Cluster Maintenance
Cluster Maintenance
1. Cluster Scaling
When an IoTDB cluster encounters resource bottlenecks such as CPU, memory, disk, or network due to a surge in data volume or access pressure, this guide can be used for horizontal scaling to enhance the overall performance and capacity of the cluster.
1.1 Core Concepts
Before performing scaling operations, it is necessary to understand concepts related to IoTDB cluster architecture, series partitioning, time partitioning, and more.
1.1.1 Glossary of Terms
| Term | Type | Explanation |
|---|---|---|
| ConfigNode | Node Role | Management node, responsible for managing cluster information, including recording partition information, load balancing, operation scheduling, and node management. |
| DataNode | Node Role | Data node, responsible for providing data read/write services for clients, and comprehensively managing data and metadata. Data nodes form different replica groups. |
| Database | Metadata | Database, where data in different databases is physically isolated. |
| DeviceId | Device Name | The full path from the root to the second-to-last level in the metadata tree represents a DeviceId. |
| SeriesSlot | Series Partition Slot | Each Database corresponds to a fixed number of series slots, containing the metadata of the series within it. |
| SeriesTimeSlot | A Time Partition Slot of a Series Slot | Corresponds to the data of all series within a SeriesSlot for one time partition. |
| SchemaRegion | A Set of Metadata Partitions | A collection of multiple SeriesSlots. The metadata management engine on a DataNode, providing read/write operations for metadata. |
| DataRegion | A Set of Data Partitions | A collection of multiple SeriesTimeSlots. The data management engine on a DataNode, providing data read/write operations. |
| ConfigNodeGroup | Logical Concept (Consensus Group) | Composed of all ConfigNode nodes in the cluster, maintaining consistent partition table information through a consensus protocol. |
| SchemaRegionGroup | Logical Concept (Consensus Group) | Metadata replica group, containing the same number of SchemaRegions as the metadata replica count. It manages the same metadata, serving as backups for each other. |
| DataRegionGroup | Logical Concept (Consensus Group) | Data replica group, containing the same number of DataRegions as the data replica count. It manages the same data, serving as backups for each other. It is the fundamental unit of the IoTDB cluster's throughput capacity. |
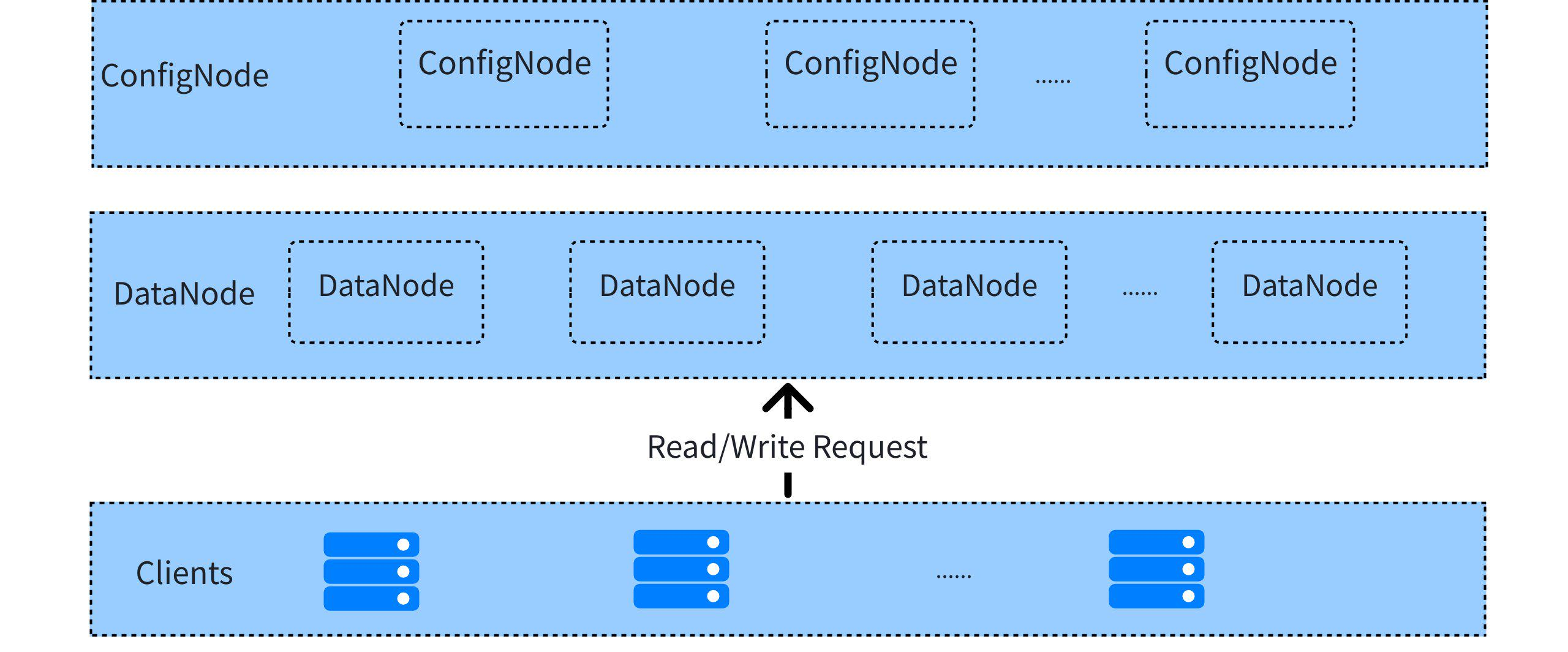
1.1.2 Cluster Architecture
The IoTDB cluster consists of management nodes (ConfigNode) and data nodes (DataNode), employing an MPP architecture to achieve large-scale parallel processing. Its core feature lies in partitioning metadata at the device level and partitioning data in two dimensions (device and time), ensuring comprehensive scalability.
