SQL手册
SQL手册
1. 元数据操作
1.1 数据库管理
创建数据库
CREATE DATABASE root.ln;查看数据库
show databases;
show databases root.*;
show databases root.**;删除数据库
DELETE DATABASE root.ln;
DELETE DATABASE root.sgcc;
DELETE DATABASE root.**;统计数据库数量
count databases;
count databases root.*;
count databases root.sgcc.*;
count databases root.sgcc;1.2 时间序列管理
创建时间序列
create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN;
create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT;
create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT;
create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN;
create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN;
create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT;- 简化版
create timeseries root.ln.wf01.wt01.status BOOLEAN;
create timeseries root.ln.wf01.wt01.temperature FLOAT;
create timeseries root.ln.wf02.wt02.hardware TEXT;
create timeseries root.ln.wf02.wt02.status BOOLEAN;
create timeseries root.sgcc.wf03.wt01.status BOOLEAN;
create timeseries root.sgcc.wf03.wt01.temperature FLOAT;- 错误提示
create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF;
error: encoding TS_2DIFF does not support BOOLEAN创建对齐时间序列
CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT, longitude FLOAT);删除时间序列
delete timeseries root.ln.wf01.wt01.status;
delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware;
delete timeseries root.ln.wf02.*;
drop timeseries root.ln.wf02.*;查看时间序列
SHOW TIMESERIES;
SHOW TIMESERIES <Path>;
SHOW TIMESERIES root.**;
SHOW TIMESERIES root.ln.**;
SHOW TIMESERIES root.ln.** limit 10 offset 10;
SHOW TIMESERIES root.ln.** where timeseries contains 'wf01.wt';
SHOW TIMESERIES root.ln.** where dataType=FLOAT;
SHOW TIMESERIES root.ln.** where time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;
SHOW LATEST TIMESERIES;统计时间序列数量
COUNT TIMESERIES root.**;
COUNT TIMESERIES root.ln.**;
COUNT TIMESERIES root.ln.*.*.status;
COUNT TIMESERIES root.ln.wf01.wt01.status;
COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc';
COUNT TIMESERIES root.** WHERE DATATYPE = INT64;
COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c';
COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c';
COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1;
COUNT TIMESERIES root.** WHERE time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;
COUNT TIMESERIES root.** GROUP BY LEVEL=1;
COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2;
COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2;标签点管理
create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2);- 重命名标签或属性
ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1;- 重新设置标签或属性的值
ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1;- 删除已经存在的标签或属性
ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2;- 添加新的标签
ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4;- 添加新的属性
ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4;- 更新插入别名,标签和属性
ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag2=newV2, tag3=v3) ATTRIBUTES(attr3=v3, attr4=v4);- 使用标签作为过滤条件查询时间序列
SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause;返回给定路径的下的所有满足条件的时间序列信息:
ALTER timeseries root.ln.wf02.wt02.hardware ADD TAGS unit=c;
ALTER timeseries root.ln.wf02.wt02.status ADD TAGS description=test1;
show timeseries root.ln.** where TAGS(unit)='c';
show timeseries root.ln.** where TAGS(description) contains 'test1';- 使用标签作为过滤条件统计时间序列数量
COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause;
COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=<INTEGER>;返回给定路径的下的所有满足条件的时间序列的数量:
count timeseries;
count timeseries root.** where TAGS(unit)='c';
count timeseries root.** where TAGS(unit)='c' group by level = 2;创建对齐时间序列:
create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4));支持查询:
show timeseries where TAGS(tag1)='v1';1.3 时间序列路径管理
查看路径的所有子路径
SHOW CHILD PATHS pathPattern;
- 查询 root.ln 的下一层;
show child paths root.ln;
- 查询形如 root.xx.xx.xx 的路径;
show child paths root.*.*;查看路径的所有子节点
SHOW CHILD NODES pathPattern;
- 查询 root 的下一层;
show child nodes root;
- 查询 root.ln 的下一层;
show child nodes root.ln;查看设备
show devices;
show devices root.ln.**;
