrated below:
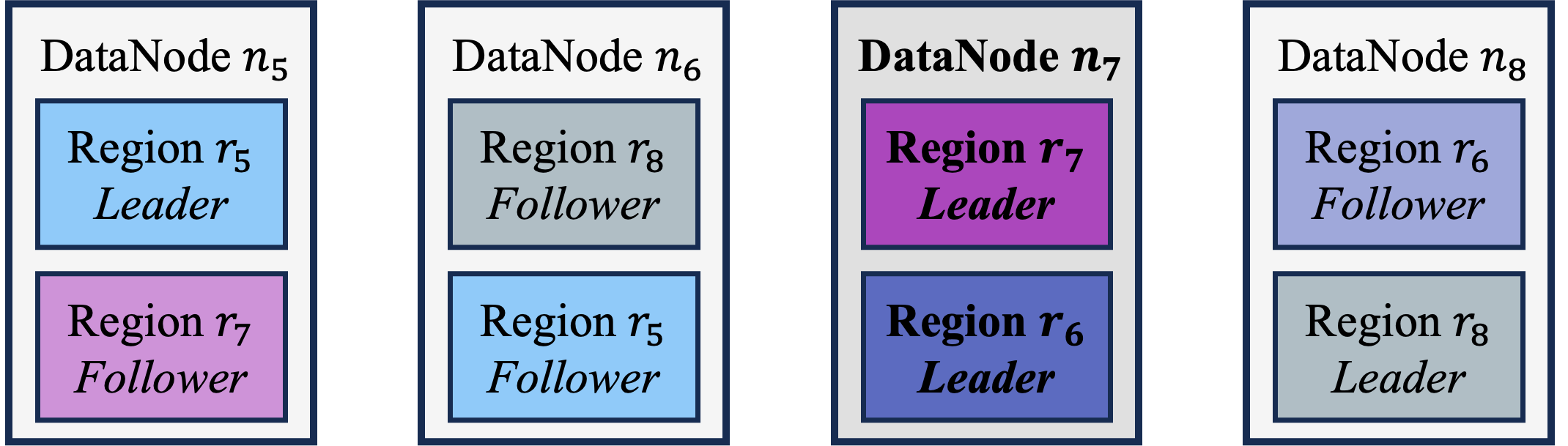
- Assume the cluster has 4 DataNodes, 4 RegionGroups and a replication factor of 2.
- Select RegionGroup 's Region on DataNode as the leader.
- Select RegionGroup 's Region on DataNode as the leader.
- Select RegionGroup 's Region on DataNode as the leader.
- Select RegionGroup 's Region on DataNode as the leader.
Please note that all the above steps strictly follow the Greedy algorithm. However, by Step 3, selecting the leader of RegionGroup on either DataNode or results in an unbalanced leader distribution. The rationale is that each greedy step lacks a global perspective, leading to a locally optimal solution.
To address this issue, IoTDB employs a leader selection algorithm that can consistently balance the cluster's leader distribution. Consequently, the cluster achieves balanced Computing load distribution, ensuring its performance.
3. Source Code
4. Appendix
- [1] Chen R, Hu X, Huang X, et al. Migration-Free Elastic Storage of Time Series in Apache IoTDB[J]. Proceedings of the VLDB Endowment, 2025, 18(6): 1784-1797.