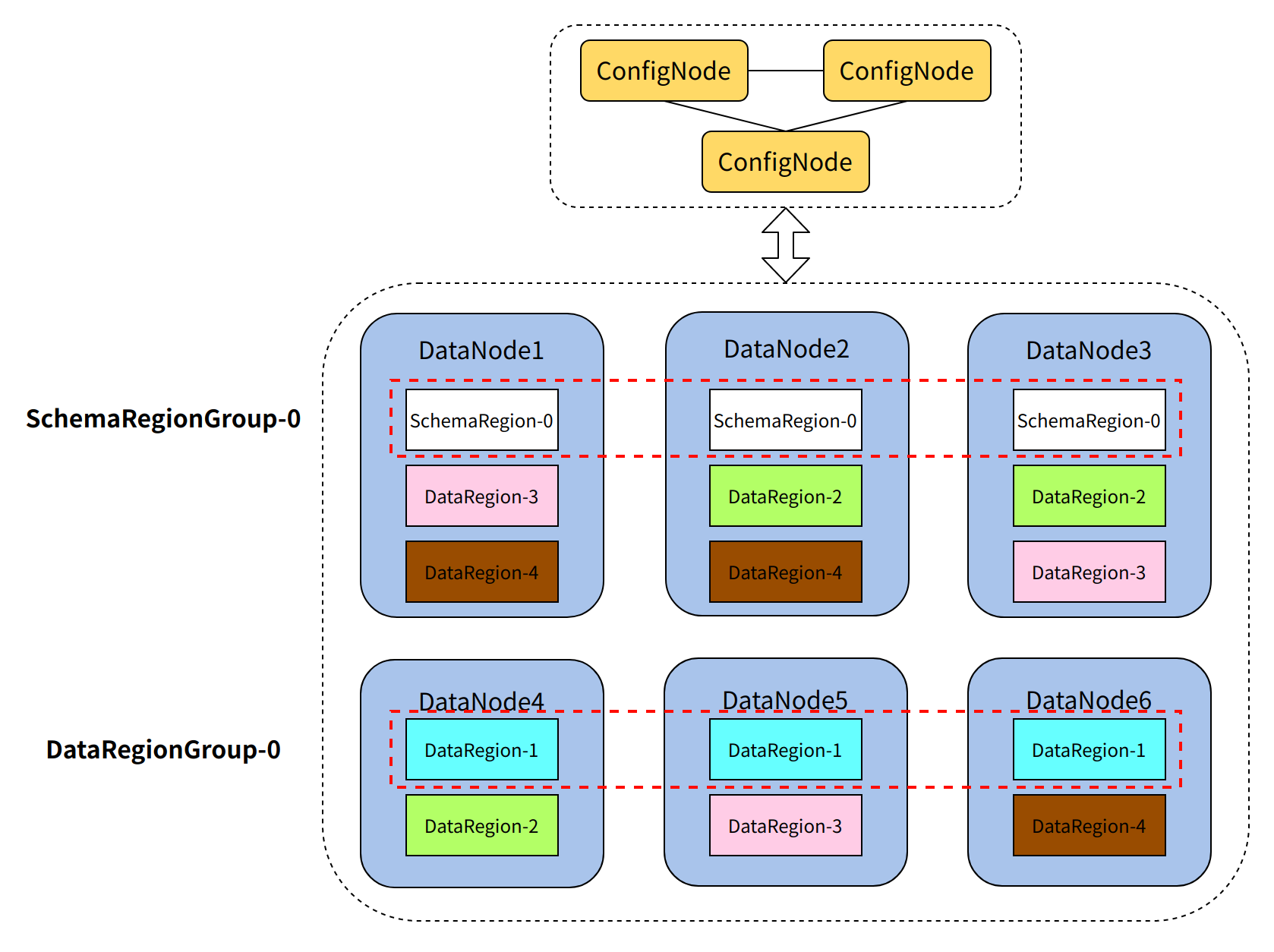
1.1.3 Partition Management
Cluster Consensus Groups
In IoTDB, data partition groups (DataRegionGroup) and metadata partition groups (SchemaRegionGroup) are the smallest units for read/write load, ensuring data consistency through the consensus group mechanism. Therefore, the essence of cluster scaling is to increase data partitions to enhance concurrent processing capability and throughput.
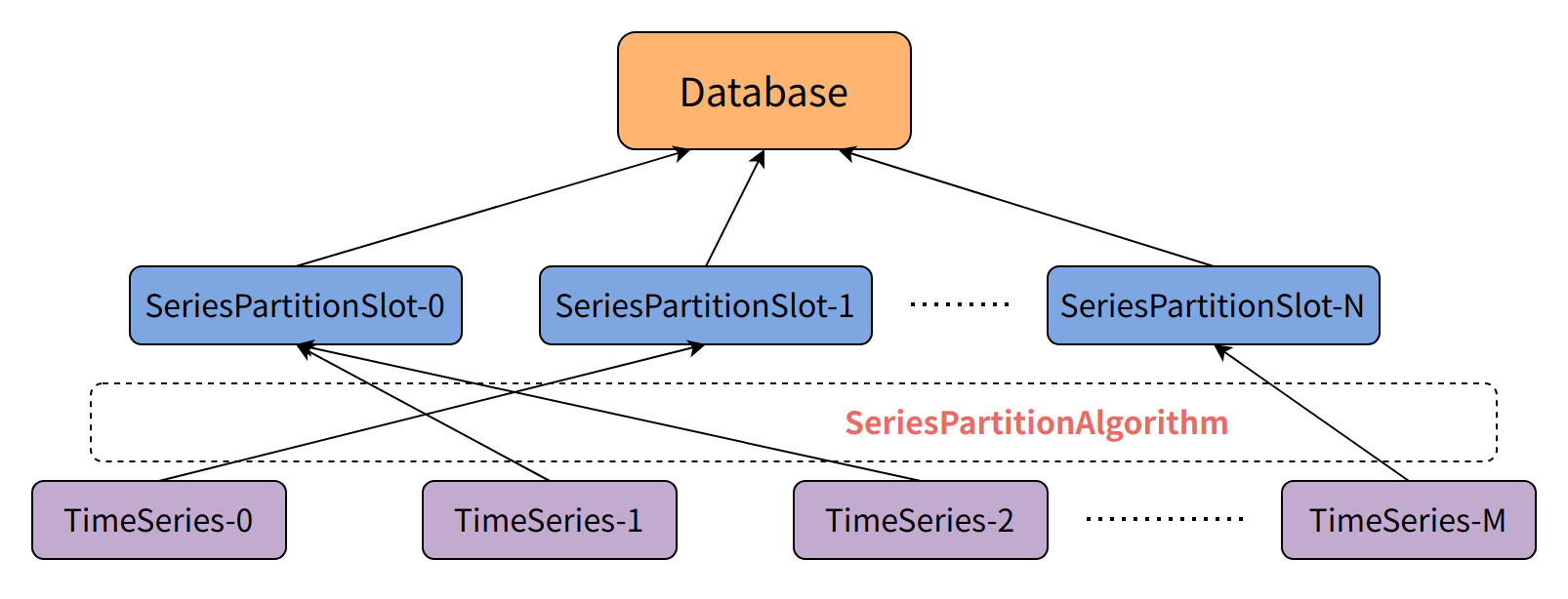
Slot Mechanism for Partitioning
To support scaling and efficient distributed management, IoTDB introduces two core slot mechanisms for partitioning and load scheduling.
The first is the Series Partition Slot, a mechanism for vertically managing time series. Each database holds a fixed number of series partition slots (default 1000). Each time series is assigned to a unique series partition slot via a series partitioning algorithm. Using series partition slots avoids directly recording partition information at the device or time series level, significantly reducing ConfigNode memory overhead.
The second is the Time Partition Slot, used for horizontally splitting time series data. Each data partition consists of the combination of a series partition slot and a time partition slot. When a specific series partition slot has data within a particular time partition slot, the corresponding data partition is generated.
