Data Model
Data Model
A wind power IoT scenario is taken as an example to illustrate how to creat a correct data model in IoTDB.
According to the enterprise organization structure and equipment entity hierarchy, it is expressed as an attribute hierarchy structure, as shown below. The hierarchical from top to bottom is: power group layer - power plant layer - entity layer - measurement layer. ROOT is the root node, and each node of measurement layer is a leaf node. In the process of using IoTDB, the attributes on the path from ROOT node is directly connected to each leaf node with ".", thus forming the name of a timeseries in IoTDB. For example, The left-most path in Figure 2.1 can generate a timeseries named root.ln.wf01.wt01.status.
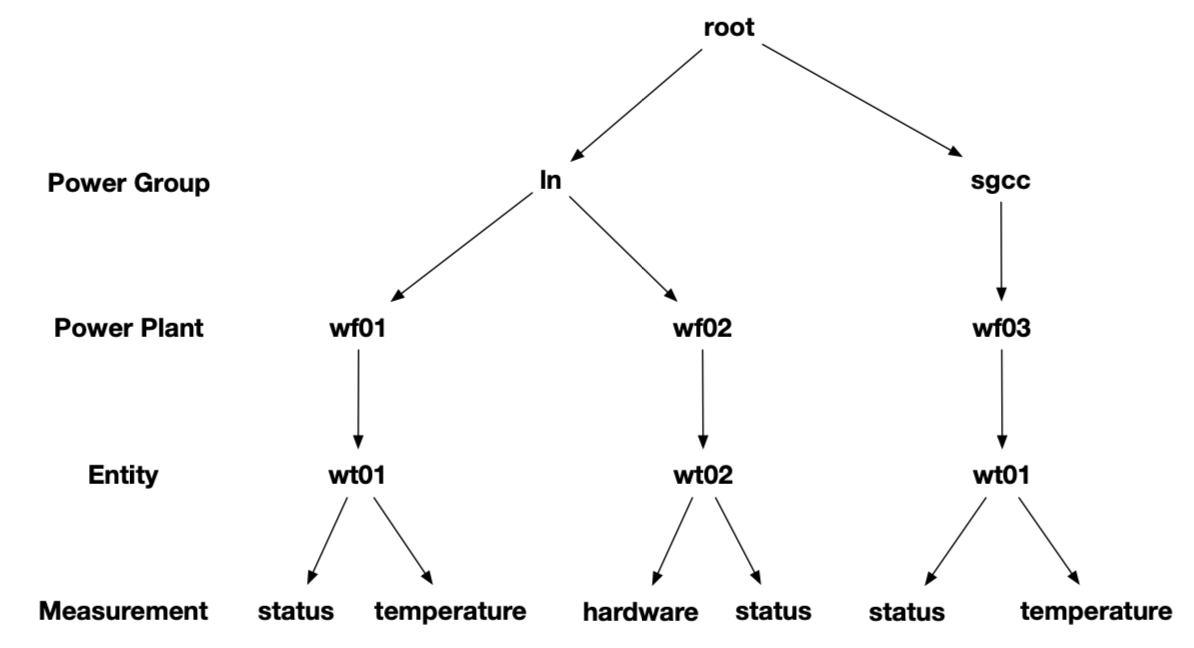
Here are the basic concepts of the model involved in IoTDB.
Measurement, Entity, Storage Group, Path
Measurement (Also called field)
It is information measured by detection equipment in an actual scene and can transform the sensed information into an electrical signal or other desired form of information output and send it to IoTDB. In IoTDB, all data and paths stored are organized in units of measurements.
Entity (Also called device)
An entity is an equipped with measurements in real scenarios. In IoTDB, all measurements should have their corresponding entities.
Storage Group
A group of entities. Users can set any prefix path as a storage group. Provided that there are four timeseries root.ln.wf01.wt01.status, root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware, root.ln.wf02.wt02.status, two devices wf01, wf02 under the path root.ln may belong to the same owner or the same manufacturer, so d1 and d2 are closely related. At this point, the prefix path root.vehicle can be designated as a storage group, which will enable IoTDB to store all devices under it in the same folder. Newly added devices under root.ln will also belong to this storage group.
Note1: A full path (
root.ln.wf01.wt01.statusas in the above example) is not allowed to be set as a storage group.Note2: The prefix of a timeseries must belong to a storage group. Before creating a timeseries, users must set which storage group the series belongs to. Only timeseries whose storage group is set can be persisted to disk.
Once a prefix path is set as a storage group, the storage group settings cannot be changed.
After a storage group is set, the ancestral layers, children and descendant layers of the corresponding prefix path are not allowed to be set up again (for example, after root.ln is set as the storage group, the root layer and root.ln.wf01 are not allowed to be set as storage groups).
The Layer Name of storage group can only consist of characters, numbers and underscores, like root.storagegroup_1.
Schema-less writing: When metadata is not defined, data can be directly written through an insert statement, and the required metadata will be automatically identified and registered in the storage group, achieving automatic modeling.
Path
A path is an expression that conforms to the following constraints:
path
: layer_name ('.' layer_name)*
;
layer_name
: wildcard? id wildcard?
| wildcard
;
wildcard
: '*'
| '**'
;You can refer to the definition of id in Syntax-Conventions.
We call the part of a path divided by '.' as a layer (layer_name). For example: root.a.b.c is a path with 4 layers.