show devices where time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;查看设备及其 database 信息
show devices with database;
show devices root.ln.** with database;统计节点数
COUNT NODES root.** LEVEL=2;
COUNT NODES root.ln.** LEVEL=2;
COUNT NODES root.ln.wf01.* LEVEL=3;
COUNT NODES root.**.temperature LEVEL=3;统计设备数量
count devices;
count devices root.ln.**;
count devices where time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;1.4 设备模板管理
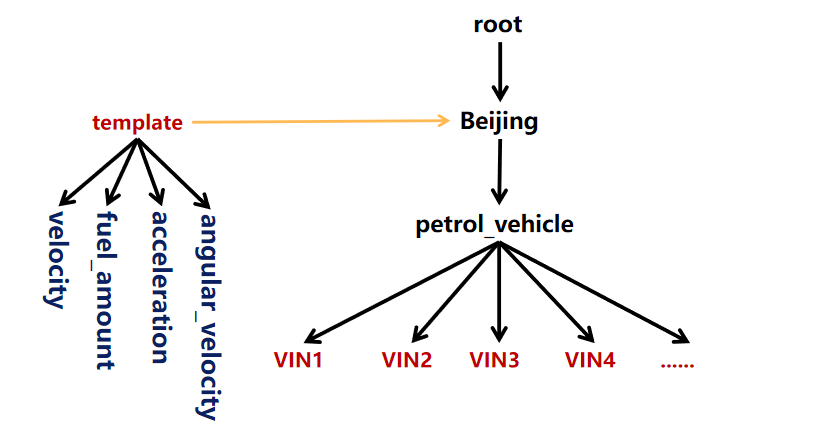
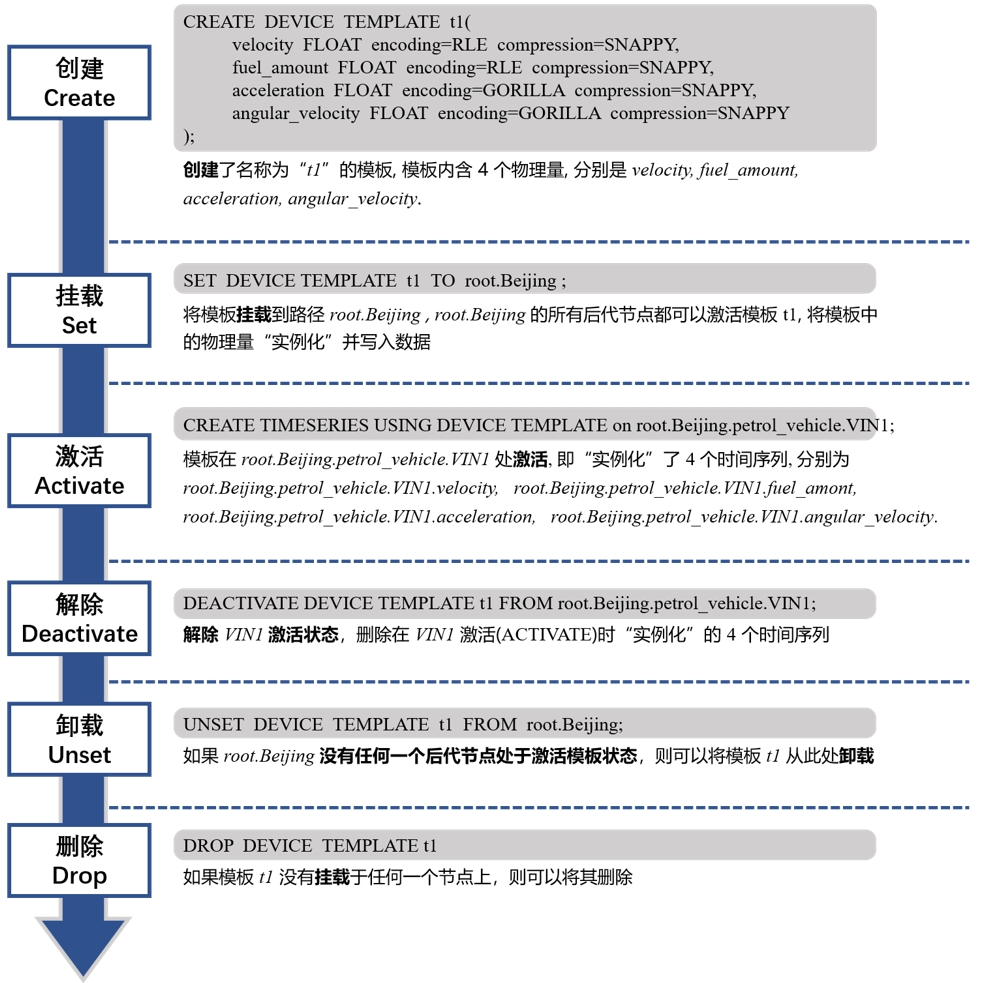
创建设备模板
CREATE DEVICE TEMPLATE <templateName> ALIGNED? '(' <measurementId> <attributeClauses> [',' <measurementId> <attributeClauses>]+ ')';创建包含两个非对齐序列的设备模板
create device template t1 (temperature FLOAT, status BOOLEAN);创建包含一组对齐序列的设备模板
create device template t2 aligned (lat FLOAT, lon FLOAT);挂载设备模板
set DEVICE TEMPLATE t1 to root.sg1;激活设备模板
create timeseries using DEVICE TEMPLATE on root.sg1.d1;
set DEVICE TEMPLATE t1 to root.sg1.d1;
set DEVICE TEMPLATE t2 to root.sg1.d2;
create timeseries using device template on root.sg1.d1;
create timeseries using device template on root.sg1.d2;查看设备模板
show device templates;- 查看某个设备模板下的物理量
show nodes in device template t1;- 查看挂载了某个设备模板的路径
show paths set device template t1;- 查看使用了某个设备模板的路径(即模板在该路径上已激活,序列已创建)
show paths using device template t1;解除设备模板
delete timeseries of device template t1 from root.sg1.d1;
deactivate device template t1 from root.sg1.d1;批量处理
delete timeseries of device template t1 from root.sg1.*, root.sg2.*;
deactivate device template t1 from root.sg1.*, root.sg2.*;卸载设备模板
unset device template t1 from root.sg1.d1;删除设备模板
drop device template t1;1.5 数据存活时间管理
设置 TTL
set ttl to root.ln 3600000;
set ttl to root.sgcc.** 3600000;
set ttl to root.** 3600000;取消 TTL
unset ttl from root.ln;
unset ttl from root.sgcc.**;
unset ttl from root.**;显示 TTL
SHOW ALL TTL;
SHOW TTL ON pathPattern;
show DEVICES;2. 写入数据
2.1 写入单列数据
insert into root.ln.wf02.wt02(timestamp,status) values(1,true);
insert into root.ln.wf02.wt02(timestamp,hardware) values(1, 'v1'),(2, 'v1');2.2 写入多列数据
insert into root.ln.wf02.wt02(timestamp, status, hardware) values (2, false, 'v2');
insert into root.ln.wf02.wt02(timestamp, status, hardware) VALUES (3, false, 'v3'),(4, true, 'v4');2.3 使用服务器时间戳
insert into root.ln.wf02.wt02(status, hardware) values (false, 'v2');2.4 写入对齐时间序列数据
create aligned timeseries root.sg1.d1(s1 INT32, s2 DOUBLE);
insert into root.sg1.d1(timestamp, s1, s2) aligned values(1, 1, 1);
insert into root.sg1.d1(timestamp, s1, s2) aligned values(2, 2, 2), (3, 3, 3);
select * from root.sg1.d1;2.5 加载 TsFile 文件数据
load '<path/dir>' [sglevel=int][onSuccess=delete/none]
通过指定文件路径(绝对路径)加载单 tsfile 文件
load '/Users/Desktop/data/1575028885956-101-0.tsfile'load '/Users/Desktop/data/1575028885956-101-0.tsfile' sglevel=1load '/Users/Desktop/data/1575028885956-101-0.tsfile' onSuccess=deleteload '/Users/Desktop/data/1575028885956-101-0.tsfile' sglevel=1 onSuccess=delete
通过指定文件夹路径(绝对路径)批量加载文件
load '/Users/Desktop/data'load '/Users/Desktop/data' sglevel=1load '/Users/Desktop/data' onSuccess=deleteload '/Users/Desktop/data' sglevel=1 onSuccess=delete
3. 删除数据
3.1 删除单列数据
delete from root.ln.wf02.wt02.status where time<=2017-11-01T16:26:00;
delete from root.ln.wf02.wt02.status where time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;
delete from root.ln.wf02.wt02.status where time < 10;
delete from root.ln.wf02.wt02.status where time <= 10;
delete from root.ln.wf02.wt02.status where time < 20 and time > 10;
delete from root.ln.wf02.wt02.status where time <= 20 and time >= 10;
delete from root.ln.wf02.wt02.status where time > 20;
delete from root.ln.wf02.wt02.status where time >= 20;
delete from root.ln.wf02.wt02.status where time = 20;出错:
delete from root.ln.wf02.wt02.status where time > 4 or time < 0;
Msg: 303: Check metadata error: For delete statement, where clause can only contain atomic expressions like : time > XXX, time <= XXX, or two atomic expressions connected by 'AND'删除时间序列中的所有数据:
delete from root.ln.wf02.wt02.status;3.2 删除多列数据
delete from root.ln.wf02.wt02.* where time <= 2017-11-01T16:26:00;声明式的编程方式:
delete from root.ln.wf03.wt02.status where time < now();