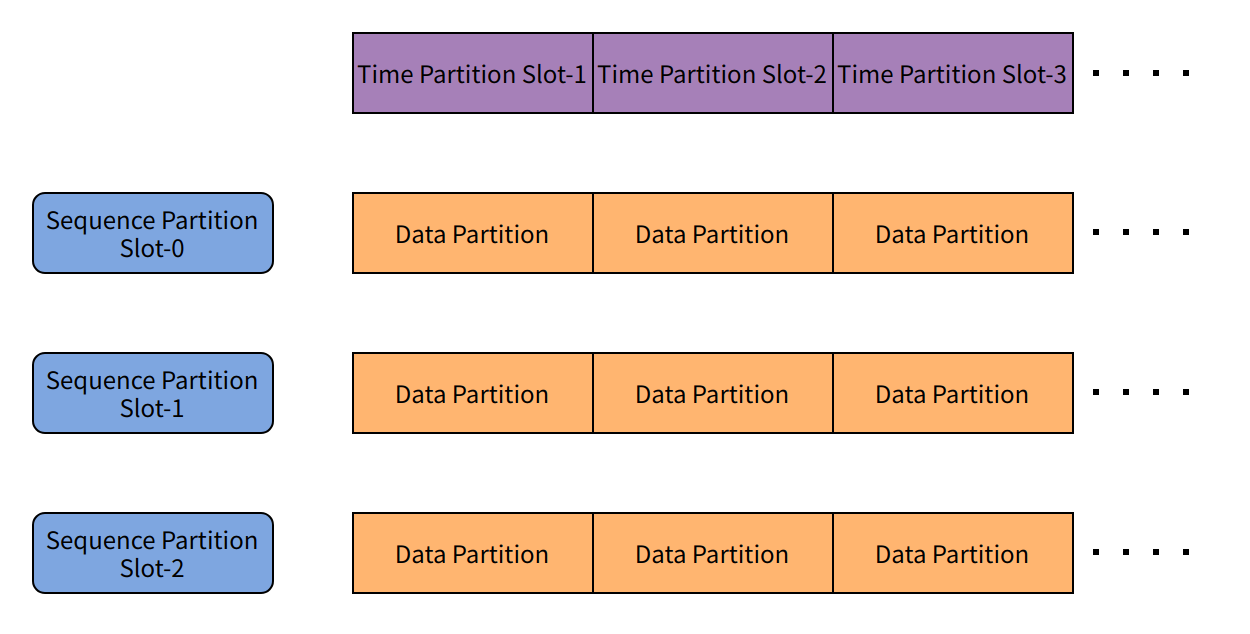
Through the combination of series partition slots and time partition slots, IoTDB can flexibly increase data partition groups during scaling, achieving balanced data distribution and efficient read/write operations, thereby enhancing the entire cluster's throughput capacity and scalability.
1.2 Implementation Principle
The core of IoTDB cluster scaling is adding DataNode nodes, as DataNodes are the primary nodes handling read/write requests. The internal data partitions (DataRegions) are the key units bearing the load. The essence of scaling is to increase the cluster's concurrent processing capability and throughput by adding data partition groups.
By default, assuming the cluster's metadata replica count is three and the data replica count is two, the number of data partitions created upon initial startup is half the total number of cluster cores. For example, in a cluster of three 2-core servers, assuming the processing capacity of each data replica group is 1, the total throughput capacity of this cluster (containing 3 data replica groups) is 3. Therefore, scaling the number of servers from three to six expands the cluster from three to six data replica groups, effectively doubling the total throughput capacity.
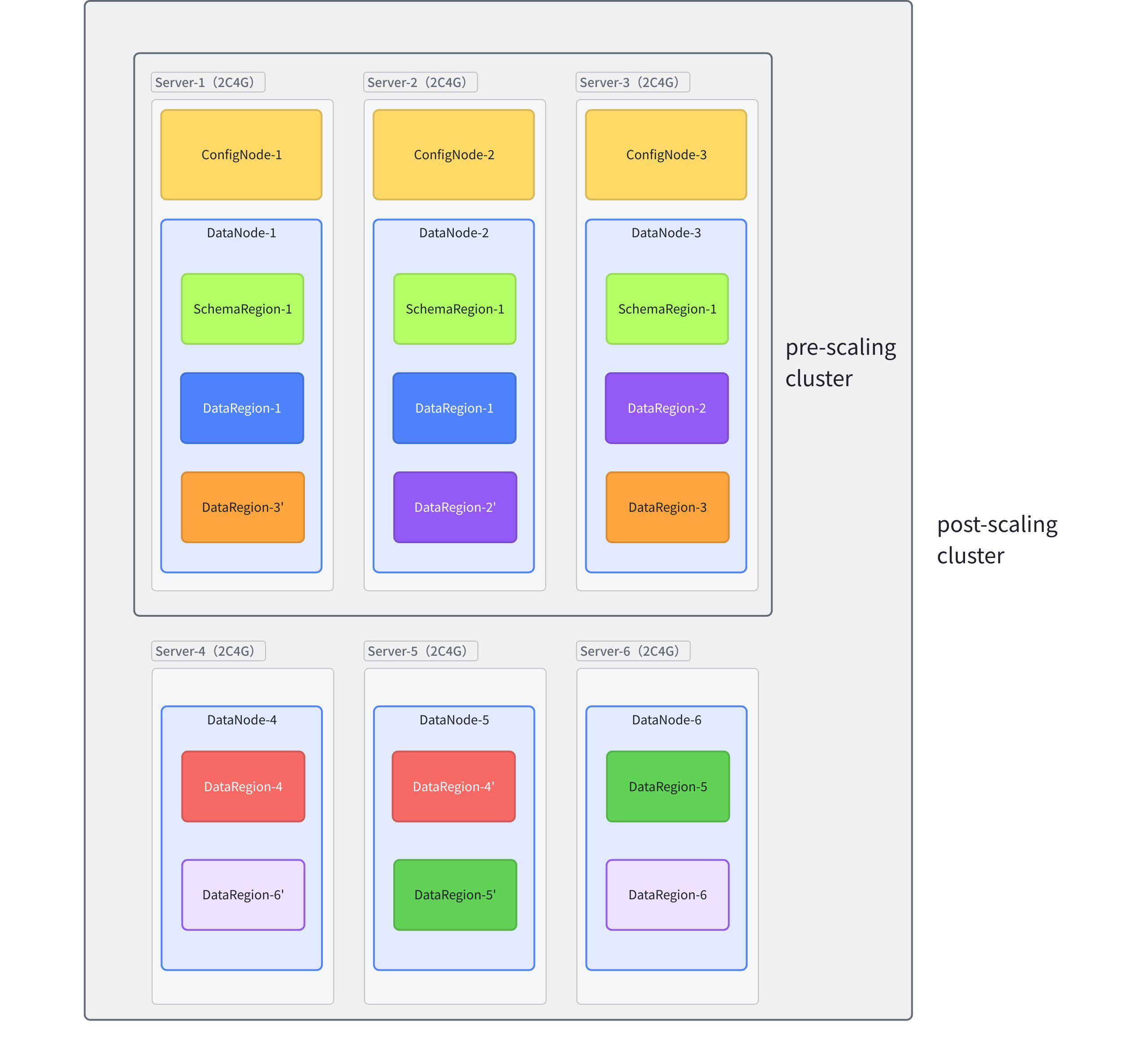
After scaling, the load balancing rule for client read/write requests is that existing nodes may handle data reads and writes for both old data (data belonging to DeviceIds already existing in the cluster) and new data (data belonging to DeviceIds not previously existing in the cluster), while newly added nodes will only receive requests for the new data. The existing nodes do not automatically rebalance the original replica groups. Data load balancing typically occurs when a new time partition is created, scheduled by default for 8 AM every Thursday. Its core principle involves the load balancing algorithm operating on series partition slots and time partition slots to determine which node's partition handles the data.
