TSDB Comparison
TSDB Comparison
Overview
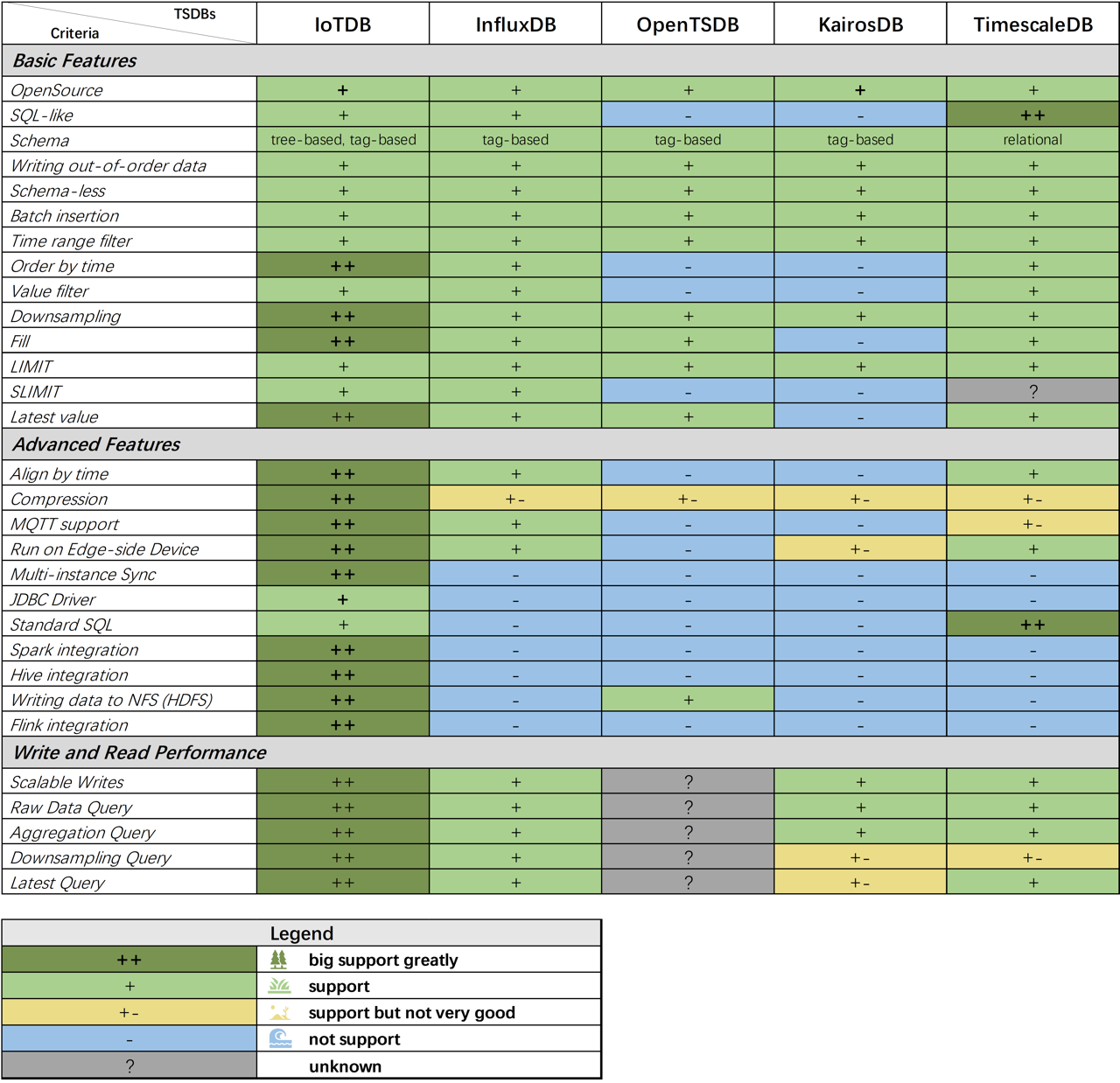
*The table format is inspired by Andriy Zabavskyy: How to Select Time Series DB.
Known Time Series Database
As the time series data becomes more and more important,
several open sourced time series databases are introduced to the world.
However, few of them are developed for IoT or IIoT (Industrial IoT) scenario in particular.
3 kinds of TSDBs are compared here.
InfluxDB - Native Time series database
InfluxDB is one of the most popular TSDBs.
Interface: InfluxQL and HTTP API (also known as tsdb API or api tsdb query)
InfluxDB time series database is widely adopted in monitoring platforms and real-time metrics analysis. Developers often rely on its tsdb cli query, flexible tsdb query example, and strong ecosystem, making it a standard choice. Advanced users can also configure InfluxDB tsdb config, check InfluxDB tsdb status, and analyze storage with InfluxDB tsdb size or InfluxDB tsdb format.
OpenTSDB and KairosDB - Time series database based on NoSQL
These two DBs are similar, while the first is based on HBase and the second is based on Cassandra.
Both of them provides RESTful style API.Interface: Restful API
OpenTSDB is often mentioned in tsdb github discussions and benchmarks, and many enterprises use it as a tsdb monitoring platform. KairosDB, while less popular, demonstrates an interesting tsdb architecture choice by building on Cassandra.
TimescaleDB - Time series database based on Relational Database
Interface: SQL
TimescaleDB uses PostgreSQL (tsdb postgresql) as its foundation. It is one of the most well-known examples in the tsdb vs rdbms debate, showing how relational models can be extended to handle time series workloads. It has a strong presence in the tsdb database rank because of its enterprise-grade performance.