The following are the constraints on the layer (layer_name):
rootis a reserved character, and it is only allowed to appear at the beginning layer of the time series mentioned below. Ifrootappears in other layers, it cannot be parsed and an error will be reported.Except for the beginning layer (
root) of the time series, the characters supported in other layers are as follows:- Chinese characters:
"\u2E80"to"\u9FFF" _:@#${}"A"to"Z","a"to"z","0"to"9"
- Chinese characters:
In addition to the beginning layer (
root) of the time series and the storage group layer, other layers also support the use of special strings referenced by ` or"as its name. It should be noted that the quoted string cannot contain.characters. Here are some legal examples:Layer (
layer_name) cannot start with a digit unless the layer(layer_name) is quoted with ` or".In particular, if the system is deployed on a Windows machine, the storage group layer name will be case-insensitive. For example, creating both
root.lnandroot.LNat the same time is not allowed.
Path Pattern
In order to make it easier and faster to express multiple timeseries paths, IoTDB provides users with the path pattern. Users can construct a path pattern by using wildcard * and **. Wildcard can appear in any layer of the path.
* represents one layer. For example, root.vehicle.*.sensor1 represents a 4-layer path which is prefixed with root.vehicle and suffixed with sensor1.
** represents (*)+, which is one or more layers of *. For example, root.vehicle.device1.** represents all paths prefixed by root.vehicle.device1 with layers greater than or equal to 4, like root.vehicle.device1.*, root.vehicle.device1.*.*, root.vehicle.device1.*.*.*, etc; root.vehicle.**.sensor1 represents a path which is prefixed with root.vehicle and suffixed with sensor1 and has at least 4 layers.
Note1: Wildcard
*and**cannot be placed at the beginning of the path.
Timeseries
Timestamp
The timestamp is the time point at which data is produced. It includes absolute timestamps and relative timestamps. For detailed description, please go to Data Type doc.
Data point
A "time-value" pair.
Timeseries
The record of a measurement of an entity on the time axis. Timeseries is a series of data points.
A measurement of an entity corresponds to a timeseries.
Also called meter, timeline, and tag, parameter in real time database.
For example, if entity wt01 in power plant wf01 of power group ln has a measurement named status, its timeseries can be expressed as: root.ln.wf01.wt01.status.
Aligned timeseries
There is a situation that multiple measurements of an entity are sampled simultaneously in practical applications, forming multiple timeseries aligned on a time column.
By using aligned timeseries, the timestamp columns of a group of aligned timeseries need to be stored only once in memory and disk when inserting data, instead of once per timeseries.
It would be best if you created a group of aligned timeseries at the same time.
You cannot create non-aligned timeseries under the entity to which the aligned timeseries belong, nor can you create aligned timeseries under the entity to which the non-aligned timeseries belong.
When querying, you can query each timeseries separately.
When inserting data, it is allowed to insert null value in the aligned timeseries.
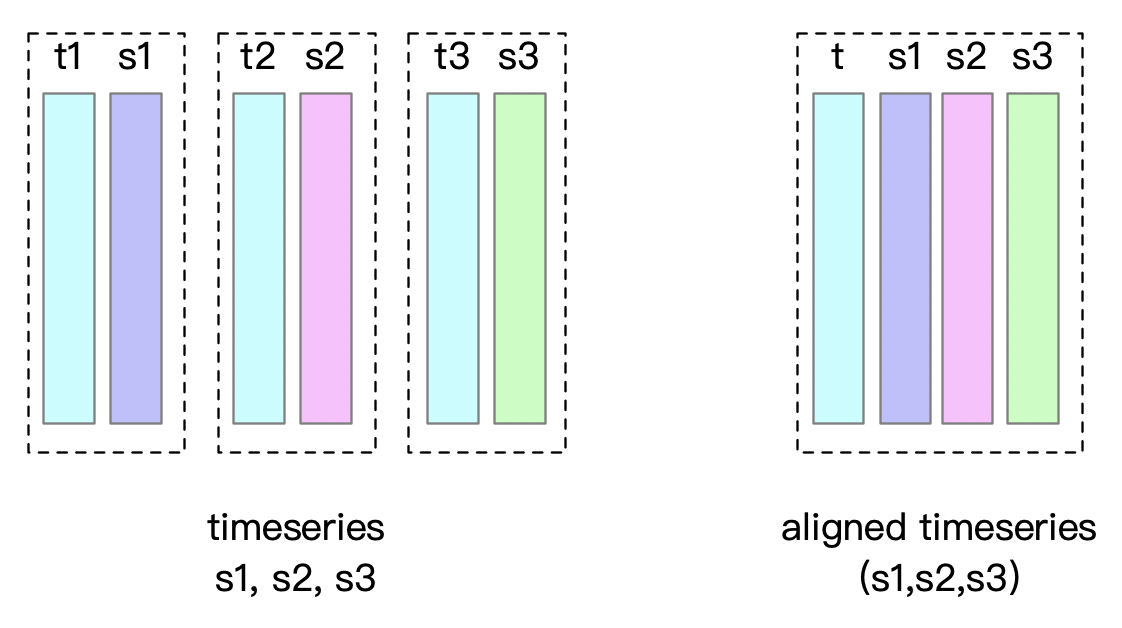
In the following chapters of data definition language, data operation language and Java Native Interface, various operations related to aligned timeseries will be introduced one by one.
Schema Template
In the actual scenario, many entities collect the same measurements, that is, they have the same measurements name and type. A schema template can be declared to define the collectable measurements set. Schema template helps save memory by implementing schema sharing. For detailed description, please refer to Schema Template doc.
In the following chapters of, data definition language, data operation language and Java Native Interface, various operations related to schema template will be introduced one by one.