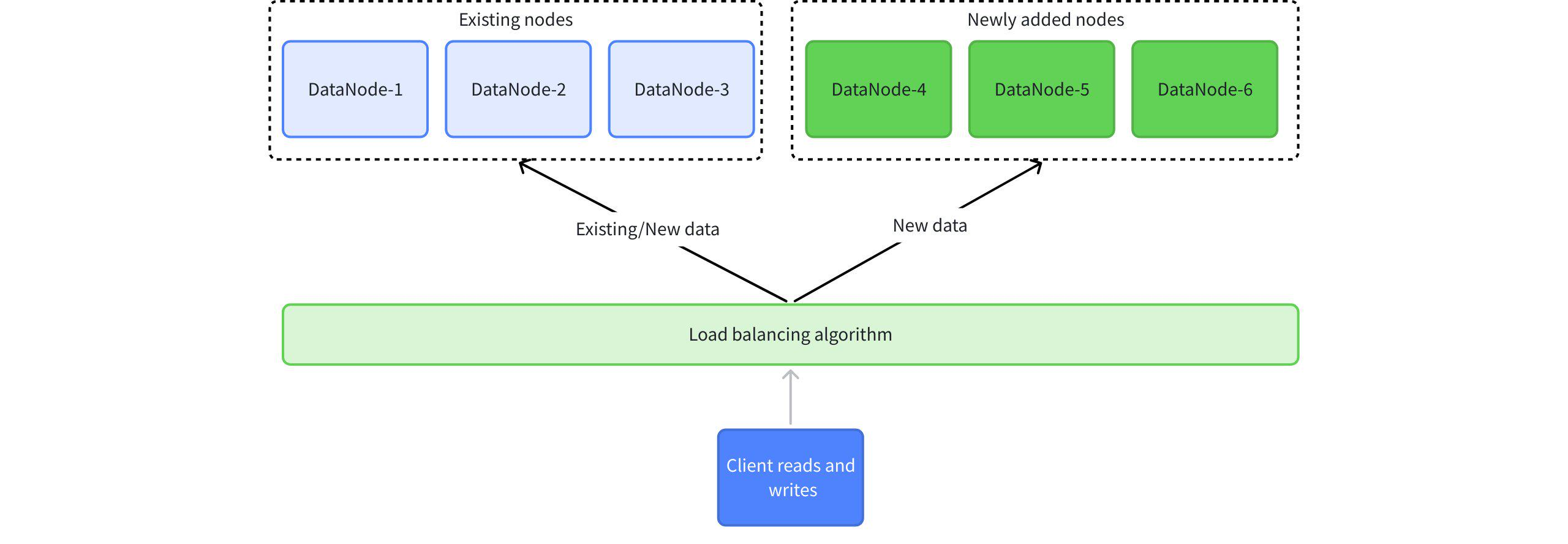
If you wish to rebalance all data (both old and new) after scaling, you need to use the manual data partition migration function (referred to as Region Migration).
Region Migration syntax reference:
-- Explanation: Migrate the data of which RegionId from which source DataNodeId to which target DataNodeId
migrateRegion
: MIGRATE REGION regionId=INTEGER_LITERAL FROM fromId=INTEGER_LITERAL TO toId=INTEGER_LITERAL
;During migration, the ConfigNode is responsible for overall scheduling. The source region and source DataNode provide the data to be removed, while the new region and new DataNode handle the added data.
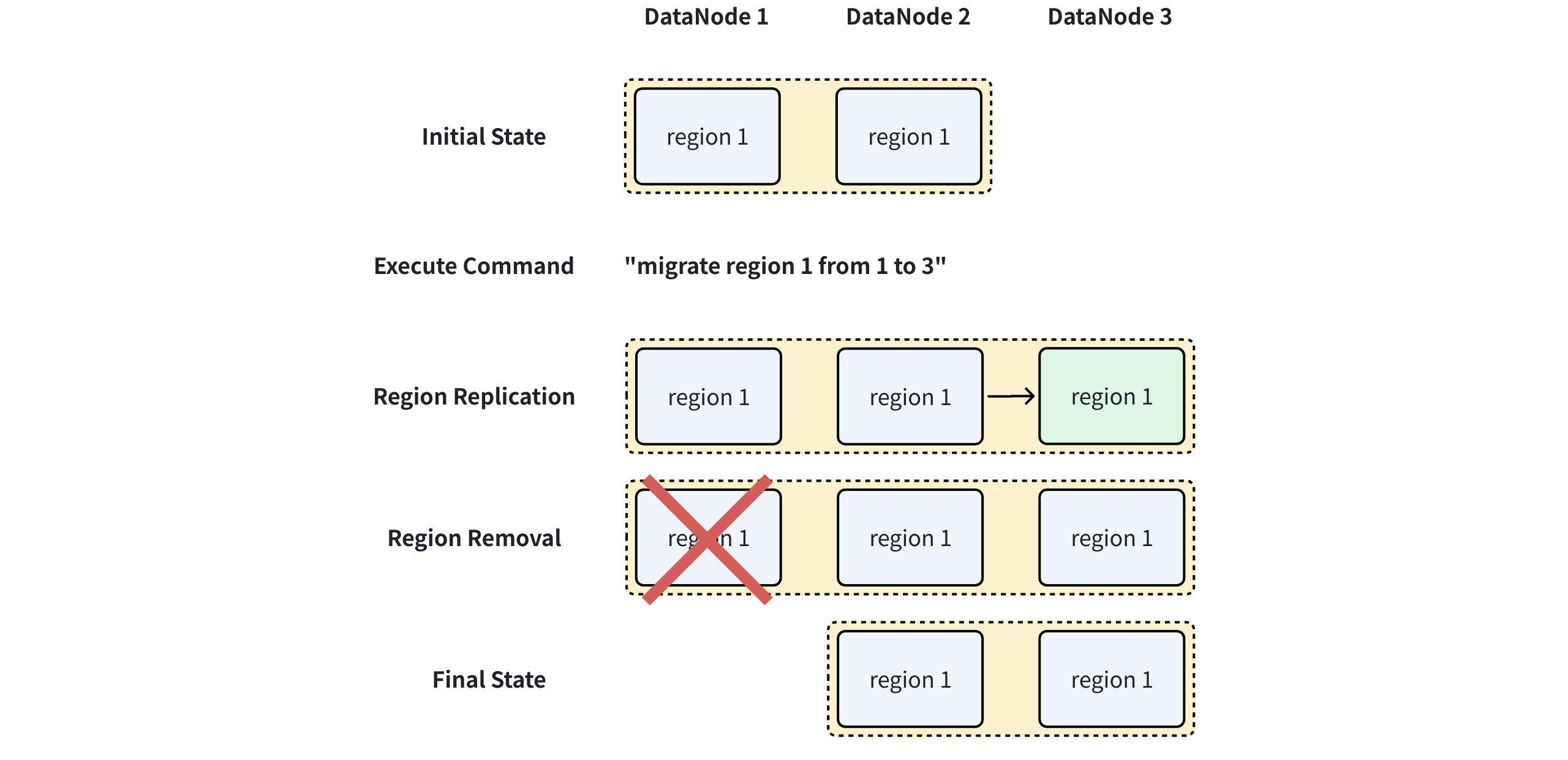
In the cluster composed of 3 DataNodes shown above, the region 1 replica group is distributed across DataNode 1 and DataNode 2. Assuming you want to migrate the region 1 replica from DataNode 1 to DataNode 3, the operation flow is as follows:
- Execute the following command in the CLI:
migrate region 1 from 1 to 3- The Region migration enters the Region Replication stage. The core task of this stage is to create a new region replica on the target node and synchronize the full data of region 1. The region status at this point is
Adding. - Next, the migration enters the Region Removal stage. Once the data on the target node is fully synchronized, the data on the old region node can be safely deleted. Therefore, the core task of this step is to remove all data from the old node to free up disk space. The region status at this point is
Removing. - After steps 2 and 3 are completed, the entire Region migration operation is finished.
1.3 Operational Steps
1.3.1 Prerequisites
Check the server environment. It is recommended that the operating system version matches that of the original cluster.
Verify the database version. It is recommended to use the same version as the original cluster.
Check the OS environment to ensure required ports are not occupied. DataNode uses ports 6667, 10730, 10740, 10750, 10760, 9090, 9190, 3000. Ensure these ports are free.
# If the command has output, the port is occupied. lsof -i:6667 or netstat -tunp | grep 6667 lsof -i:10710 or netstat -tunp | grep 10710 lsof -i:10720 or netstat -tunp | grep 10720Check the data directory. Ensure the server has mounted a data disk; it is recommended to place the installation package in the data disk directory.
Software Dependency: Install Java Runtime Environment (JRE), version >= 1.8. Ensure the JDK/JRE environment variables are set.
Domain Configuration: It is recommended to prioritize using hostnames for IP configuration during deployment. This can prevent issues with the database failing to start due to later changes in the host IP. To set the hostname, configure
/etc/hostson the target server. For example, if the local IP is 192.168.1.3 and the hostname isiotdb-1, you can set the server's hostname using the following command. Then, use the hostname to configure IoTDB'scn_internal_address,dn_internal_address, anddn_rpc_address.
# Note: Both the new server and the original cluster nodes need domain configuration.
echo "192.168.1.3 iotdb-1" >> /etc/hosts1.3.2 Scaling Operation