Prometheus and Druid are also famous for time series data management.
However, Prometheus focuses data collection, data visualization and alert warnings.
Druid focuses on data analysis with OLAP workload. We omit them here.
Comparison
The above time series databases are compared from two aspects: the feature comparison and the performance
comparison(tsdb benchmark).
Feature Comparison
I list the basic features comparison of these databases.
Legend:
++: big support greatly+: support+-: support but not very good-: not support?: unknown
Basic Features
| TSDB | IoTDB | InfluxDB | OpenTSDB | KairosDB | TimescaleDB |
|---|---|---|---|---|---|
| OpenSource | + | + | + | + | + |
| SQL-like | + | + | - | - | ++ |
| Schema | tree-based, tag-based | tag-based | tag-based | tag-based | relational |
| Writing out-of-order data | + | + | + | + | + |
| Schema-less | + | + | + | + | + |
| Batch insertion | + | + | + | + | + |
| Time range filter | + | + | + | + | + |
| Order by time | ++ | + | - | - | + |
| Value filter | + | + | - | - | + |
| Downsampling | ++ | + | + | + | + |
| Fill | ++ | + | + | - | + |
| LIMIT | + | + | + | + | + |
| SLIMIT | + | + | - | - | ? |
| Latest value | ++ | + | + | - | + |
Details
OpenSource:
- IoTDB uses Apache License 2.0.
- InfluxDB uses MIT license. However, the cluster version is not open sourced.
- OpenTSDB uses LGPL2.1, which is not compatible with Apache License.
- KairosDB uses Apache License 2.0.
- TimescaleDB uses Timescale License, which is not free for enterprise.
SQL like:
- IoTDB and InfluxDB support SQL like language. In addition, the integration of IoTDB and Calcite is almost done (a PR has been submitted), which means IoTDB will support Standard SQL soon.
- OpenTSDB and KairosDB only support Rest API, while IoTDB also supports Rest API (a PR has been submitted).
- TimescaleDB uses the SQL the same as PG.
Schema:
IoTDB: IoTDB proposes a Tree based schema. Suitable for industrial hierarchical device management. This makes tsdb format definition flexible.
It is quite different from other TSDBs. However, the kind of schema has the following advantages:In many industrial scenarios, the management of devices are hierarchical, rather than flat.
That is why we think a tree based schema is better than tag-value based schema.In many real world applications, tag names are constant. For example, a wind turbine manufacturer
always identify their wind turbines by which country it locates, the farm name it belongs to, and its ID in the farm.
So, a 4-depth tree ("root.the-country-name.the-farm-name.the-id") is fine.
You do not need to repeat to tell IoTDB the 2nd level of the tree is for country name,
the 3rd level is for farm id, etc.A path based time series ID definition also supports flexible queries, like "root.*.a.b.*", where * is wildcard character.
InfluxDB, KairosDB, OpenTSDB are tag-value based, which is more popular currently.
TimescaleDB uses relational table.
Order by time:
Order by time seems quite trivial for time series database. But... if we consider another feature, called align by time,
something becomes interesting. And, that is why we mark OpenTSDB and KairosDB unsupported.Actually, in each time series, all these TSDBs support order data by timestamps.
However, OpenTSDB and KairosDB do not support order data from different timeseries in the time order.IoTDB supports "align by time", while InfluxDB TSDB analysis prefers a row-based output.
Ok, consider a new case: I have two time series, one is for the wind speed in wind farm1,
another is for the generated energy of wind turbine1 in farm1. If we want to analyze the relation between the
wind speed and the generated energy, we have to know the values of both at the same time.
That is to say, we have to align the two time series in the time dimension.So, the result should be:
timestamp wind speed generated energy 1 5.0 13.1 2 6.0 13.3 3 null 13.1 or,
timestamp series name value 1 wind speed 5.0 1 generated energy 13.1 2 wind speed 6.0 2 generated energy 13.3 3 generated energy 13.1
Though the second table format does not align data by the time dimension, it is easy to be implemented in the client-side,
by just scanning data row by row.
IoTDB supports the first table format (called align by time), InfluxDB supports the second table format.
Downsampling:
Downsampling is for changing the granularity of timeseries, e.g., from 10Hz to 1Hz, or 1 point per day.
Different from other systems, IoTDB downsamples data in real time, while others serialized downsampled data on disk.
That is to say,IoTDB supports adhoc downsampling data in arbitrary time.
e.g., a SQL returns 1 point per 5 minutes and start with 2020-04-27 08:00:00 while another SQL returns 1 point per 5 minutes + 10 seconds and start with 2020-04-27 08:00:01.
(InfluxDB also supports adhoc downsampling but the performance is ..... hm)There is no disk loss for IoTDB.
Fill:
Sometimes we thought the data is collected in some fixed frequency, e.g., 1Hz (1 point per second).
But usually, we may lost some data points, because the network is unstable, the machine is busy, or the machine is down for several minutes.In this case, filling these holes is important. Data scientists can avoid many so called dirty work, e.g., data clean.
InfluxDB and OpenTSDB only support using fill in a group by statement, while IoTDB supports to fill data when just given a particular timestamp.
Besides, IoTDB supports advanced fill strategies, while InfluxDB and OpenTSDB provide only basic ones. Fill is important in tsdb metrics pipelines and tsdb storage optimization.Slimit:
Slimit means return limited number of measurements (or, fields in InfluxDB).