Msg: The statement is executed successfully.4. 数据查询
4.1 基础查询
时间过滤查询
select temperature from root.ln.wf01.wt01 where time < 2017-11-01T00:08:00.000;根据一个时间区间选择多列数据
select status, temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;按照多个时间区间选择同一设备的多列数据
select status, temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);按照多个时间区间选择不同设备的多列数据
select wf01.wt01.status, wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);根据时间降序返回结果集
select * from root.ln.** where time > 1 order by time desc limit 10;4.2 选择表达式
使用别名
select s1 as temperature, s2 as speed from root.ln.wf01.wt01;运算符
函数
不支持:
select s1, count(s1) from root.sg.d1;
select sin(s1), count(s1) from root.sg.d1;
select s1, count(s1) from root.sg.d1 group by ([10,100),10ms);时间序列查询嵌套表达式
示例 1:
select a,
b,
((a + 1) * 2 - 1) % 2 + 1.5,
sin(a + sin(a + sin(b))),
-(a + b) * (sin(a + b) * sin(a + b) + cos(a + b) * cos(a + b)) + 1
from root.sg1;示例 2:
select (a + b) * 2 + sin(a) from root.sg;示例 3:
select (a + *) / 2 from root.sg1;示例 4:
select (a + b) * 3 from root.sg, root.ln;聚合查询嵌套表达式
示例 1:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware)
from root.ln.wf01.wt01;示例 2:
select avg(*),
(avg(*) + 1) * 3 / 2 -1
from root.sg1;示例 3:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware) as custom_sum
from root.ln.wf01.wt01
GROUP BY([10, 90), 10ms);最新点查询
SQL 语法:
select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <whereClause> [ORDER BY TIMESERIES (DESC | ASC)?]查询 root.ln.wf01.wt01.status 的最新数据点
select last status from root.ln.wf01.wt01;查询 root.ln.wf01.wt01 下 status,temperature 时间戳大于等于 2017-11-07T23:50:00 的最新数据点
select last status, temperature from root.ln.wf01.wt01 where time >= 2017-11-07T23:50:00;查询 root.ln.wf01.wt01 下所有序列的最新数据点,并按照序列名降序排列
select last * from root.ln.wf01.wt01 order by timeseries desc;4.3 查询过滤条件
时间过滤条件
选择时间戳大于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time > 2022-01-01T00:05:00.000;选择时间戳等于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time = 2022-01-01T00:05:00.000;选择时间区间 [2017-11-01T00:05:00.000, 2017-11-01T00:12:00.000) 内的数据:
select s1 from root.sg1.d1 where time >= 2022-01-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;值过滤条件
选择值大于 36.5 的数据:
select temperature from root.sg1.d1 where temperature > 36.5;选择值等于 true 的数据:
select status from root.sg1.d1 where status = true;选择区间 [36.5,40] 内或之外的数据:
select temperature from root.sg1.d1 where temperature between 36.5 and 40;select temperature from root.sg1.d1 where temperature not between 36.5 and 40;选择值在特定范围内的数据:
select code from root.sg1.d1 where code in ('200', '300', '400', '500');选择值在特定范围外的数据:
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');选择值为空的数据:
select code from root.sg1.d1 where temperature is null;选择值为非空的数据:
select code from root.sg1.d1 where temperature is not null;模糊查询
查询 root.sg.d1 下 value 含有'cc'的数据
select * from root.sg.d1 where value like '%cc%';查询 root.sg.d1 下 value 中间为 'b'、前后为任意单个字符的数据
select * from root.sg.device where value like '_b_';查询 root.sg.d1 下 value 值为26个英文字符组成的字符串
select * from root.sg.d1 where value regexp '^[A-Za-z]+$';查询 root.sg.d1 下 value 值为26个小写英文字符组成的字符串且时间大于100的
select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100;4.4 分段分组聚合
未指定滑动步长的时间区间分组聚合查询
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);指定滑动步长的时间区间分组聚合查询
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);滑动步长可以小于聚合窗口
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-01 10:00:00), 4h, 2h);按照自然月份的时间区间分组聚合查询
select count(status) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 group by([2017-11-01T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);每个时间间隔窗口内都有数据
select count(status) from root.ln.wf01.wt01 group by([2017-10-31T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);左开右闭区间
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);与分组聚合混合使用
统计降采样后的数据点个数
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d), level=1;加上滑动 Step 的降采样后的结果也可以汇总
select count(status) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d), level=1;路径层级分组聚合
统计不同 database 下 status 序列的数据点个数
select count(status) from root.** group by level = 1;统计不同设备下 status 序列的数据点个数