- To ensure the IoTDB installation package you obtained is complete and correct, it is recommended to perform an SHA512 checksum before installation and deployment.
- Unzip the installation package and enter the installation directory.
unzip apache-iotdb-{version}-bin.zip
cd apache-iotdb-{version}-bin- Modify the relevant configuration.
cd apache-iotdb-{version}-bin/conf
vim iotdb-system.properties| Configuration Item | Description | Default | Remarks |
|---|---|---|---|
dn_seed_config_node | The ConfigNode address (format:cn_internal_address:cn_internal_port) that a node connects to when registering to join the cluster. | 127.0.0.1:10710 | Extremely important. You must modify this item to the address of the primary ConfigNode in the original cluster. |
dn_rpc_address | Address for the client RPC service. | 0.0.0.0 | Modify as needed; restart service to take effect. |
dn_rpc_port | Port for the client RPC service. | 6667 | Modify as needed; restart service to take effect. |
dn_internal_address | Address used by the DataNode for internal cluster communication. | 127.0.0.1 | Modify as needed; cannot be changed after the first startup. |
dn_internal_port | Port used by the DataNode for internal cluster communication. | 10730 | Modify as needed; cannot be changed after the first startup. |
dn_mpp_data_exchange_port | Port used by the DataNode for receiving data streams. | 10740 | Modify as needed; restart service to take effect. |
dn_data_region_consensus_port | Port used by the DataNode for consensus protocol communication of data replicas. | 10750 | Modify as needed; restart service to take effect. |
dn_schema_region_consensus_port | Port used by the DataNode for consensus protocol communication of metadata replicas. | 10760 | Modify as needed; restart service to take effect. |
- Start the DataNode.
Navigate to the sbindirectory under IoTDB and start the datanode:
# Unix/OS X
./sbin/start-datanode.sh -d # The "-d" parameter starts the process in the background.
# Windows
# Before version V2.0.4.x
.\sbin\start-datanode.bat
# V2.0.4.x and later versions
.\sbin\windows\start-datanode.bat- Connect to the original cluster via CLI command for post-scaling verification.
# Linux or macOS
./apache-iotdb-{version}-bin/sbin/start-cli.sh
# Windows
# Before version V2.0.4.x
.\apache-iotdb-{version}-bin\sbin\start-cli.bat
# V2.0.4.x and later versions
.\apache-iotdb-{version}-bin\sbin\windows\start-cli.bat- Execute commands for verification.
Execute the show datanodescommand for verification. The expected result is that the newly added node appears in the list with a status of Running.
IoTDB> show datanodes
+------+-------+----------+-------+-------------+---------------+
|NodeID| Status|RpcAddress|RpcPort|DataRegionNum|SchemaRegionNum|
+------+-------+----------+-------+-------------+---------------+
| 1|Running| 0.0.0.0| 6667| 0| 0|
| 2|Running| 0.0.0.0| 6668| 1| 1|
| 3|Running| 0.0.0.0| 6669| 1| 0|
| 4|Running| 0.0.0.0| 6669| 1| 0| # Newly added node
+------+-------+----------+-------+-------------+---------------+
Total line number = 4
It costs 0.110s- Repeat the above steps for other nodes. It is important to note that for a new node to join the original cluster successfully, the original cluster must have sufficient allowance for additional DataNode nodes.