For example, a wind turbine may have 1000 measurements (speed, voltage, etc..), using slimit and soffset can just return a part of them.Latest value:
As one of the most basic timeseries based applications is monitoring the latest data.
Therefore, a query to return the latest value of a time series is very important.
IoTDB and OpenTSDB support that with a special SQL or API,
while InfluxDB supports that using an aggregation function.
(the reason why IoTDB provides a special SQL is IoTDB optimizes the query expressly.)
Conclusion:
Well, if we compare the basic and advanced features, we can find that OpenTSDB and KairosDB somehow lack some important query features. TimescaleDB's free use in business is limited by its licensing model. IoTDB and InfluxDB can meet most requirements of TSDB time series database management, while they have some differences in tsdb architecture and query performance.
Ultimately, the right choice depends on use case: IoT and IIoT scenarios often benefit from IoTDB’s schema, while influxdb time series database remains the most common solution in tsdb monitoring platform deployments.
Advanced Features
Beyond the basics, these systems also differ in tsdb cluster management, tsdb import capability, and integration with external systems like tsdb Elasticsearch for indexing. For example:
InfluxDB provides a tsdb viewer and an advanced tsdb tool ecosystem.
OpenTSDB often integrates with in-memory time series database caches for faster queries.
TimescaleDB offers deep PostgreSQL integration with tsdb Java drivers and compatibility for tsdb for Windows deployment.
I listed some interesting features that these systems may differ.
| TSDB | IoTDB | InfluxDB | OpenTSDB | KairosDB | TimescaleDB |
|---|---|---|---|---|---|
| Align by time | ++ | + | - | - | + |
| Compression | ++ | +- | +- | +- | +- |
| MQTT support | ++ | + | - | - | +- |
| Run on Edge-side Device | ++ | + | - | +- | + |
| Multi-instance Sync | ++ | - | - | - | - |
| JDBC Driver | + | - | - | - | ++ |
| Standard SQL | + | - | - | - | ++ |
| Spark integration | ++ | - | - | - | - |
| Hive integration | ++ | - | - | - | - |
| Writing data to NFS (HDFS) | ++ | - | + | - | - |
| Flink integration | ++ | - | - | - | - |
Align by time: have been introduced. Let's skip it..
Compression:
- IoTDB supports many encoding and compression for time series, like RLE, 2DIFF, Gorilla, etc.. and Snappy compression.
In IoTDB, you can choose which encoding method you want, according to the data distribution. For more info, see here. - InfluxDB also supports encoding and compression, but you can not define which encoding method you want.
It just depends on the data type. For more info, see here. - OpenTSDB and KairosDB use HBase and Cassandra in backend, and have no special encoding for time series.
- IoTDB supports many encoding and compression for time series, like RLE, 2DIFF, Gorilla, etc.. and Snappy compression.
MQTT protocol support:
MQTT protocol is an international standard and widely known in industrial users. Only IoTDB and InfluxDB support user using MQTT client to write data.
Running on Edge-side Device:
Nowdays, edge computing is more and more popular, which means the edge device has more powerful computational resources.
Deploying a TSDB on the edge side is useful for managing data on the edge side and serve for edge computing.
As OpenTSDB and KairosDB rely another DB, the architecture is heavy. Especially, it is hard to run Hadoop on the edge side.Multi-instance Sync:
Ok, now we have many TSDB instances on the edge-side. Then, how to upload their data to the data center, to form a ... data lake (or ocean, river,..., whatever).
One solution is to read data from these instances and write the data point by point to the data center instance.
IoTDB provides another choice, which is just uploading the data file into the data center incrementally, then the data center can support service on the data.JDBC driver:
Now only IoTDB supports a JDBC driver (though not all interfaces are implemented), and makes it possible to integrate many other JDBC driver based softwares.
Standard SQL:
As mentioned before, the integration of IoTDB and Calcite is almost done (a PR has been submitted), which means IoTDB will support Standard SQL.
Spark and Hive integration:
It is very important that letting big data analysis software to access the data in database for more complex data analysis.
IoTDB supports Hive-connector and Spark connector for better integration.Writing data to NFS (HDFS):
Sharing nothing architecture is good, but sometimes you have to add new servers even your CPU and memory is idle but the disk is full...
Besides, if we can save the data file directly to HDFS, it will be more easy to use Spark and other softwares to analyze data, without ETL.IoTDB supports writing data locally or on HDFS directly. IoTDB also allows user to extend to store data on other NFS.
InfluxDB, KairosDB have to write data locally.
OpenTSDB has to write data on HDFS.
Conclusion:
We can find that IoTDB has many powerful features that other TSDBs do not support.
Performance Comparison
Ok... If you say, "well, I just want the basic features. IoTDB has little difference from others.".
It is somehow right. But, if you consider the performance, you may change your mind.
quick review
| TSDB | IoTDB | InfluxDB | KairosDB | TimescaleDB |
|---|---|---|---|---|
| Scalable Writes | ++ | + | + | + |
| Raw Data Query | ++ | + | + | + |
| Aggregation Query | ++ | + | + | + |
| Downsampling Query | ++ | + | +- | +- |
| Latest Query | ++ | + | +- | + |
- Write:
We test the performance of writing from two aspects: batch size and client num. The number of storage group is 10. There are 1000 devices and each device has 100 measurements(i.e.,, 100K time series total).
- Read:
10 clients read data concurrently. The number of storage group is 10. There are 10 devices and each device has 10 measurements (i.e.,, 100 time series total).
