Apache Spark(TsFile)
Apache Spark(TsFile)
About Spark-TsFile-Connector
Spark-TsFile-Connector implements the support of Spark for external data sources of Tsfile type. This enables users to read, write and query Tsfile by Spark.
With this connector, you can
- load a single TsFile, from either the local file system or hdfs, into Spark
- load all files in a specific directory, from either the local file system or hdfs, into Spark
- write data from Spark into TsFile
System Requirements
| Spark Version | Scala Version | Java Version | TsFile |
|---|---|---|---|
2.4.3 | 2.11.8 | 1.8 | 1.0.0 |
Note: For more information about how to download and use TsFile, please see the following link: https://github.com/apache/iotdb/tree/master/tsfile.
Currently we only support spark version 2.4.3 and there are some known issue on 2.4.7, do no use it
Quick Start
Local Mode
Start Spark with TsFile-Spark-Connector in local mode:
./<spark-shell-path> --jars tsfile-spark-connector.jar,tsfile-{version}-jar-with-dependencies.jar,hadoop-tsfile-{version}-jar-with-dependencies.jarNote:
- <spark-shell-path> is the real path of your spark-shell.
- Multiple jar packages are separated by commas without any spaces.
- See https://github.com/apache/iotdb/tree/master/tsfile for how to get TsFile.
Distributed Mode
Start Spark with TsFile-Spark-Connector in distributed mode (That is, the spark cluster is connected by spark-shell):
. /<spark-shell-path> --jars tsfile-spark-connector.jar,tsfile-{version}-jar-with-dependencies.jar,hadoop-tsfile-{version}-jar-with-dependencies.jar --master spark://ip:7077Note:
- <spark-shell-path> is the real path of your spark-shell.
- Multiple jar packages are separated by commas without any spaces.
- See https://github.com/apache/iotdb/tree/master/tsfile for how to get TsFile.
Data Type Correspondence
| TsFile data type | SparkSQL data type |
|---|---|
| BOOLEAN | BooleanType |
| INT32 | IntegerType |
| INT64 | LongType |
| FLOAT | FloatType |
| DOUBLE | DoubleType |
| TEXT | StringType |
Schema Inference
The way to display TsFile is dependent on the schema. Take the following TsFile structure as an example: There are three measurements in the TsFile schema: status, temperature, and hardware. The basic information of these three measurements is listed:
| Name | Type | Encode |
|---|---|---|
| status | Boolean | PLAIN |
| temperature | Float | RLE |
| hardware | Text | PLAIN |
The existing data in the TsFile are:
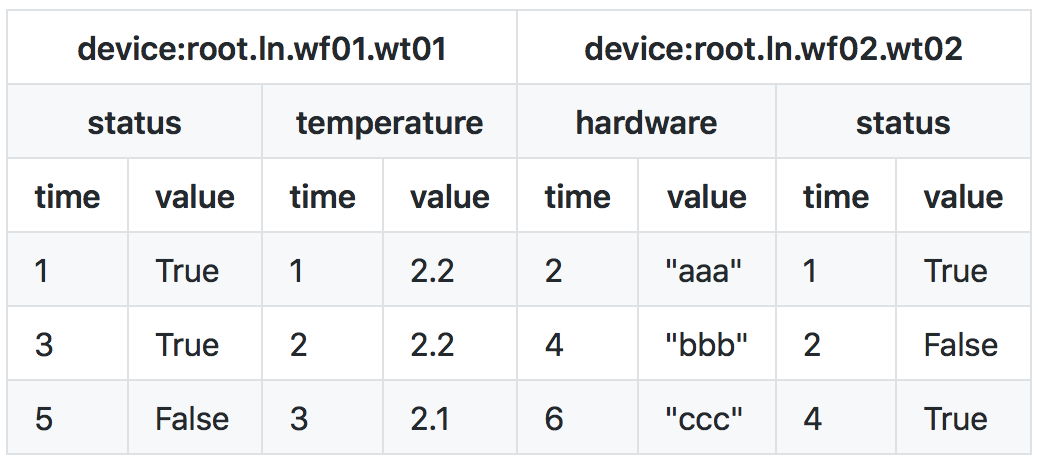
The corresponding SparkSQL table is:
| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
|---|---|---|---|---|---|---|
| 1 | null | true | null | 2.2 | true | null |
| 2 | null | false | aaa | 2.2 | null | null |
| 3 | null | null | null | 2.1 | true | null |
| 4 | null | true | bbb | null | null | null |
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
You can also use narrow table form which as follows: (You can see part 6 about how to use narrow form)
| time | device_name | status | hardware | temperature |
|---|---|---|---|---|
| 1 | root.ln.wf02.wt01 | true | null | 2.2 |
| 1 | root.ln.wf02.wt02 | true | null | null |
| 2 | root.ln.wf02.wt01 | null | null | 2.2 |
| 2 | root.ln.wf02.wt02 | false | aaa | null |
| 3 | root.ln.wf02.wt01 | true | null | 2.1 |
| 4 | root.ln.wf02.wt02 | true | bbb | null |
| 5 | root.ln.wf02.wt01 | false | null | null |
| 6 | root.ln.wf02.wt02 | null | ccc | null |
Scala API
NOTE: Remember to assign necessary read and write permissions in advance.