1.3.3 Manual Load Balancing (Optional)
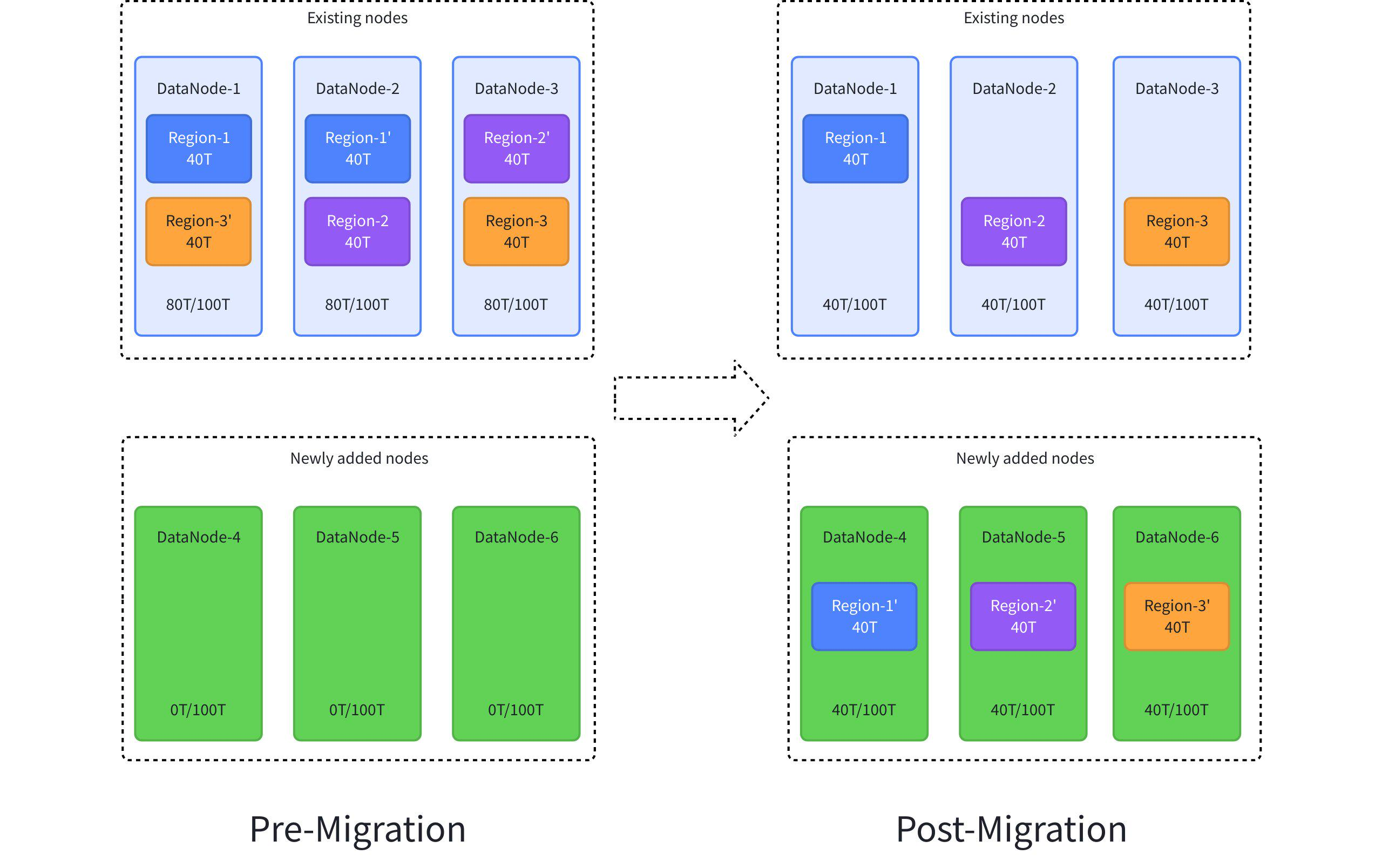
By default, historical data is not automatically migrated after scaling. If you need to balance the data distribution across nodes, you must manually migrate Regions. The estimated migration time is: Region data volume ÷ actual data transfer rate. As shown in the figure below, assuming 80TB of data load from existing nodes needs to be balanced to newly added nodes, if the data volume of a single Region is 1 TB and the transfer speed is 100 MB/s, the migration will take approximately 3 hours.
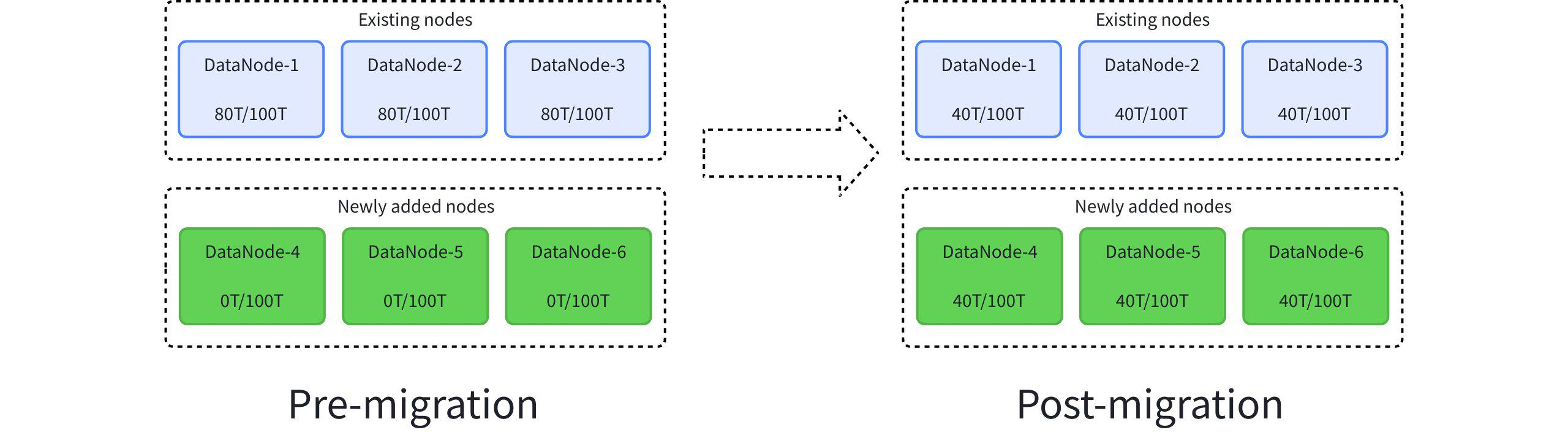
The specific operations are as follows:
-- 1. Migrate the replica data of Region-1 from DataNode-2 to DataNode-4
migrate region 1 from 2 to 4
-- 2. Migrate the replica data of Region-2 from DataNode-3 to DataNode-5
migrate region 2 from 3 to 5
-- 3. Migrate the replica data of Region-3 from DataNode-1 to DataNode-6
migrate region 3 from 1 to 6After the migration is complete, the Region data in the system will be redistributed between the old nodes and the new nodes, achieving balanced disk space usage and optimal resource utilization.
