Scenario
- Scenario 1
A company uses surface mount technology (SMT) to produce chips: it is necessary to first print solder paste on the joints of the chip, then place the components on the solder paste, and then melt the solder paste by heating and cool it. Finally, the components are soldered to the chip.
The above process uses an automated production line. In order to ensure the quality of the product, after printing the solder paste, the quality of the solder paste printing needs to be evaluated by optical equipment. The volume (v), height (h), area (a), horizontal offset (px), and vertical offset (py) of the solder paste on each joint are measured by a three-dimensional solder paste printing (SPI) device.
In order to improve the quality of the printing, it is necessary for the company to store the metrics of the solder joints on each chip for subsequent analysis based on these data.
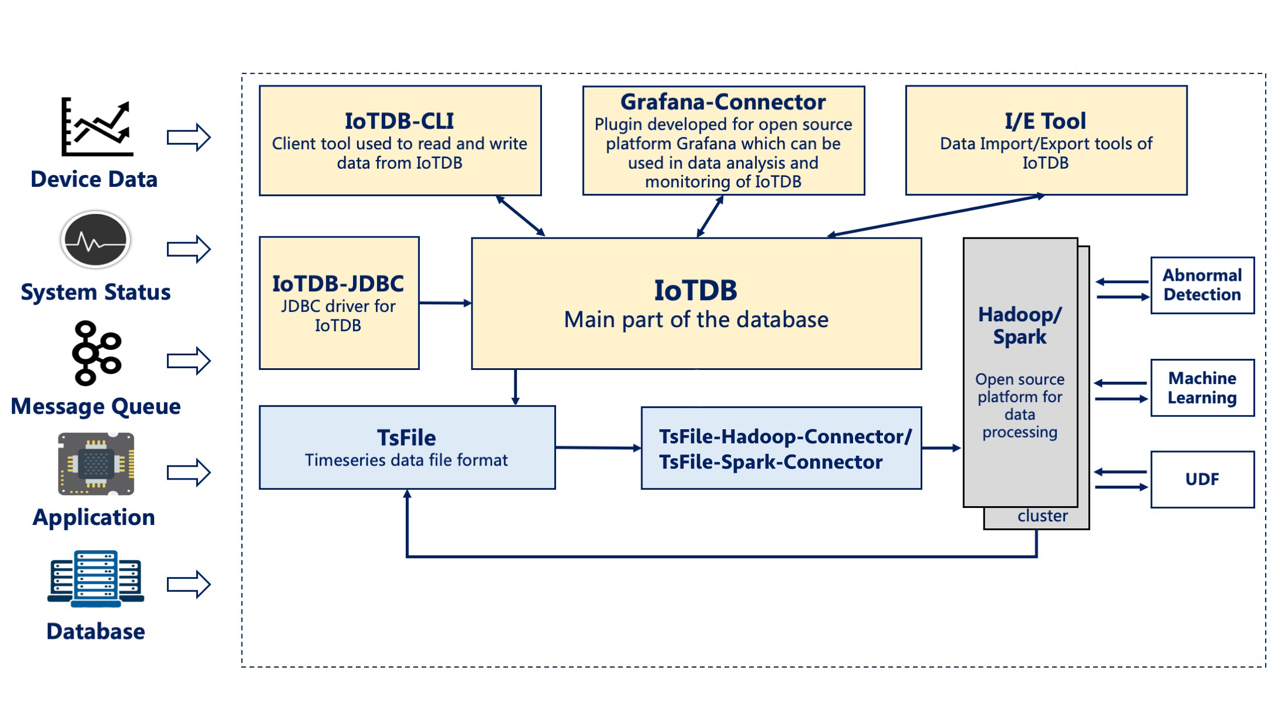
At this point, the data can be stored using TsFile component, TsFileSync tool, and Hadoop/Spark integration component in the IoTDB suite.That is, each time a new chip is printed, a data is written on the SPI device using the SDK, which ultimately forms a TsFile. Through the TsFileSync tool, the generated TsFile will be synchronized to the data center according to certain rules (such as daily) and analyzed by data analysts tools.