The data type is double, encoding type is GORILLA
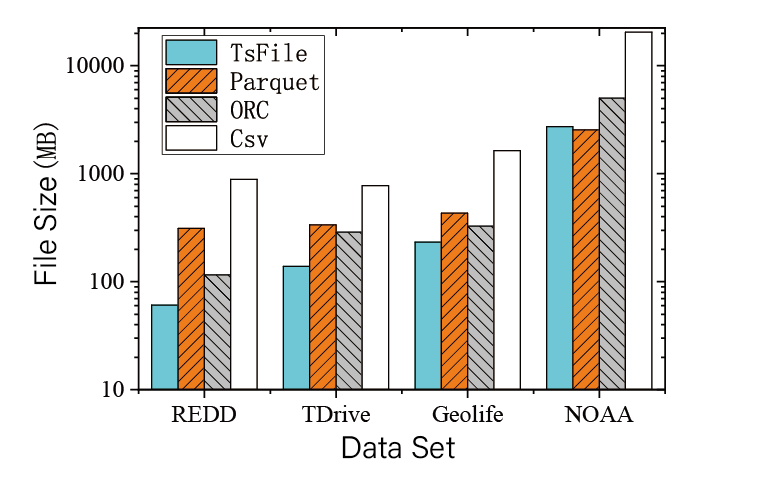
- Compression:
We test and compare file sizes of TsFile(the file format of IoTDB) and some others famous dataset formats, which are Parquet, ORC and Csv, after the same datasets are written.
The IoTDB version is v0.11.1.
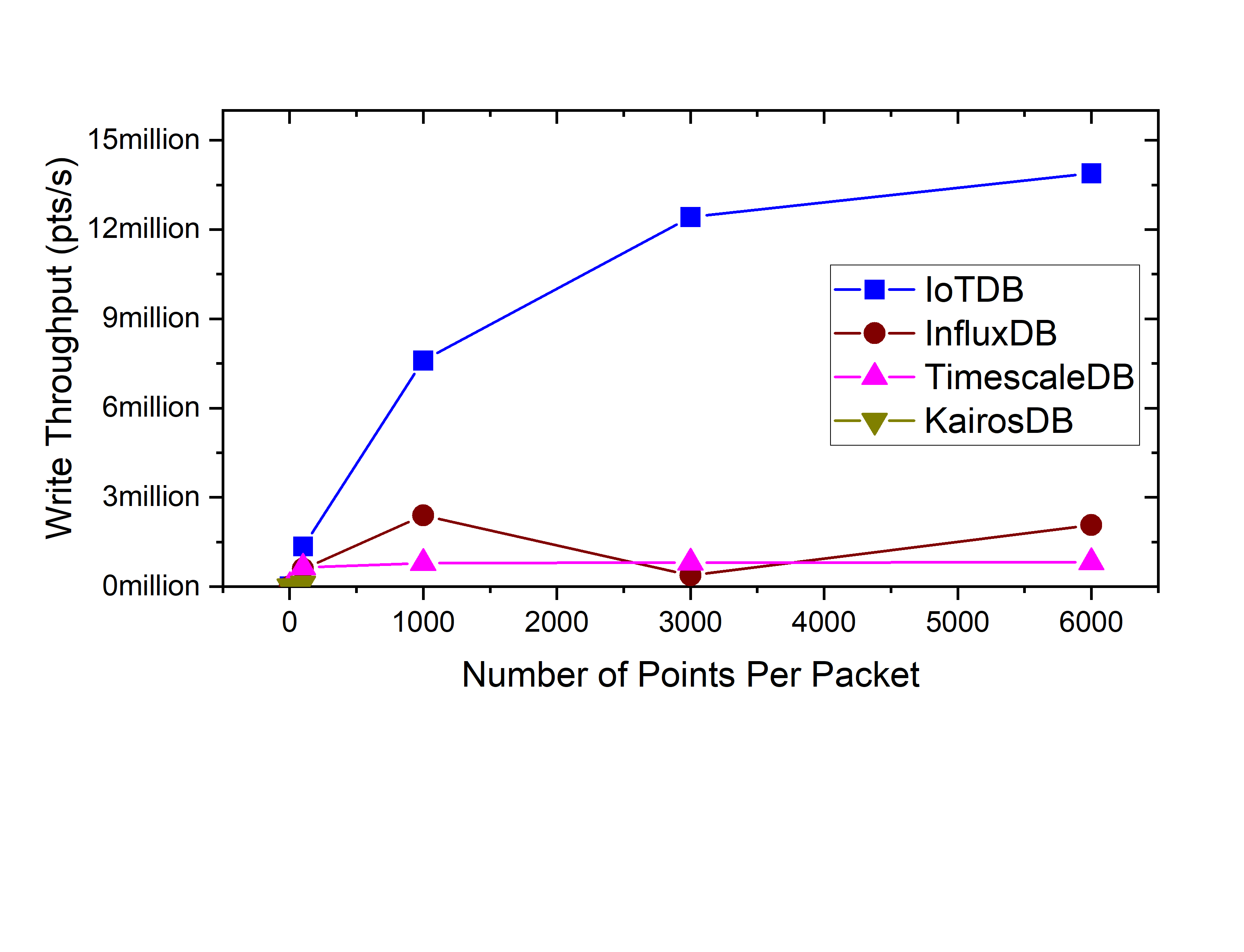
Write performance:
- batch size:
10 clients write data concurrently.
IoTDB uses batch insertion API and the batch size is distributed from 0 to 6000 (write N data points per write API call).