select count(status) from root.** group by level = 3;统计不同 database 下的不同设备中 status 序列的数据点个数
select count(status) from root.** group by level = 1, 3;查询所有序列下温度传感器 temperature 的最大值
select max_value(temperature) from root.** group by level = 0;查询某一层级下所有传感器拥有的总数据点数
select count(*) from root.ln.** group by level = 2;标签分组聚合
单标签聚合查询
SELECT AVG(temperature) FROM root.factory1.** GROUP BY TAGS(city);多标签聚合查询
SELECT avg(temperature) FROM root.factory1.** GROUP BY TAGS(city, workshop);基于时间区间的标签聚合查询
SELECT AVG(temperature) FROM root.factory1.** GROUP BY ([1000, 10000), 5s), TAGS(city, workshop);差值分段聚合
group by variation(controlExpression[,delta][,ignoreNull=true/false]);delta=0时的等值事件分段
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6);指定ignoreNull为false
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, ignoreNull=false);delta!=0时的差值事件分段
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, 4);条件分段聚合
group by condition(predict,[keep>/>=/=/<=/<]threshold,[,ignoreNull=true/false])查询至少连续两行以上的charging_status=1的数据
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=true);当设置ignoreNull为false时,遇到null值为将其视为一个不满足条件的行,得到结果原先的分组被含null的行拆分
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=false);会话分段聚合
group by session(timeInterval)按照不同的时间单位设定时间间隔
select __endTime,count(*) from root.** group by session(1d);和HAVING、ALIGN BY DEVICE共同使用
select __endTime,sum(hardware) from root.ln.wf02.wt01 group by session(50s) having sum(hardware)>0 align by device;点数分段聚合
group by count(controlExpression, size[,ignoreNull=true/false])select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5);当使用ignoreNull将null值也考虑进来
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5,ignoreNull=false);4.5 聚合结果过滤
不正确的:
select count(s1) from root.** group by ([1,3),1ms) having sum(s1) > s1;
select count(s1) from root.** group by ([1,3),1ms) having s1 > 1;
select count(s1) from root.** group by ([1,3),1ms), level=1 having sum(d1.s1) > 1;
select count(d1.s1) from root.** group by ([1,3),1ms), level=1 having sum(s1) > 1;SQL 示例:
select count(s1) from root.** group by ([1,11),2ms), level=1 having count(s2) > 2;
select count(s1), count(s2) from root.** group by ([1,11),2ms) having count(s2) > 1 align by device;4.6 结果集补空值
FILL '(' PREVIOUS | LINEAR | constant (, interval=DURATION_LITERAL)? ')'PREVIOUS 填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(previous);PREVIOUS 填充并指定填充超时阈值
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(previous, 2m);LINEAR 填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(linear);常量填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(2.0);使用 BOOLEAN 类型的常量填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(true);4.7 查询结果分页
按行分页
基本的 LIMIT 子句
select status, temperature from root.ln.wf01.wt01 limit 10;带 OFFSET 的 LIMIT 子句
select status, temperature from root.ln.wf01.wt01 limit 5 offset 3;LIMIT 子句与 WHERE 子句结合
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time< 2017-11-01T00:12:00.000 limit 5 offset 3;LIMIT 子句与 GROUP BY 子句组合
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) limit 4 offset 3;按列分页
基本的 SLIMIT 子句
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1;带 SOFFSET 的 SLIMIT 子句
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 1;SLIMIT 子句与 GROUP BY 子句结合
select max_value(*) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) slimit 1 soffset 1;SLIMIT 子句与 LIMIT 子句结合
select * from root.ln.wf01.wt01 limit 10 offset 100 slimit 2 soffset 0;4.8 排序
时间对齐模式下的排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time desc;设备对齐模式下的排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by device desc,time asc align by device;在时间戳相等时按照设备名排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time asc,device desc align by device;没有显式指定时
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;对聚合后的结果进行排序
select count(*) from root.ln.** group by ((2017-11-01T00:00:00.000+08:00,2017-11-01T00:03:00.000+08:00],1m) order by device asc,time asc align by device;4.9 查询对齐模式
按设备对齐
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;4.10 查询写回(SELECT INTO)
整体描述
selectIntoStatement
: SELECT
resultColumn [, resultColumn] ...
INTO intoItem [, intoItem] ...