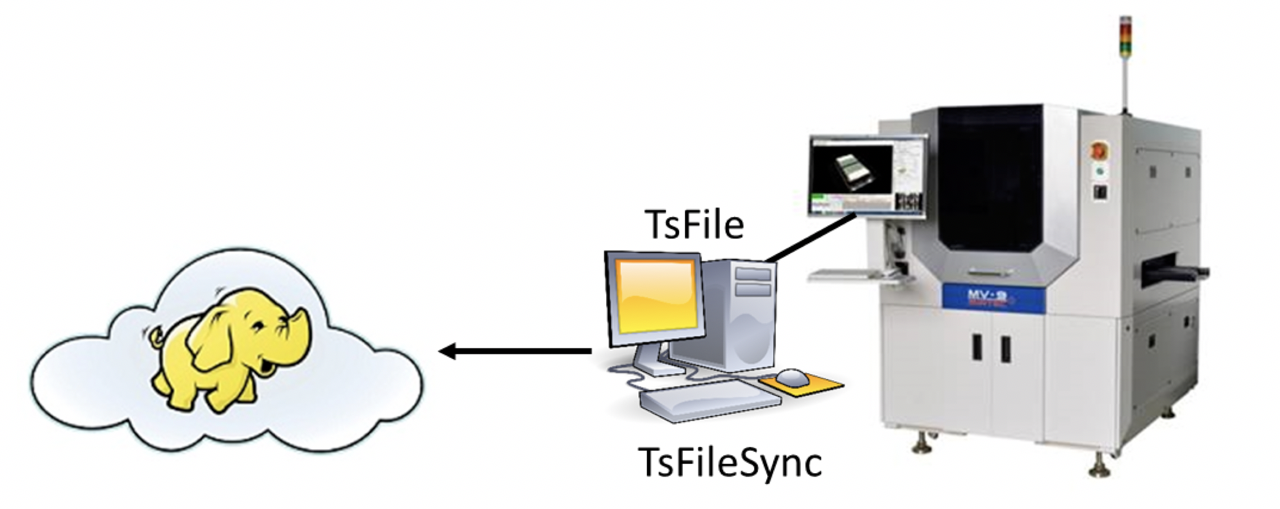
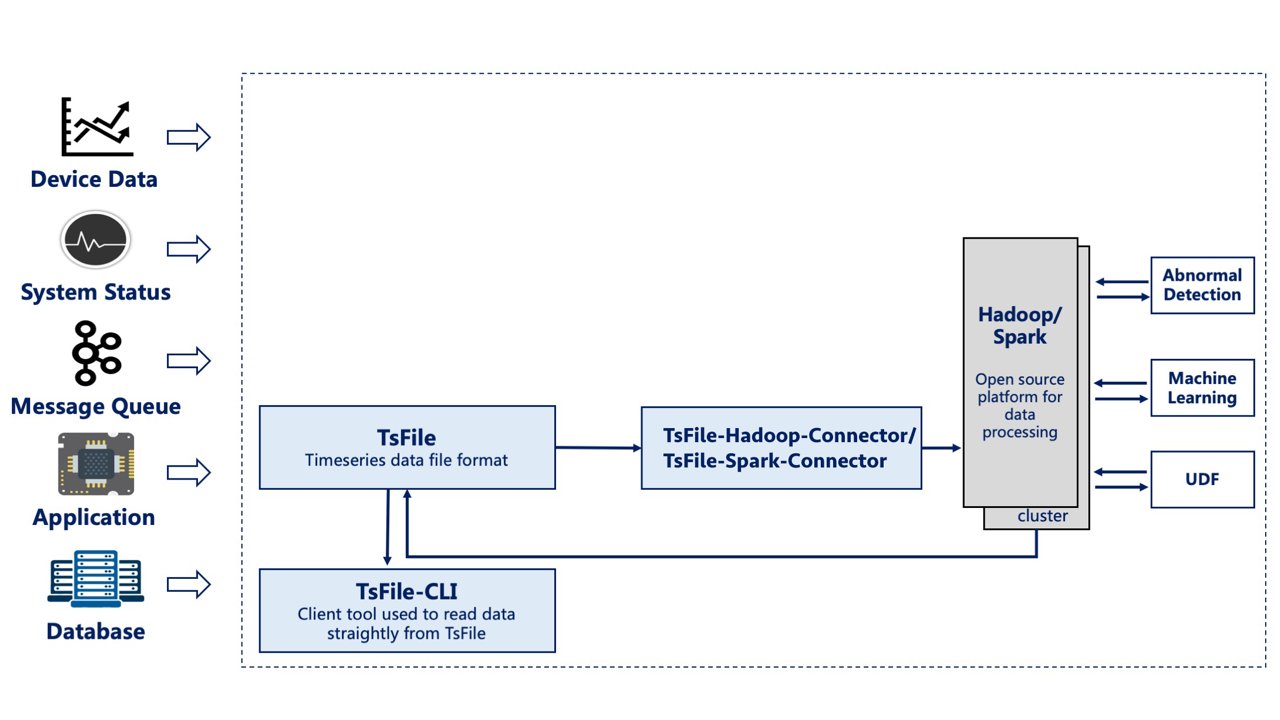
In this scenario, only TsFile and TsFileSync are required to be deployed on a PC, and a Hadoop/Spark cluster is required. Figure below shows the architecture at this time.