- Example 1: read from the local file system
import org.apache.iotdb.spark.tsfile._
val wide_df = spark.read.tsfile("test.tsfile")
wide_df.show
val narrow_df = spark.read.tsfile("test.tsfile", true)
narrow_df.show- Example 2: read from the hadoop file system
import org.apache.iotdb.spark.tsfile._
val wide_df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile")
wide_df.show
val narrow_df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile", true)
narrow_df.show- Example 3: read from a specific directory
import org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/usr/hadoop")
df.showNote 1: Global time ordering of all TsFiles in a directory is not supported now.
Note 2: Measurements of the same name should have the same schema.
- Example 4: query in wide form
import org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile")
df.createOrReplaceTempView("tsfile_table")
val newDf = spark.sql("select * from tsfile_table where `device_1.sensor_1`>0 and `device_1.sensor_2` < 22")
newDf.showimport org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile")
df.createOrReplaceTempView("tsfile_table")
val newDf = spark.sql("select count(*) from tsfile_table")
newDf.show- Example 5: query in narrow form
import org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile", true)
df.createOrReplaceTempView("tsfile_table")
val newDf = spark.sql("select * from tsfile_table where device_name = 'root.ln.wf02.wt02' and temperature > 5")
newDf.showimport org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile", true)
df.createOrReplaceTempView("tsfile_table")
val newDf = spark.sql("select count(*) from tsfile_table")
newDf.show- Example 6: write in wide form
// we only support wide_form table to write
import org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile")
df.show
df.write.tsfile("hdfs://localhost:9000/output")
val newDf = spark.read.tsfile("hdfs://localhost:9000/output")
newDf.show- Example 7: write in narrow form
// we only support wide_form table to write
import org.apache.iotdb.spark.tsfile._
val df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile", true)
df.show
df.write.tsfile("hdfs://localhost:9000/output", true)
val newDf = spark.read.tsfile("hdfs://localhost:9000/output", true)
newDf.showAppendix A: Old Design of Schema Inference
The way to display TsFile is related to TsFile Schema. Take the following TsFile structure as an example: There are three measurements in the Schema of TsFile: status, temperature, and hardware. The basic info of these three Measurements is:
| Name | Type | Encode |
|---|---|---|
| status | Boolean | PLAIN |
| temperature | Float | RLE |
| hardware | Text | PLAIN |
The existing data in the file are:
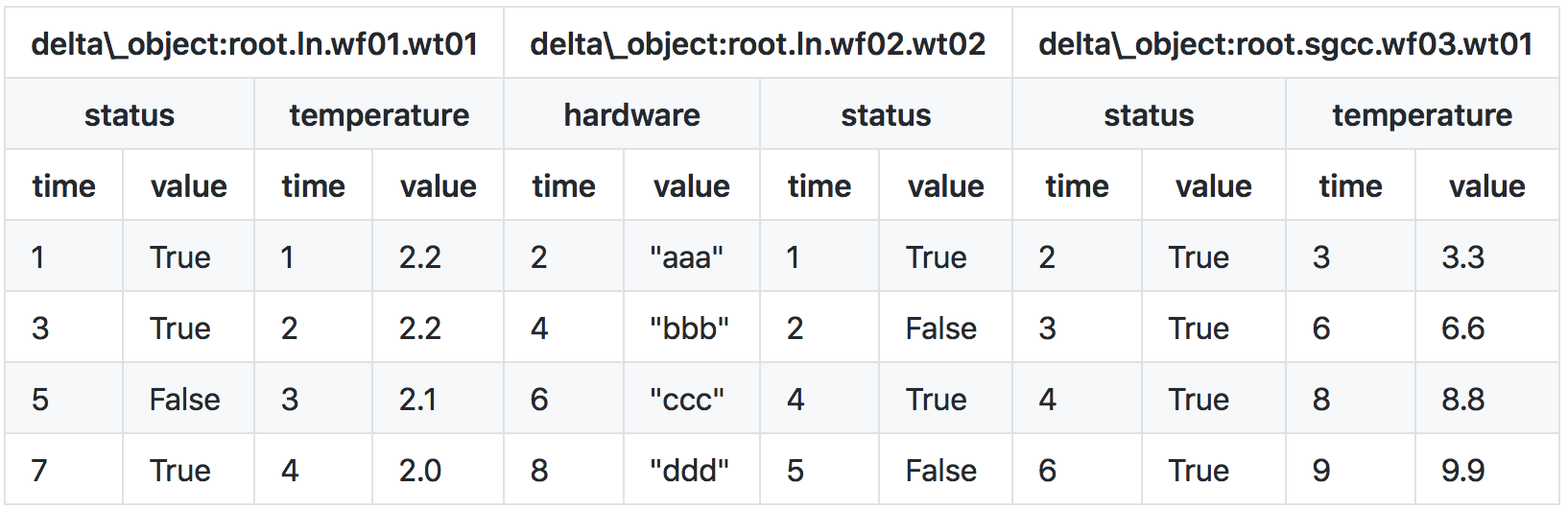
A set of time-series data
There are two ways to show a set of time-series data:
- the default way
Two columns are created to store the full path of the device: time(LongType) and delta_object(StringType).