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY groupByTimeClause, groupByLevelClause]
[FILL ({PREVIOUS | LINEAR | constant} (, interval=DURATION_LITERAL)?)]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
;
intoItem
: [ALIGNED] intoDevicePath '(' intoMeasurementName [',' intoMeasurementName]* ')'
;按时间对齐,将 root.sg database 下四条序列的查询结果写入到 root.sg_copy database 下指定的四条序列中
select s1, s2 into root.sg_copy.d1(t1), root.sg_copy.d2(t1, t2), root.sg_copy.d1(t2) from root.sg.d1, root.sg.d2;按时间对齐,将聚合查询的结果存储到指定序列中
select count(s1 + s2), last_value(s2) into root.agg.count(s1_add_s2), root.agg.last_value(s2) from root.sg.d1 group by ([0, 100), 10ms);按设备对齐
select s1, s2 into root.sg_copy.d1(t1, t2), root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;按设备对齐,将表达式计算的结果存储到指定序列中
select s1 + s2 into root.expr.add(d1s1_d1s2), root.expr.add(d2s1_d2s2) from root.sg.d1, root.sg.d2 align by device;使用变量占位符
按时间对齐(默认)
目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
select s1, s2
into root.sg_copy.d1(::), root.sg_copy.d2(s1), root.sg_copy.d1(${3}), root.sg_copy.d2(::)
from root.sg.d1, root.sg.d2;该语句等价于:
select s1, s2
into root.sg_copy.d1(s1), root.sg_copy.d2(s1), root.sg_copy.d1(s2), root.sg_copy.d2(s2)
from root.sg.d1, root.sg.d2;目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
select d1.s1, d1.s2, d2.s3, d3.s4
into ::(s1_1, s2_2), root.sg.d2_2(s3_3), root.${2}_copy.::(s4)
from root.sg;目标设备使用变量占位符 & 目标物理量列表使用变量占位符
select * into root.sg_bk.::(::) from root.sg.**;按设备对齐(使用 ALIGN BY DEVICE)
目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
select s1, s2, s3, s4
into root.backup_sg.d1(s1, s2, s3, s4), root.backup_sg.d2(::), root.sg.d3(backup_${4})
from root.sg.d1, root.sg.d2, root.sg.d3
align by device;目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
select avg(s1), sum(s2) + sum(s3), count(s4)
into root.agg_${2}.::(avg_s1, sum_s2_add_s3, count_s4)
from root.**
align by device;目标设备使用变量占位符 & 目标物理量列表使用变量占位符
select * into ::(backup_${4}) from root.sg.** align by device;指定目标序列为对齐序列
select s1, s2 into root.sg_copy.d1(t1, t2), aligned root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;5. 运维语句
生成对应的查询计划
explain select s1,s2 from root.sg.d1;执行对应的查询语句,并获取分析结果
explain analyze select s1,s2 from root.sg.d1 order by s1;6. 运算符
6.1 算数运算符
更多见文档 Arithmetic Operators and Functions
select s1, - s1, s2, + s2, s1 + s2, s1 - s2, s1 * s2, s1 / s2, s1 % s2 from root.sg.d1;6.2 比较运算符
更多见文档Comparison Operators and Functions
-- Basic comparison operators;
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
-- `BETWEEN ... AND ...` operator;
select temperature from root.sg1.d1 where temperature between 36.5 and 40;
select temperature from root.sg1.d1 where temperature not between 36.5 and 40;
-- Fuzzy matching operator: Use `Like` for fuzzy matching;
select * from root.sg.d1 where value like '%cc%';
select * from root.sg.device where value like '_b_';
-- Fuzzy matching operator: Use `Regexp` for fuzzy matching;
select * from root.sg.d1 where value regexp '^[A-Za-z]+$';
select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100;
select b, b like '1%', b regexp '[0-2]' from root.test;
-- `IS NULL` operator;
select code from root.sg1.d1 where temperature is null;
select code from root.sg1.d1 where temperature is not null;
-- `IN` operator;
select code from root.sg1.d1 where code in ('200', '300', '400', '500');
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');
select a, a in (1, 2) from root.test;6.3 逻辑运算符
更多见文档Logical Operators
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;7. 内置函数
7.1 Aggregate Functions
更多见文档Aggregate Functions
select count(status) from root.ln.wf01.wt01;
select count_if(s1=0 & s2=0, 3), count_if(s1=1 & s2=0, 3) from root.db.d1;
select count_if(s1=0 & s2=0, 3, 'ignoreNull'='false'), count_if(s1=1 & s2=0, 3, 'ignoreNull'='false') from root.db.d1;
select time_duration(s1) from root.db.d1;7.2 算数函数
更多见文档Arithmetic Operators and Functions
select s1, sin(s1), cos(s1), tan(s1) from root.sg1.d1 limit 5 offset 1000;
select s4,round(s4),round(s4,2),round(s4,-1) from root.sg1.d1;7.3 比较函数
更多见文档Comparison Operators and Functions
select ts, on_off(ts, 'threshold'='2') from root.test;
select ts, in_range(ts, 'lower'='2', 'upper'='3.1') from root.test;7.4 字符串处理函数
更多见文档String Processing
select s1, string_contains(s1, 's'='warn') from root.sg1.d4;
select s1, string_matches(s1, 'regex'='[^\\s]+37229') from root.sg1.d4;
select s1, length(s1) from root.sg1.d1;
select s1, locate(s1, "target"="1") from root.sg1.d1;
select s1, locate(s1, "target"="1", "reverse"="true") from root.sg1.d1;
select s1, startswith(s1, "target"="1") from root.sg1.d1;
select s1, endswith(s1, "target"="1") from root.sg1.d1;
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB") from root.sg1.d1;
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB", "series_behind"="true") from root.sg1.d1;
select s1, substring(s1 from 1 for 2) from root.sg1.d1;
select s1, replace(s1, 'es', 'tt') from root.sg1.d1;
select s1, upper(s1) from root.sg1.d1;