2. Node Management
Node management is mainly used to remove and add ConfigNodes and DataNodes in a cluster. It is a basic operation to ensure cluster high availability and achieve load balancing.
2.1 ConfigNode Maintenance
ConfigNode maintenance includes two operations: adding and removing ConfigNodes. There are two common usage scenarios:
- Cluster scaling: When there is only 1 ConfigNode in the cluster and you want to increase the high availability of ConfigNodes, you can add 2 more ConfigNodes so that the cluster has 3 ConfigNodes.
- Cluster fault recovery: When the machine hosting a ConfigNode fails and the ConfigNode cannot run properly, you can remove the faulty ConfigNode and add a new ConfigNode to the cluster.
❗️ Note: After completing ConfigNode maintenance, ensure the cluster has 1 or 3 normally running ConfigNodes.
2 ConfigNodes do not provide high availability, and more than 3 ConfigNodes will cause performance degradation.
2.1.1 Adding a ConfigNode
Script commands:
# Linux / MacOS
# First switch to the IoTDB root directory
sbin/start-confignode.sh
# Windows
# First switch to the IoTDB root directory
# Before V2.0.4.x
sbin\start-confignode.bat
# V2.0.4.x and later
sbin\windows\start-confignode.batParameter description:
| Param | Description | Required |
|---|---|---|
| -v | Show version information | No |
| -f | Run the script in the foreground, not in the background | No |
| -d | Start in daemon mode (run in the background) | No |
| -p | Specify a file to store the process ID for process management | No |
| -c | Specify the path of the configuration folder to load configuration files | No |
| -g | Print detailed garbage collection (GC) information | No |
| -H | Specify the path for Java heap dump files on JVM out-of-memory | No |
| -E | Specify the path for JVM error log files | No |
| -D | Define system properties in the format key=value | No |
| -X | Directly pass -XX parameters to the JVM | No |
| -h | Show help | No |
2.1.2 Removing a ConfigNode
First connect to the cluster via CLI and use show confignodes to confirm the NodeID of the ConfigNode to be removed:
IoTDB> show confignodes
+------+-------+---------------+------------+--------+
|NodeID| Status|InternalAddress|InternalPort| Role|
+------+-------+---------------+------------+--------+
| 0|Running| 127.0.0.1| 10710| Leader|
| 1|Running| 127.0.0.1| 10711|Follower|
| 2|Running| 127.0.0.1| 10712|Follower|
+------+-------+---------------+------------+--------+
Total line number = 3
It costs 0.030sThen remove the ConfigNode using the following SQL command:
REMOVE CONFIGNODE [confignode_id];2.2 DataNode Maintenance
There are two common scenarios for DataNode maintenance:
- Cluster scaling: Add new DataNodes to the cluster to expand cluster capacity.
- Cluster fault recovery: When the machine hosting a DataNode fails and the DataNode cannot run properly, remove the faulty DataNode and add a new DataNode to the cluster.
❗️ Note: To ensure normal cluster operation, during and after DataNode maintenance, the number of normally running DataNodes must not be less than the data replication factor (usually 2) or the metadata replication factor (usually 3).
2.2.1 Adding a DataNode
Script commands:
# Linux / MacOS
# First switch to the IoTDB root directory
sbin/start-datanode.sh
# Windows
# First switch to the IoTDB root directory
# Before V2.0.4.x
sbin\start-datanode.bat
# V2.0.4.x and later
sbin\windows\start-datanode.batParameter description:
| Param | Description | Required |
|---|---|---|
| -v | Show version information | No |
| -f | Run the script in the foreground, not in the background | No |
| -d | Start in daemon mode (run in the background) | No |
| -p | Specify a file to store the process ID for process management | No |
| -c | Specify the path of the configuration folder to load configuration files | No |
| -g | Print detailed garbage collection (GC) information | No |
| -H | Specify the path for Java heap dump files on JVM out-of-memory | No |
| -E | Specify the path for JVM error log files | No |
| -D | Define system properties in the format key=value | No |
| -X | Directly pass -XX parameters to the JVM | No |
| -h | Show help | No |
Note: After adding a DataNode, as new writes arrive (and old data expires if TTL is set), the cluster load will gradually balance toward the new DataNode, eventually achieving balanced storage and computing resources across all nodes.
2.2.2 Removing a DataNode
First connect to the cluster via CLI and use show datanodes to confirm the NodeID of the DataNode to be removed:
IoTDB> show datanodes
+------+-------+----------+-------+-------------+---------------+
|NodeID| Status|RpcAddress|RpcPort|DataRegionNum|SchemaRegionNum|
+------+-------+----------+-------+-------------+---------------+
| 1|Running| 0.0.0.0| 6667| 0| 0|
| 2|Running| 0.0.0.0| 6668| 1| 1|
| 3|Running| 0.0.0.0| 6669| 1| 0|
+------+-------+----------+-------+-------------+---------------+
Total line number = 3
It costs 0.110sThen remove the DataNode using the following SQL command:
REMOVE DATANODE [datanode_id];3. Load Balance
Region migration belongs to advanced operations and maintenance functions, which have certain operational costs. It is recommended to read the entire document before using this function. If you have any questions about the solution design, please contact the IoTDB team for technical support.