time: Timestamp, LongTypedelta_object: Delta_object ID, StringType
Next, a column is created for each Measurement to store the specific data. The SparkSQL table structure is:
| time(LongType) | delta_object(StringType) | status(BooleanType) | temperature(FloatType) | hardware(StringType) |
|---|---|---|---|---|
| 1 | root.ln.wf01.wt01 | True | 2.2 | null |
| 1 | root.ln.wf02.wt02 | True | null | null |
| 2 | root.ln.wf01.wt01 | null | 2.2 | null |
| 2 | root.ln.wf02.wt02 | False | null | "aaa" |
| 2 | root.sgcc.wf03.wt01 | True | null | null |
| 3 | root.ln.wf01.wt01 | True | 2.1 | null |
| 3 | root.sgcc.wf03.wt01 | True | 3.3 | null |
| 4 | root.ln.wf01.wt01 | null | 2.0 | null |
| 4 | root.ln.wf02.wt02 | True | null | "bbb" |
| 4 | root.sgcc.wf03.wt01 | True | null | null |
| 5 | root.ln.wf01.wt01 | False | null | null |
| 5 | root.ln.wf02.wt02 | False | null | null |
| 5 | root.sgcc.wf03.wt01 | True | null | null |
| 6 | root.ln.wf02.wt02 | null | null | "ccc" |
| 6 | root.sgcc.wf03.wt01 | null | 6.6 | null |
| 7 | root.ln.wf01.wt01 | True | null | null |
| 8 | root.ln.wf02.wt02 | null | null | "ddd" |
| 8 | root.sgcc.wf03.wt01 | null | 8.8 | null |
| 9 | root.sgcc.wf03.wt01 | null | 9.9 | null |
- unfold delta_object column
Expand the device column by "." into multiple columns, ignoring the root directory "root". Convenient for richer aggregation operations. To use this display way, the parameter "delta_object_name" is set in the table creation statement (refer to Example 5 in Section 5.1 of this manual), as in this example, parameter "delta_object_name" is set to "root.device.turbine". The number of path layers needs to be one-to-one. At this point, one column is created for each layer of the device path except the "root" layer. The column name is the name in the parameter and the value is the name of the corresponding layer of the device. Next, one column is created for each Measurement to store the specific data.
Then SparkSQL Table Structure is as follows:
| time(LongType) | group(StringType) | field(StringType) | device(StringType) | status(BooleanType) | temperature(FloatType) | hardware(StringType) |
|---|---|---|---|---|---|---|
| 1 | ln | wf01 | wt01 | True | 2.2 | null |
| 1 | ln | wf02 | wt02 | True | null | null |
| 2 | ln | wf01 | wt01 | null | 2.2 | null |
| 2 | ln | wf02 | wt02 | False | null | "aaa" |
| 2 | sgcc | wf03 | wt01 | True | null | null |
| 3 | ln | wf01 | wt01 | True | 2.1 | null |
| 3 | sgcc | wf03 | wt01 | True | 3.3 | null |
| 4 | ln | wf01 | wt01 | null | 2.0 | null |
| 4 | ln | wf02 | wt02 | True | null | "bbb" |
| 4 | sgcc | wf03 | wt01 | True | null | null |
| 5 | ln | wf01 | wt01 | False | null | null |
| 5 | ln | wf02 | wt02 | False | null | null |
| 5 | sgcc | wf03 | wt01 | True | null | null |
| 6 | ln | wf02 | wt02 | null | null | "ccc" |
| 6 | sgcc | wf03 | wt01 | null | 6.6 | null |
| 7 | ln | wf01 | wt01 | True | null | null |
| 8 | ln | wf02 | wt02 | null | null | "ddd" |
| 8 | sgcc | wf03 | wt01 | null | 8.8 | null |
| 9 | sgcc | wf03 | wt01 | null | 9.9 | null |
TsFile-Spark-Connector displays one or more TsFiles as a table in SparkSQL By SparkSQL. It also allows users to specify a single directory or use wildcards to match multiple directories. If there are multiple TsFiles, the union of the measurements in all TsFiles will be retained in the table, and the measurement with the same name have the same data type by default. Note that if a situation with the same name but different data types exists, TsFile-Spark-Connector does not guarantee the correctness of the results.
The writing process is to write a DataFrame as one or more TsFiles. By default, two columns need to be included: time and delta_object. The rest of the columns are used as Measurement. If user wants to write the second table structure back to TsFile, user can set the "delta_object_name" parameter(refer to Section 5.1 of Section 5.1 of this manual).
Appendix B: Old Note
NOTE: Check the jar packages in the root directory of your Spark and replace libthrift-0.9.2.jar and libfb303-0.9.2.jar with libthrift-0.9.1.jar and libfb303-0.9.1.jar respectively.