select s1, lower(s1) from root.sg1.d1;
select s3, trim(s3) from root.sg1.d1;
select s1, s2, strcmp(s1, s2) from root.sg1.d1;
select strreplace(s1, "target"=",", "replace"="/", "limit"="2") from root.test.d1;
select strreplace(s1, "target"=",", "replace"="/", "limit"="1", "offset"="1", "reverse"="true") from root.test.d1;
select regexmatch(s1, "regex"="\d+\.\d+\.\d+\.\d+", "group"="0") from root.test.d1;
select regexreplace(s1, "regex"="192\.168\.0\.(\d+)", "replace"="cluster-$1", "limit"="1") from root.test.d1;
select regexsplit(s1, "regex"=",", "index"="-1") from root.test.d1;
select regexsplit(s1, "regex"=",", "index"="3") from root.test.d1;7.5 数据类型转换函数
更多见文档Data Type Conversion Function
SELECT cast(s1 as INT32) from root.sg;7.6 常序列生成函数
更多见文档Constant Timeseries Generating Functions
select s1, s2, const(s1, 'value'='1024', 'type'='INT64'), pi(s2), e(s1, s2) from root.sg1.d1;7.7 选择函数
更多见文档Selector Functions
select s1, top_k(s1, 'k'='2'), bottom_k(s1, 'k'='2') from root.sg1.d2 where time > 2020-12-10T20:36:15.530+08:00;7.8 区间查询函数
更多见文档Continuous Interval Functions
select s1, zero_count(s1), non_zero_count(s2), zero_duration(s3), non_zero_duration(s4) from root.sg.d2;7.9 趋势计算函数
更多见文档Variation Trend Calculation Functions
select s1, time_difference(s1), difference(s1), non_negative_difference(s1), derivative(s1), non_negative_derivative(s1) from root.sg1.d1 limit 5 offset 1000;
SELECT DIFF(s1), DIFF(s2) from root.test;
SELECT DIFF(s1, 'ignoreNull'='false'), DIFF(s2, 'ignoreNull'='false') from root.test;7.10 采样函数
更多见文档Sample Functions。
select equal_size_bucket_random_sample(temperature,'proportion'='0.1') as random_sample from root.ln.wf01.wt01;
select equal_size_bucket_agg_sample(temperature, 'type'='avg','proportion'='0.1') as agg_avg, equal_size_bucket_agg_sample(temperature, 'type'='max','proportion'='0.1') as agg_max, equal_size_bucket_agg_sample(temperature,'type'='min','proportion'='0.1') as agg_min, equal_size_bucket_agg_sample(temperature, 'type'='sum','proportion'='0.1') as agg_sum, equal_size_bucket_agg_sample(temperature, 'type'='extreme','proportion'='0.1') as agg_extreme, equal_size_bucket_agg_sample(temperature, 'type'='variance','proportion'='0.1') as agg_variance from root.ln.wf01.wt01;
select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01;
select equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='avg', 'number'='2') as outlier_avg_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='stendis', 'number'='2') as outlier_stendis_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='cos', 'number'='2') as outlier_cos_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='prenextdis', 'number'='2') as outlier_prenextdis_sample from root.ln.wf01.wt01;
select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1;
select M4(s1,'windowSize'='10') from root.vehicle.d1;7.11 时间序列处理函数
更多见文档Time-Series
select change_points(s1), change_points(s2), change_points(s3), change_points(s4), change_points(s5), change_points(s6) from root.testChangePoints.d1;8. 数据质量函数库
更多见文档UDF-Libraries
8.1 数据质量
更多见文档Data-Quality
# Completeness;
select completeness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30;
select completeness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00;
# Consistency;
select consistency(s1) from root.test.d1 where time <= 2020-01-01 00:00:30;
select consistency(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00;
# Timeliness;
select timeliness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30;
select timeliness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00;
# Validity;
select Validity(s1) from root.test.d1 where time <= 2020-01-01 00:00:30;
select Validity(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00;
# Accuracy;
select Accuracy(t1,t2,t3,m1,m2,m3) from root.test;8.2 数据画像
更多见文档Data-Profiling
# ACF;
select acf(s1) from root.test.d1 where time <= 2020-01-01 00:00:05;
# Distinct;
select distinct(s2) from root.test.d2;
# Histogram;
select histogram(s1,"min"="1","max"="20","count"="10") from root.test.d1;
# Integral;
select integral(s1) from root.test.d1 where time <= 2020-01-01 00:00:10;
select integral(s1, "unit"="1m") from root.test.d1 where time <= 2020-01-01 00:00:10;
# IntegralAvg;
select integralavg(s1) from root.test.d1 where time <= 2020-01-01 00:00:10;
# Mad;
select mad(s0) from root.test;
select mad(s0, "error"="0.01") from root.test;
# Median;
select median(s0, "error"="0.01") from root.test;
# MinMax;
select minmax(s1) from root.test;
# Mode;
select mode(s2) from root.test.d2;
# MvAvg;
select mvavg(s1, "window"="3") from root.test;
# PACF;
select pacf(s1, "lag"="5") from root.test;
# Percentile;
select percentile(s0, "rank"="0.2", "error"="0.01") from root.test;
# Quantile;
select quantile(s0, "rank"="0.2", "K"="800") from root.test;
# Period;
select period(s1) from root.test.d3;
# QLB;
select QLB(s1) from root.test.d1;
# Resample;
select resample(s1,'every'='5m','interp'='linear') from root.test.d1;
select resample(s1,'every'='30m','aggr'='first') from root.test.d1;