- Scenario 2
A company has several wind turbines which are installed hundreds of sensors on each generator to collect information such as the working status of the generator and the wind speed in the working environment.
In order to ensure the normal operation of the turbines and timely monitoring and analysis of the turbines, the company needs to collect these sensor data, perform partial calculation and analysis in the turbines working environment, and upload the original data collected to the data center.
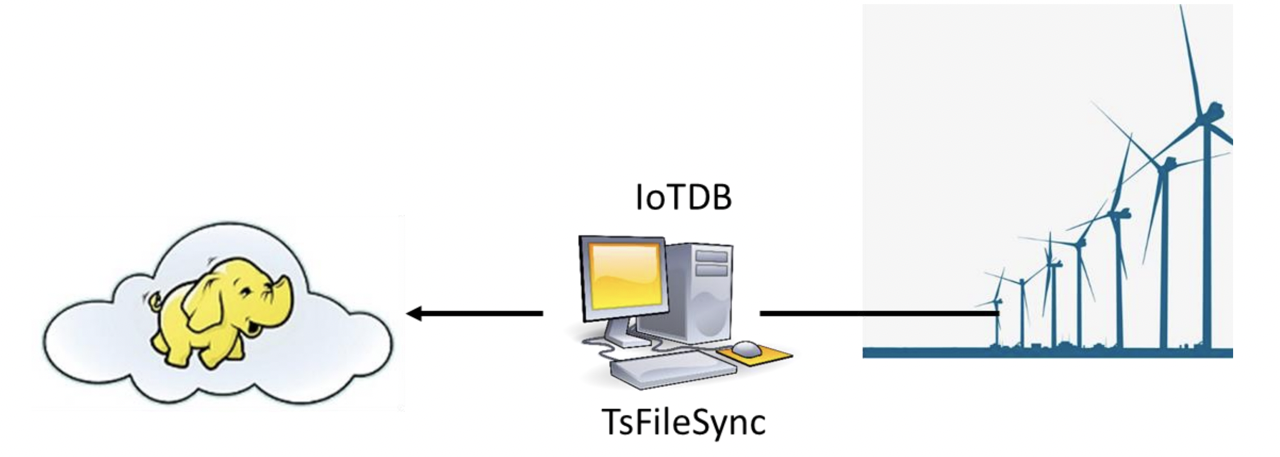
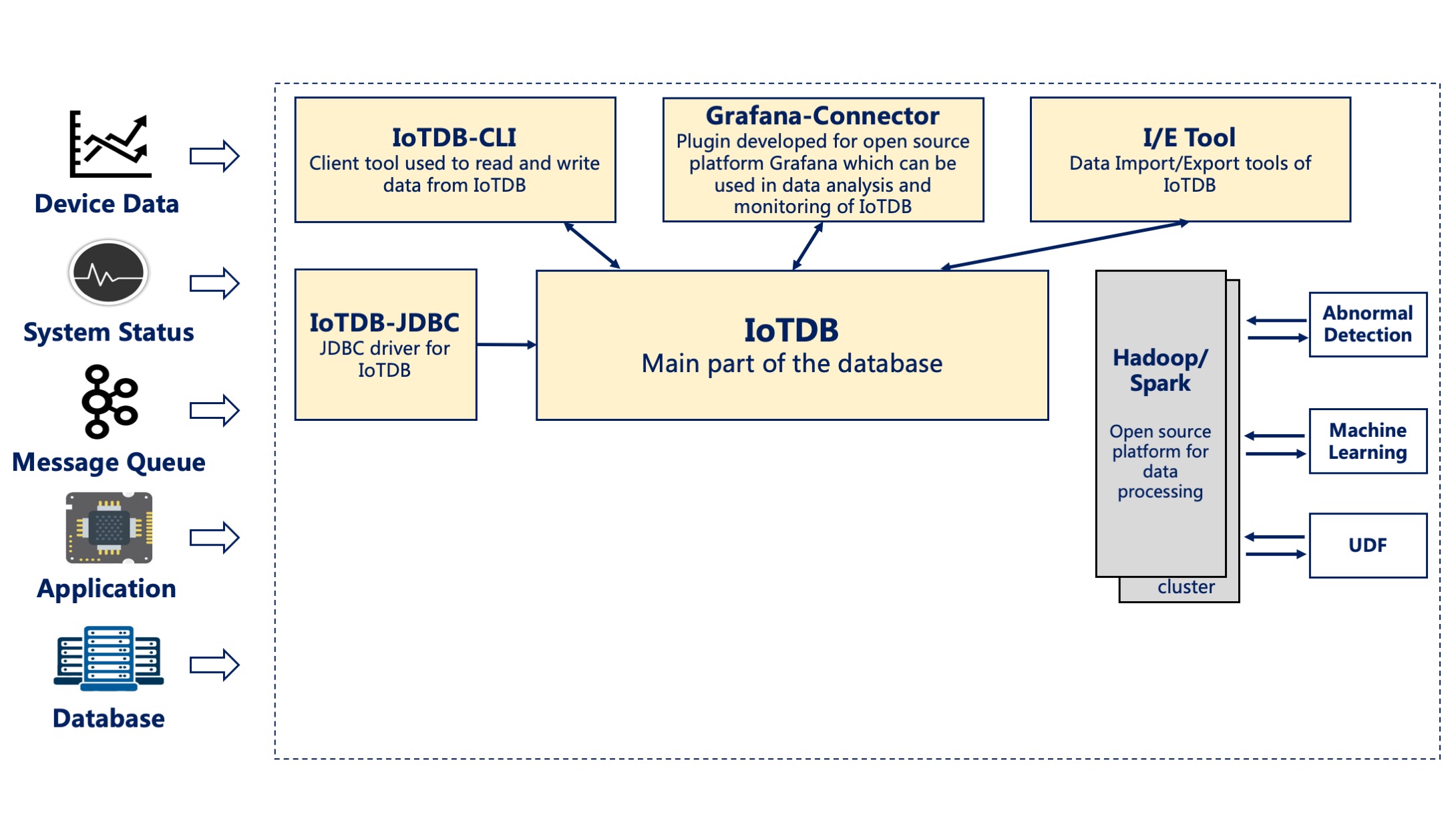
In this situation, IoTDB, TsFileSync tools, and Hadoop/Spark integration components in the IoTDB suite can be used. A PC needs to be deployed with IoTDB and TsFileSync tools installed to support reading and writing data, local computing and analysis, and uploading data to the data center. In addition, Hadoop/Spark clusters need to be deployed for data storage and analysis on the data center side. Figure below shows the architecture at this time.
- Scenario 3
A factory has a variety of robotic equipment within the plant area. These robotic equipment have limited hardware and are difficult to carry complex applications.
A variety of sensors are installed on each robotic device to monitor the robot's operating status, temperature, and other information. Due to the network environment of the factory, the robots inside the factory are all within the LAN of the factory and cannot connect to the external network. But there will be several servers in the factory that can connect directly to the external public network.
In order to ensure that the data of the robot can be monitored and analyzed in time, the company needs to collect the information of these robot sensors, send them to the server that can connect to the external network, and then upload the original data information to the data center for complex calculation and analysis.