The write throughput (points/second) is:
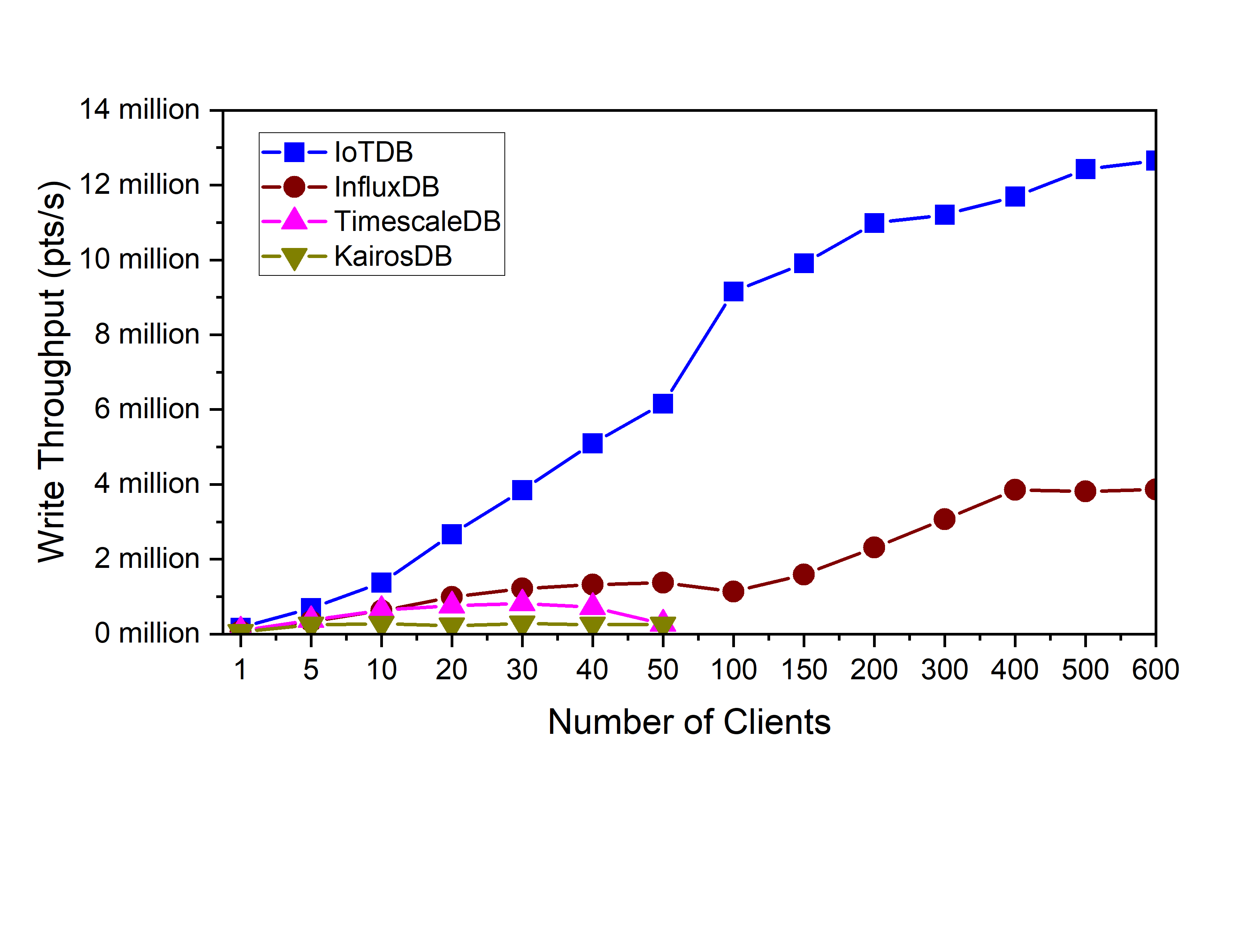
- client num:
The client num is distributed from 1 to 50.
IoTDB uses batch insertion API and the batch size is 100 (write 100 data points per write API call).