select resample(s1,'every'='30m','start'='2021-03-06 15:00:00') from root.test.d1;
# Sample;
select sample(s1,'method'='reservoir','k'='5') from root.test.d1;
select sample(s1,'method'='isometric','k'='5') from root.test.d1;
# Segment;
select segment(s1, "error"="0.1") from root.test;
# Skew;
select skew(s1) from root.test.d1;
# Spline;
select spline(s1, "points"="151") from root.test;
# Spread;
select spread(s1) from root.test.d1 where time <= 2020-01-01 00:00:30;
# Stddev;
select stddev(s1) from root.test.d1;
# ZScore;
select zscore(s1) from root.test;8.3 异常检测
更多见文档Anomaly-Detection
# IQR;
select iqr(s1) from root.test;
# KSigma;
select ksigma(s1,"k"="1.0") from root.test.d1 where time <= 2020-01-01 00:00:30;
# LOF;
select lof(s1,s2) from root.test.d1 where time<1000;
select lof(s1, "method"="series") from root.test.d1 where time<1000;
# MissDetect;
select missdetect(s2,'minlen'='10') from root.test.d2;
# Range;
select range(s1,"lower_bound"="101.0","upper_bound"="125.0") from root.test.d1 where time <= 2020-01-01 00:00:30;
# TwoSidedFilter;
select TwoSidedFilter(s0, 'len'='5', 'threshold'='0.3') from root.test;
# Outlier;
select outlier(s1,"r"="5.0","k"="4","w"="10","s"="5") from root.test;
# MasterTrain;
select MasterTrain(lo,la,m_lo,m_la,'p'='3','eta'='1.0') from root.test;
# MasterDetect;
select MasterDetect(lo,la,m_lo,m_la,model,'output_type'='repair','p'='3','k'='3','eta'='1.0') from root.test;
select MasterDetect(lo,la,m_lo,m_la,model,'output_type'='anomaly','p'='3','k'='3','eta'='1.0') from root.test;8.4 频域分析
更多见文档Frequency-Domain
# Conv;
select conv(s1,s2) from root.test.d2;
# Deconv;
select deconv(s3,s2) from root.test.d2;
select deconv(s3,s2,'result'='remainder') from root.test.d2;
# DWT;
select dwt(s1,"method"="haar") from root.test.d1;
# FFT;
select fft(s1) from root.test.d1;
select fft(s1, 'result'='real', 'compress'='0.99'), fft(s1, 'result'='imag','compress'='0.99') from root.test.d1;
# HighPass;
select highpass(s1,'wpass'='0.45') from root.test.d1;
# IFFT;
select ifft(re, im, 'interval'='1m', 'start'='2021-01-01 00:00:00') from root.test.d1;
# LowPass;
select lowpass(s1,'wpass'='0.45') from root.test.d1;
# Envelope;
select envelope(s1) from root.test.d1;8.5 数据匹配
更多见文档Data-Matching
# Cov;
select cov(s1,s2) from root.test.d2;
# DTW;
select dtw(s1,s2) from root.test.d2;
# Pearson;
select pearson(s1,s2) from root.test.d2;
# PtnSym;
select ptnsym(s4, 'window'='5', 'threshold'='0') from root.test.d1;
# XCorr;
select xcorr(s1, s2) from root.test.d1 where time <= 2020-01-01 00:00:05;8.6 数据修复
更多见文档Data-Repairing
# TimestampRepair;
select timestamprepair(s1,'interval'='10000') from root.test.d2;
select timestamprepair(s1) from root.test.d2;
# ValueFill;
select valuefill(s1) from root.test.d2;
select valuefill(s1,"method"="previous") from root.test.d2;
# ValueRepair;
select valuerepair(s1) from root.test.d2;
select valuerepair(s1,'method'='LsGreedy') from root.test.d2;
# MasterRepair;
select MasterRepair(t1,t2,t3,m1,m2,m3) from root.test;
# SeasonalRepair;
select seasonalrepair(s1,'period'=3,'k'=2) from root.test.d2;
select seasonalrepair(s1,'method'='improved','period'=3) from root.test.d2;8.7 序列发现
更多见文档Series-Discovery
# ConsecutiveSequences;
select consecutivesequences(s1,s2,'gap'='5m') from root.test.d1;
select consecutivesequences(s1,s2) from root.test.d1;
# ConsecutiveWindows;
select consecutivewindows(s1,s2,'length'='10m') from root.test.d1;8.8 机器学习
更多见文档Machine-Learning
# AR;
select ar(s0,"p"="2") from root.test.d0;
# Representation;
select representation(s0,"tb"="3","vb"="2") from root.test.d0;
# RM;
select rm(s0, s1,"tb"="3","vb"="2") from root.test.d0;9. 条件表达式
select T, P, case
when 1000<T and T<1050 and 1000000<P and P<1100000 then "good!"
when T<=1000 or T>=1050 then "bad temperature"
when P<=1000000 or P>=1100000 then "bad pressure"
end as `result`
from root.test1;
select str, case
when str like "%cc%" then "has cc"
when str like "%dd%" then "has dd"
else "no cc and dd" end as `result`
from root.test2;
select
count(case when x<=1 then 1 end) as `(-∞,1]`,
count(case when 1<x and x<=3 then 1 end) as `(1,3]`,
count(case when 3<x and x<=7 then 1 end) as `(3,7]`,
count(case when 7<x then 1 end) as `(7,+∞)`
from root.test3;
select x, case x when 1 then "one" when 2 then "two" else "other" end from root.test4;
select x, case x when 1 then true when 2 then false end as `result` from root.test4;
select x, case x
when 1 then 1
when 2 then 222222222222222
when 3 then 3.3
when 4 then 4.4444444444444
end as `result`
from root.test4;10. 触发器
10.1 使用 SQL 语句注册该触发器
// Create Trigger
createTrigger
: CREATE triggerType TRIGGER triggerName=identifier triggerEventClause ON pathPattern AS className=STRING_LITERAL uriClause? triggerAttributeClause?
;
triggerType
: STATELESS | STATEFUL
;
triggerEventClause
: (BEFORE | AFTER) INSERT
;
uriClause
: USING URI uri
;
uri
: STRING_LITERAL
;
triggerAttributeClause
: WITH LR_BRACKET triggerAttribute (COMMA triggerAttribute)* RR_BRACKET
;
triggerAttribute
: key=attributeKey operator_eq value=attributeValue