3.1 Feature introduction
IoTDB is a distributed database, and the balanced distribution of data plays an important role in load balancing the disk space and write pressure of the cluster. Region is the basic unit for distributed storage of data in IoTDB cluster, and the specific concept can be seen in region。
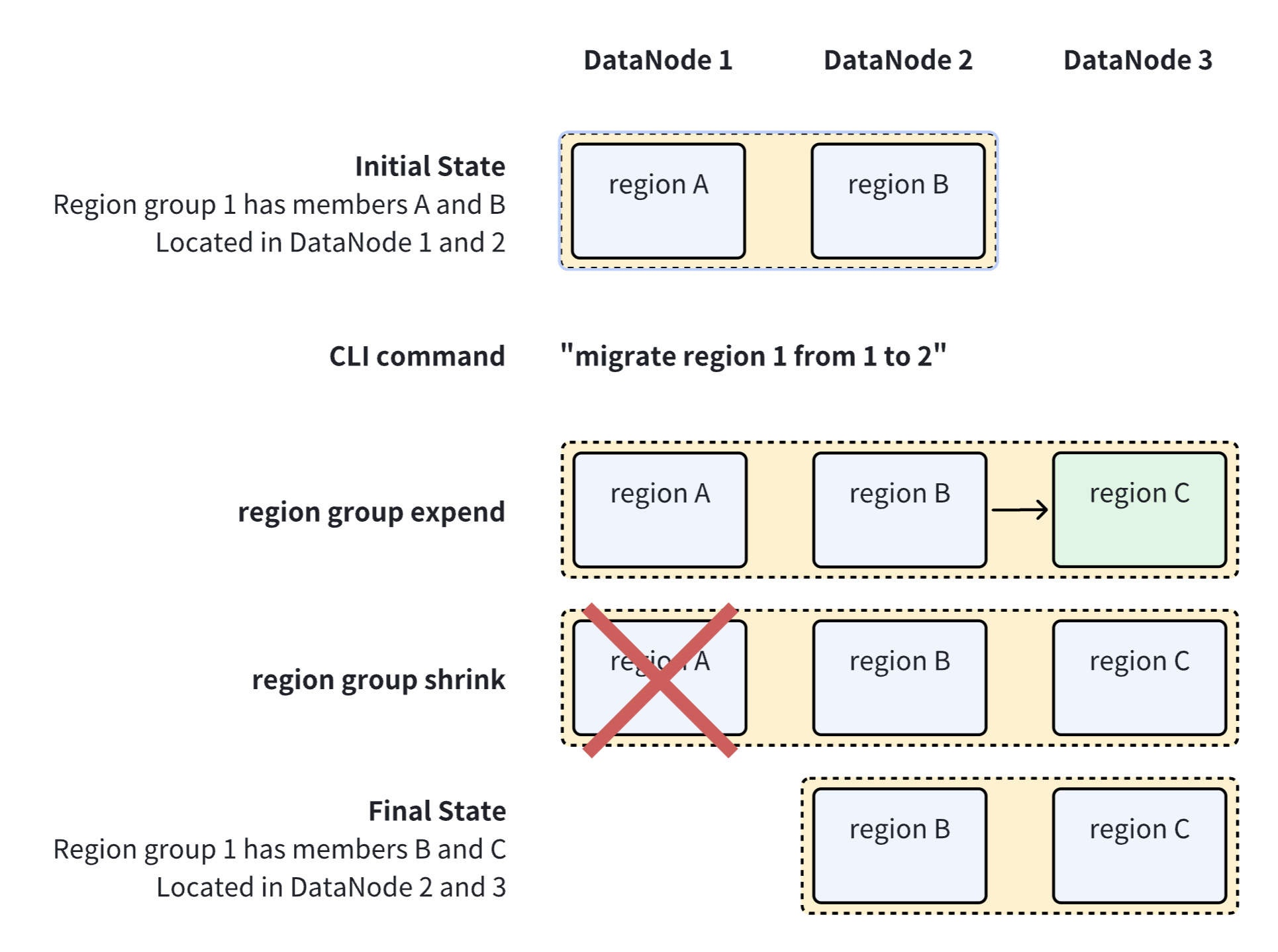
Under normal operation of the cluster, IoTDB will automatically perform load balancing on data. However, in scenarios where a new DataNode node is added to the cluster or where the hard disk of the machine where the DataNode is located is damaged and data needs to be recovered, manual region migration can be used to finely adjust the cluster load and operations.
Here is a schematic diagram of the region migration process :
3.2 Notes
- It is recommended to only use the Region Migration feature on IoTDB 1.3.3 and higher versions.
- Region migration is only supported when the consensus protocol is IoTConsus or Ratis (in iotdb system. properties, the
schema_region_consensus_protocol_classanddata_region_consensus_protocol_class). - Region migration consumes system resources such as disk space and network bandwidth. It is recommended to perform the migration during periods of low business load.
- Under ideal circumstances, Region migration does not affect user-side read or write operations. In special cases, Region migration may block writes. For detailed identification and handling of such situations, please refer to the user guide.
3.3 Instructions for use
Grammar definition :
Submit an asynchronous task to migrate a region from one DataNode to another.
migrateRegion : MIGRATE REGION regionId=INTEGER_LITERAL FROM fromId=INTEGER_LITERAL TO toId=INTEGER_LITERAL ;Example :
Migrating region 1 from DataNode 2 to DataNode 3:
IoTDB> migrate region 1 from 2 to 3 Msg: The statement is executed successfully."The statement is executed successfully" only represents the successful submission of the region migration task, not the completion of execution. The execution status of the task can be viewed through the CLI command
show regions.Related configuration :
- Migration speed control : modify
iotdb-system.propertiesparametersregion_migration_speed_limit_bytes_per_secondcontrol region migration speed.
- Migration speed control : modify
Time cost estimation :
- If there are no concurrent writes during the migration process, the time consumption can be simply estimated by dividing the region data volume by the data transfer speed. For example, for a 1TB region, the hard disk internet bandwidth and speed limit parameters jointly determine that the data transfer speed is 100MB/s, so it takes about 3 hours to complete the migration.
- If there are concurrent writes in the migration process, the time consumption will increase, and the specific time consumption depends on various factors such as write pressure and system resources. It can be simply estimated as
no concurrent write time × 1.5.
Migration progress observation : During the migration process, the state changes can be observed through the CLI command
show regions. Taking the 2 replicas as an example, the state of the consensus group where the region is located will go through the following process:- Before migration starts:
Running,Running. - Expansion phase:
Running,Running,Adding. Due to the large number of file transfers involved, it may take a long time. If using IoTConsensus, the specific file transfer progress can be searched in the DataNode log[SNAPSHOT TRANSMISSION]. - Stages:
Removing,Running,Running. - Migration complete:
Running,Running.
Taking the expansion phase as an example, the result of
show regionsmay be:IoTDB> show regions +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ |RegionId| Type| Status|Database|SeriesSlotNum|TimeSlotNum|DataNodeId|RpcAddress|RpcPort|InternalAddress| Role| CreateTime| +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ | 0|SchemaRegion|Running| root.ln| 1| 0| 1| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 0|SchemaRegion|Running| root.ln| 1| 0| 2| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 0|SchemaRegion|Running| root.ln| 1| 0| 3| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 1| DataRegion|Running| root.ln| 1| 1| 1| 0.0.0.0| 6667| 127.0.0.1| Leader|2024-04-15T18:55:19.457| | 1| DataRegion|Running| root.ln| 1| 1| 2| 0.0.0.0| 6668| 127.0.0.1|Follower|2024-04-15T18:55:19.457| | 1| DataRegion| Adding| root.ln| 1| 1| 3| 0.0.0.0| 6668| 127.0.0.1|Follower|2024-04-15T18:55:19.457| +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ Total line number = 3 It costs 0.003s- Before migration starts:
Block Write:
The region migration in IoTConsensus does not directly block writes. However, since the process requires suspending the cleanup of WAL files, if the accumulated WAL files exceed the threshold defined by wal_throttle_threshold_in_byte, the current DataNode will pause writing until the WAL files fall below the threshold.If a write error occurs during the migration due to the WAL exceeding the threshold (e.g., an error message like “The write is rejected because the wal directory size has reached the threshold”), you can increase the wal_throttle_threshold_in_byte value to 500GB or more to allow continued writing. Use the following SQL statement:
IoTDB> set configuration "wal_throttle_threshold_in_byte"="536870912000" Msg: The statement is executed successfully.