The write throughput (points/second) is:
Query performance
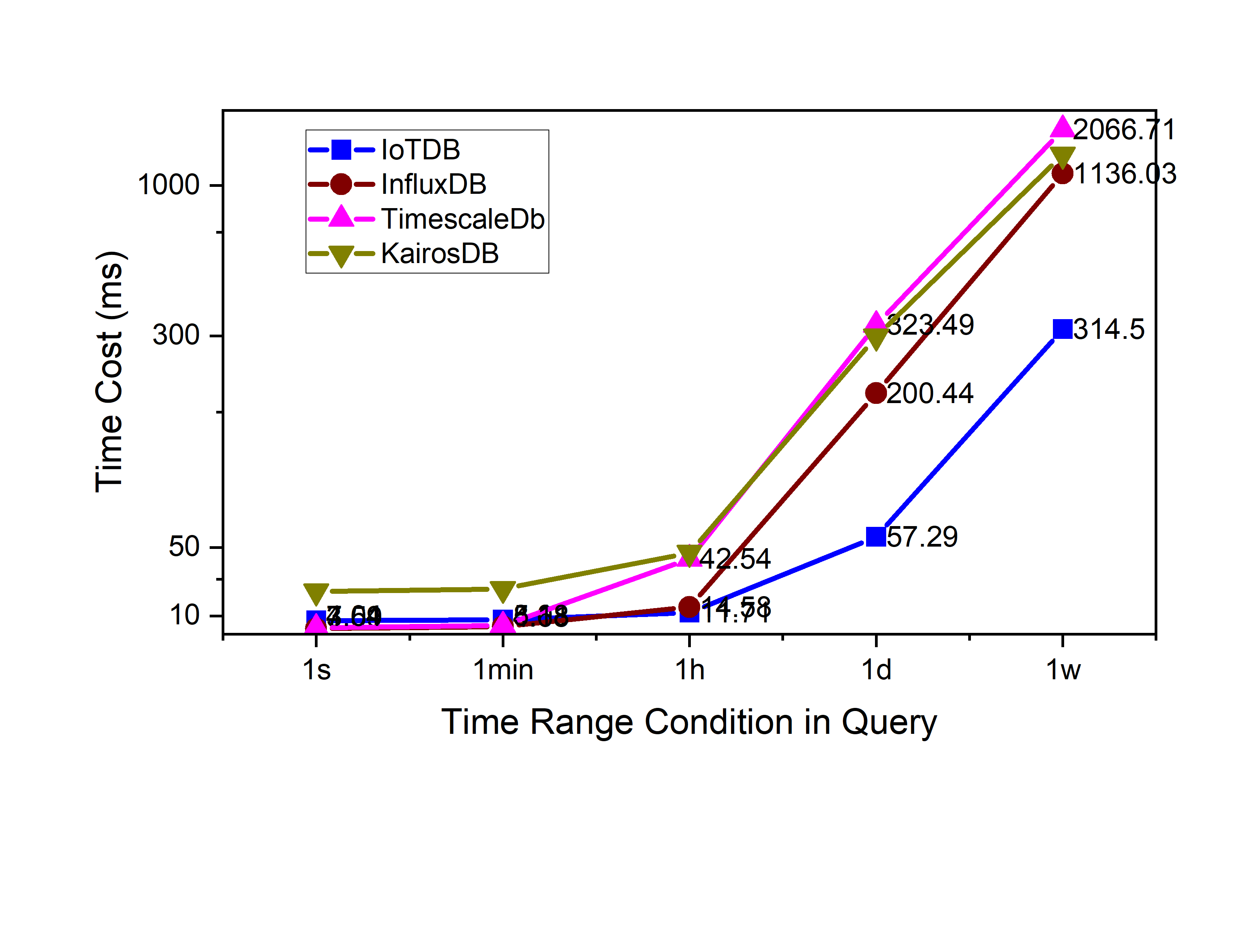
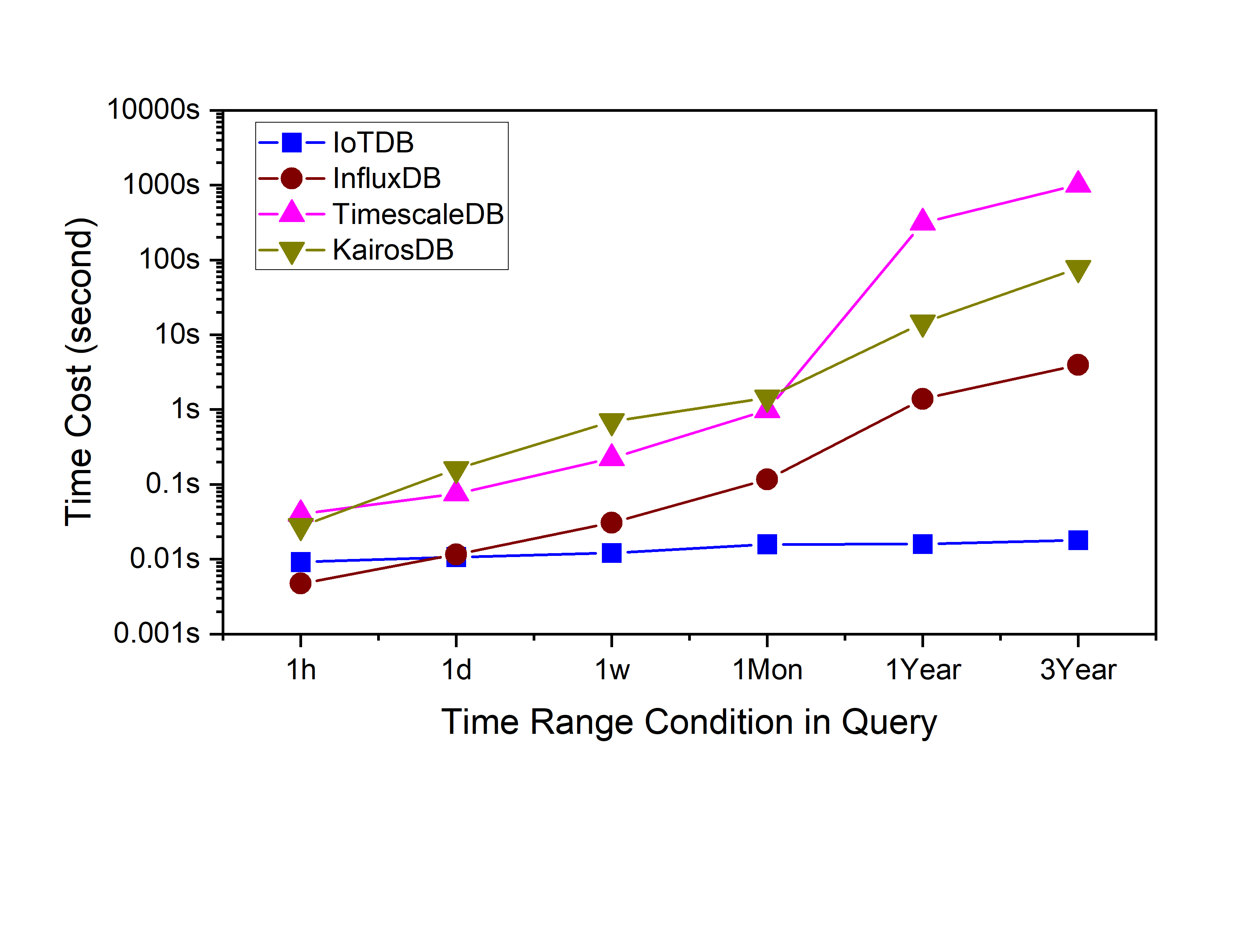
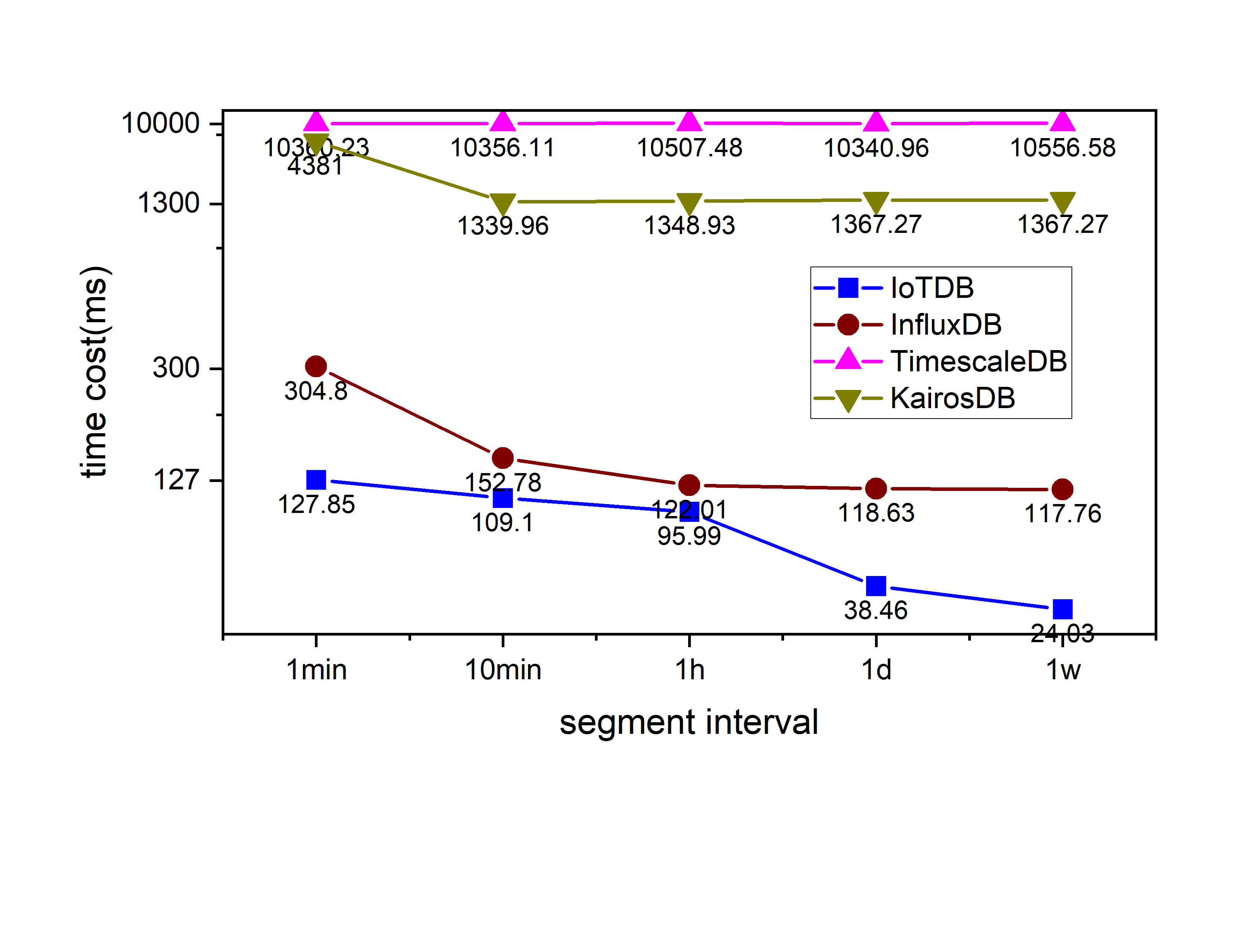
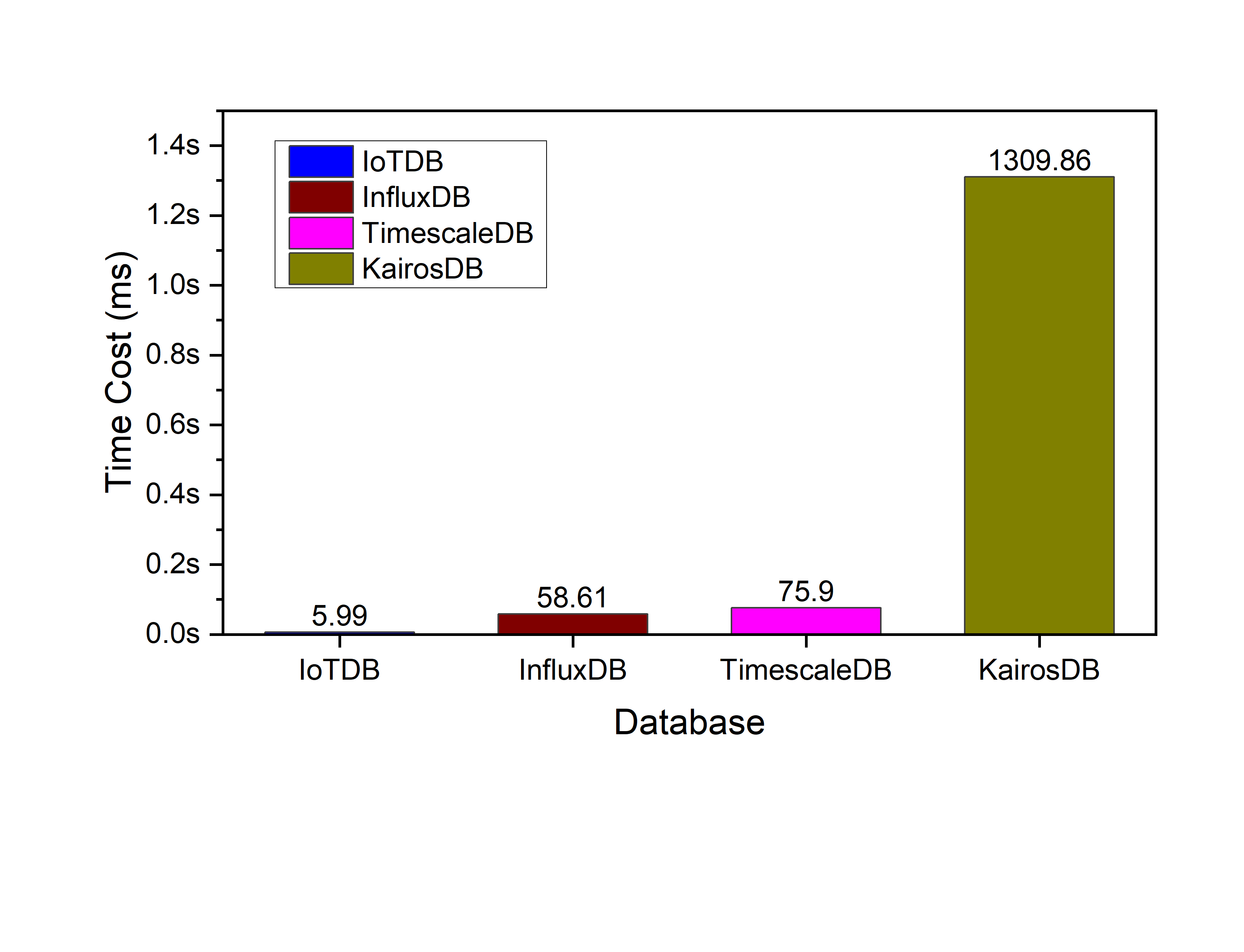
We can see that IoTDB outperforms others.
More details
We provide a benchmarking tool, called IoTDB-benchamrk (https://github.com/thulab/iotdb-benchmark, you may have to use the dev branch to compile it),
it supports IoTDB, InfluxDB, KairosDB, TimescaleDB, OpenTSDB. We have an article for comparing these systems using the benchmark tool.
When we publish the article, IoTDB just entered Apache incubator, so we deleted the performance of IoTDB in that article. But after comparison, some results are presented here.
For InfluxDB, we set the cache-max-memory-size and the max-series-perbase as unlimited (otherwise it will be timeout quickly).
For KairosDB, we set Cassandra's read_repair_chance as 0.1 (However it has no effect because we just have one node).
For TimescaleDB, we use PGTune tool to optimize PostgreSQL.