;SQL 语句示例
CREATE STATELESS TRIGGER triggerTest
BEFORE INSERT
ON root.sg.**
AS 'org.apache.iotdb.trigger.ClusterAlertingExample'
USING URI 'http://jar/ClusterAlertingExample.jar'
WITH (
"name" = "trigger",
"limit" = "100"
);10.2 卸载触发器
卸载触发器的 SQL 语法如下:
// Drop Trigger
dropTrigger
: DROP TRIGGER triggerName=identifier
;示例语句
DROP TRIGGER triggerTest1;10.3 查询触发器
SHOW TRIGGERS;11. 连续查询(Continuous Query, CQ)
11.1 语法
CREATE (CONTINUOUS QUERY | CQ) <cq_id>
[RESAMPLE
[EVERY <every_interval>]
[BOUNDARY <execution_boundary_time>]
[RANGE <start_time_offset>[, end_time_offset]]
]
[TIMEOUT POLICY BLOCKED|DISCARD]
BEGIN
SELECT CLAUSE
INTO CLAUSE
FROM CLAUSE
[WHERE CLAUSE]
[GROUP BY(<group_by_interval>[, <sliding_step>]) [, level = <level>]]
[HAVING CLAUSE]
[FILL ({PREVIOUS | LINEAR | constant} (, interval=DURATION_LITERAL)?)]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
END配置连续查询执行的周期性间隔
CREATE CONTINUOUS QUERY cq1
RESAMPLE EVERY 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
END;
SELECT temperature_max from root.ln.*.*;配置连续查询的时间窗口大小
CREATE CONTINUOUS QUERY cq2
RESAMPLE RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
END;
SELECT temperature_max from root.ln.*.*;同时配置连续查询执行的周期性间隔和时间窗口大小
CREATE CONTINUOUS QUERY cq3
RESAMPLE EVERY 20s RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
END;
SELECT temperature_max from root.ln.*.*;配置连续查询每次查询执行时间窗口的结束时间
CREATE CONTINUOUS QUERY cq4
RESAMPLE EVERY 20s RANGE 40s, 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
END;
SELECT temperature_max from root.ln.*.*;没有GROUP BY TIME子句的连续查询
CREATE CONTINUOUS QUERY cq5
RESAMPLE EVERY 20s
BEGIN
SELECT temperature + 1
INTO root.precalculated_sg.::(temperature)
FROM root.ln.*.*
align by device
END;
SELECT temperature from root.precalculated_sg.*.* align by device;11.2 连续查询的管理
查询系统已有的连续查询
展示集群中所有的已注册的连续查询
SHOW (CONTINUOUS QUERIES | CQS)SHOW CONTINUOUS QUERIES;删除已有的连续查询
删除指定的名为cq_id的连续查询:
DROP (CONTINUOUS QUERY | CQ) <cq_id>DROP CONTINUOUS QUERY s1_count_cq;作为子查询的替代品
- 创建一个连续查询
CREATE CQ s1_count_cq
BEGIN
SELECT count(s1)
INTO root.sg_count.d.count_s1
FROM root.sg.d
GROUP BY(30m)
END;- 查询连续查询的结果
SELECT avg(count_s1) from root.sg_count.d;12. 用户自定义函数
12.1 UDFParameters
SELECT UDF(s1, s2, 'key1'='iotdb', 'key2'='123.45') FROM root.sg.d;12.2 UDF 注册
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME> (USING URI URI-STRING)?不指定URI
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample';指定URI
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample' USING URI 'http://jar/example.jar';12.3 UDF 卸载
DROP FUNCTION <UDF-NAME>DROP FUNCTION example;12.4 UDF 查询
带自定义输入参数的查询
SELECT example(s1, 'key1'='value1', 'key2'='value2'), example(*, 'key3'='value3') FROM root.sg.d1;SELECT example(s1, s2, 'key1'='value1', 'key2'='value2') FROM root.sg.d1;与其他查询的嵌套查询
SELECT s1, s2, example(s1, s2) FROM root.sg.d1;
SELECT *, example(*) FROM root.sg.d1 DISABLE ALIGN;
SELECT s1 * example(* / s1 + s2) FROM root.sg.d1;
SELECT s1, s2, s1 + example(s1, s2), s1 - example(s1 + example(s1, s2) / s2) FROM root.sg.d1;12.5 查看所有注册的 UDF
SHOW FUNCTIONS;13. 权限管理
13.1 用户与角色相关
- 创建用户(需 MANAGE_USER 权限)
CREATE USER <userName> <password>;
eg: CREATE USER user1 'passwd';- 删除用户 (需 MANEGE_USER 权限)
DROP USER <userName>;
eg: DROP USER user1;- 创建角色 (需 MANAGE_ROLE 权限)
CREATE ROLE <roleName>;
eg: CREATE ROLE role1;- 删除角色 (需 MANAGE_ROLE 权限)
DROP ROLE <roleName>;
eg: DROP ROLE role1;- 赋予用户角色 (需 MANAGE_ROLE 权限)
GRANT ROLE <ROLENAME> TO <USERNAME>;
eg: GRANT ROLE admin TO user1;- 移除用户角色 (需 MANAGE_ROLE 权限)
REVOKE ROLE <ROLENAME> FROM <USER>;
eg: REVOKE ROLE admin FROM user1;- 列出所有用户 (需 MANEGE_USER 权限)
LIST USER;- 列出所有角色 (需 MANAGE_ROLE 权限)
LIST ROLE;- 列出指定角色下所有用户 (需 MANEGE_USER 权限)
LIST USER OF ROLE <roleName>;
eg: LIST USER OF ROLE roleuser;- 列出指定用户下所有角色
用户可以列出自己的角色,但列出其他用户的角色需要拥有 MANAGE_ROLE 权限。
LIST ROLE OF USER <username>;
eg: LIST ROLE OF USER tempuser;- 列出用户所有权限
用户可以列出自己的权限信息,但列出其他用户的权限需要拥有 MANAGE_USER 权限。
LIST PRIVILEGES OF USER <username>;
eg: LIST PRIVILEGES OF USER tempuser;- 列出角色所有权限
用户可以列出自己具有的角色的权限信息,列出其他角色的权限需要有 MANAGE_ROLE 权限。
LIST PRIVILEGES OF ROLE <roleName>;
eg: LIST PRIVILEGES OF ROLE actor;- 修改密码
用户可以修改自己的密码,但修改其他用户密码需要具备MANAGE_USER 权限。
ALTER USER <username> SET PASSWORD <password>;
eg: ALTER USER tempuser SET PASSWORD 'newpwd';13.2 授权与取消授权
用户使用授权语句对赋予其他用户权限,语法如下:
GRANT <PRIVILEGES> ON <PATHS> TO ROLE/USER <NAME> [WITH GRANT OPTION];
eg: GRANT READ ON root.** TO ROLE role1;
eg: GRANT READ_DATA, WRITE_DATA ON root.t1.** TO USER user1;
eg: GRANT READ_DATA, WRITE_DATA ON root.t1.**,root.t2.** TO USER user1;
eg: GRANT MANAGE_ROLE ON root.** TO USER user1 WITH GRANT OPTION;
eg: GRANT ALL ON root.** TO USER user1 WITH GRANT OPTION;用户使用取消授权语句可以将其他的权限取消,语法如下:
REVOKE <PRIVILEGES> ON <PATHS> FROM ROLE/USER <NAME>;
eg: REVOKE READ ON root.** FROM ROLE role1;
eg: REVOKE READ_DATA, WRITE_DATA ON root.t1.** FROM USER user1;
eg: REVOKE READ_DATA, WRITE_DATA ON root.t1.**, root.t2.** FROM USER user1;
eg: REVOKE MANAGE_ROLE ON root.** FROM USER user1;
eg: REVOKE ALL ON root.** FROM USER user1;