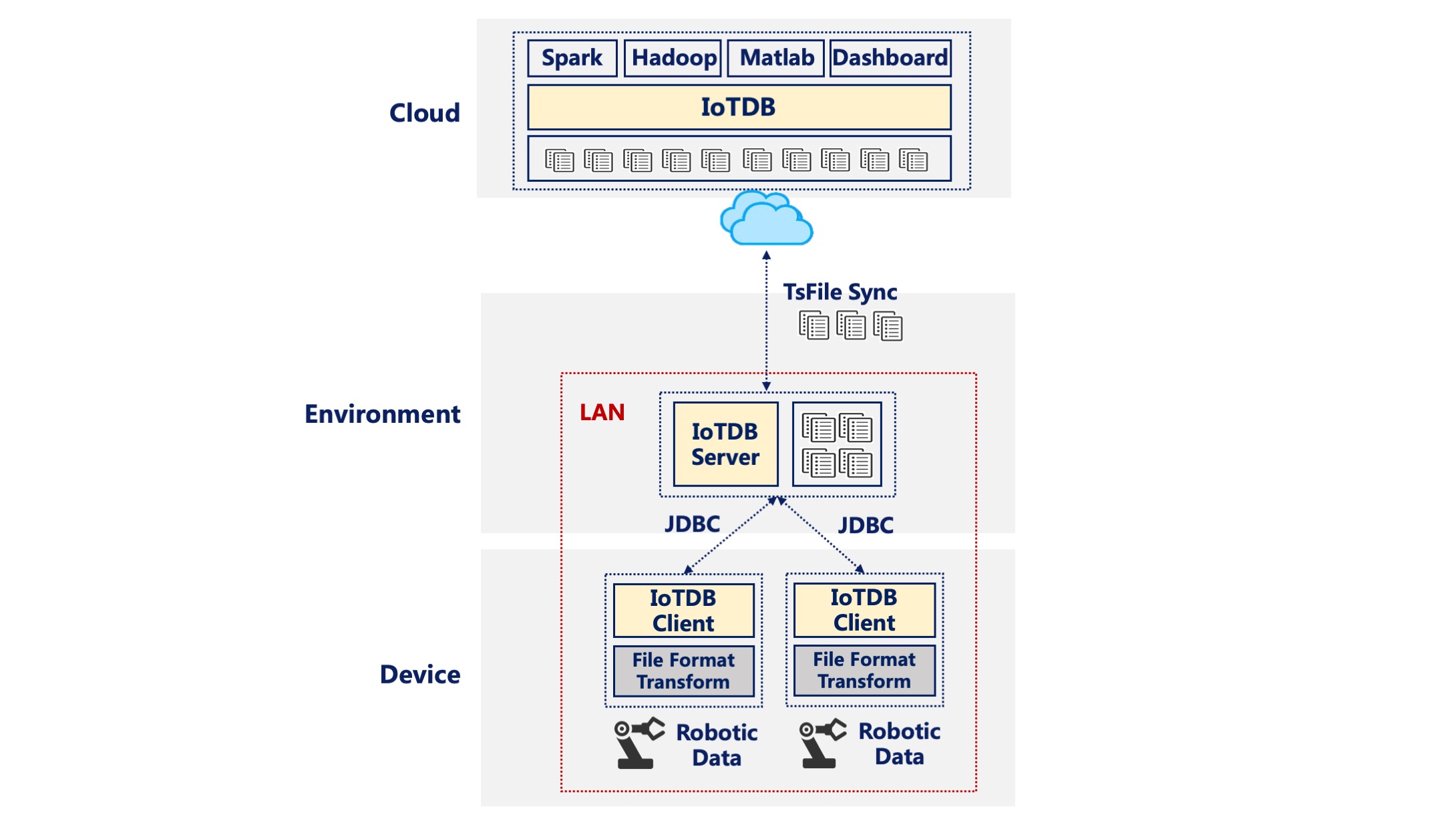
At this point, IoTDB, IoTDB-Client tools, TsFileSync tools, and Hadoop/Spark integration components in the IoTDB suite can be used. IoTDB-Client tool is installed on the robot and each of them is connected to the LAN of the factory. When sensors generate real-time data, the data will be uploaded to the server in the factory. The IoTDB server and TsFileSync is installed on the server connected to the external network. Once triggered, the data on the server will be upload to the data center. In addition, Hadoop/Spark clusters need to be deployed for data storage and analysis on the data center side. The Figure below shows the architecture at this time.
- Scenario 4
A car company installed sensors on its cars to collect monitoring information such as the driving status of the vehicle. These automotive devices have limited hardware configurations and are difficult to carry complex applications. Cars with sensors can be connected to each other or send data via narrow-band IoT.
In order to receive the IoT data collected by the car sensor in real time, the company needs to send the sensor data to the data center in real time through the narrowband IoT while the vehicle is running. Thus, they can perform complex calculations and analysis on the server in the data center.
At this point, IoTDB, IoTDB-Client, and Hadoop/Spark integration components in the IoTDB suite can be used. IoTDB-Client tool is installed on each car and use IoTDB-JDBC tool to send data directly back to the server in the data center.
In addition, Hadoop/Spark clusters need to be deployed for data storage and analysis on the data center side. As shown in Figure below.