All TSDBs run on a server with Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz,(8 cores 16 threads), 32GB memory , 256G SSD and 10T HDD.
The OS is Ubuntu 16.04.7 LTS, 64bits.
All clients run on a server with Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz,(6 cores 12 threads), 16GB memory , 256G SSD.
The OS is Ubuntu 16.04.7 LTS, 64bits.
Conclusion
From all above experiments, we can see that IoTDB outperforms others hugely.
IoTDB has the minimal write latency. The larger the batch size, the higher the write throughput of IoTDB. This indicates that IoTDB is most suitable for batch data writing scenarios.
In high concurrency scenarios, IoTDB can also maintain a steady growth in throughput. (12 million points per second may have reached the limit of gigabit network card)
In raw data query, as the query scope increases, the advantages of IoTDB begin to manifest. Because the granularity of data blocks is larger and the advantages of columnar storage are used, column-based compression and columnar iterators will both accelerate the query.
In aggregation query, we use the statistics of the file layer and cache the statistics. Therefore, multiple queries only need to perform memory calculations (do not need to traverse the original data points, and do not need to access the disk), so the aggregation performance advantage is obvious.
Downsampling query scenarios is more interesting, as the time partition becomes larger and larger, the query performance of IoTDB increases gradually. Probably it has risen twice, which corresponds to the pre-calculated information of 2 granularities(3 hours and 4.5 days). Therefore, the queries in the range of 1 day and 1 week are accelerated respectively. The other databases only rose once, indicating that they only have one granular statistics.
If you are considering a TSDB for your IIoT application, Apache IoTDB, a new time series database, is your best choice.
We will update this page once we release new version and finish the experiments.
We also welcome more contributors correct this article and contribute IoTDB and reproduce experiments.