应用场景
应用场景
1. 能源电力
1.1 背景
通过对电力生产、传输、存储和消费过程中的海量时序数据进行采集、存储、分析以及对电力系统的实时监控、精准预测和智能调度,企业可以有效提升能源利用效率,降低运营成本,确保能源生产的安全性和可持续性,保障电网的安全稳定运行。
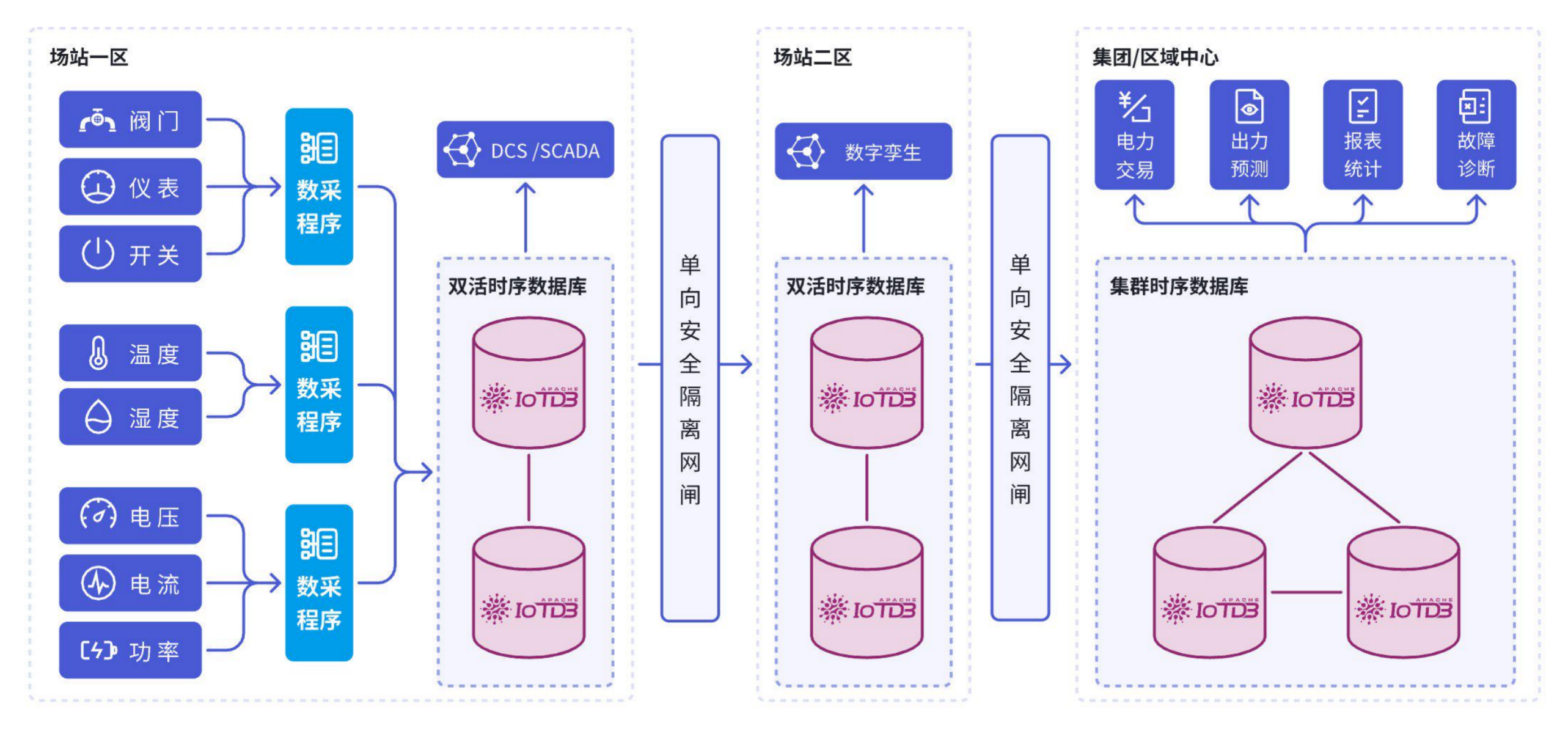
1.2 架构
IoTDB 凭借集群高可用、低流量数据同步、跨网闸支持和优异的性能为企业提供国产化自主可控的时序数据管理解决方案,支撑企业应对大规模时序数据管理挑战,推动传统能源和可再生能源的高效管理与整合。
2. 航空航天
2.1 背景
近年来,随着科技的不断进步,航空航天领域正进一步加快数字化与智能化建设。先进的数据采集和处理技术逐渐成为提升飞行安全、优化系统性能的重要手段。通过对飞机、火箭、卫星等设备在设计、制造、试飞、运行等全流程中产生的海量时序数据进行高效管理,企业能实现对飞行任务中关键系统的精准监测与分析,通过遥测数据实时回传、试飞数据快速导入,实现航空信息的监测和设计改进,确保飞行任务的安全可靠执行。
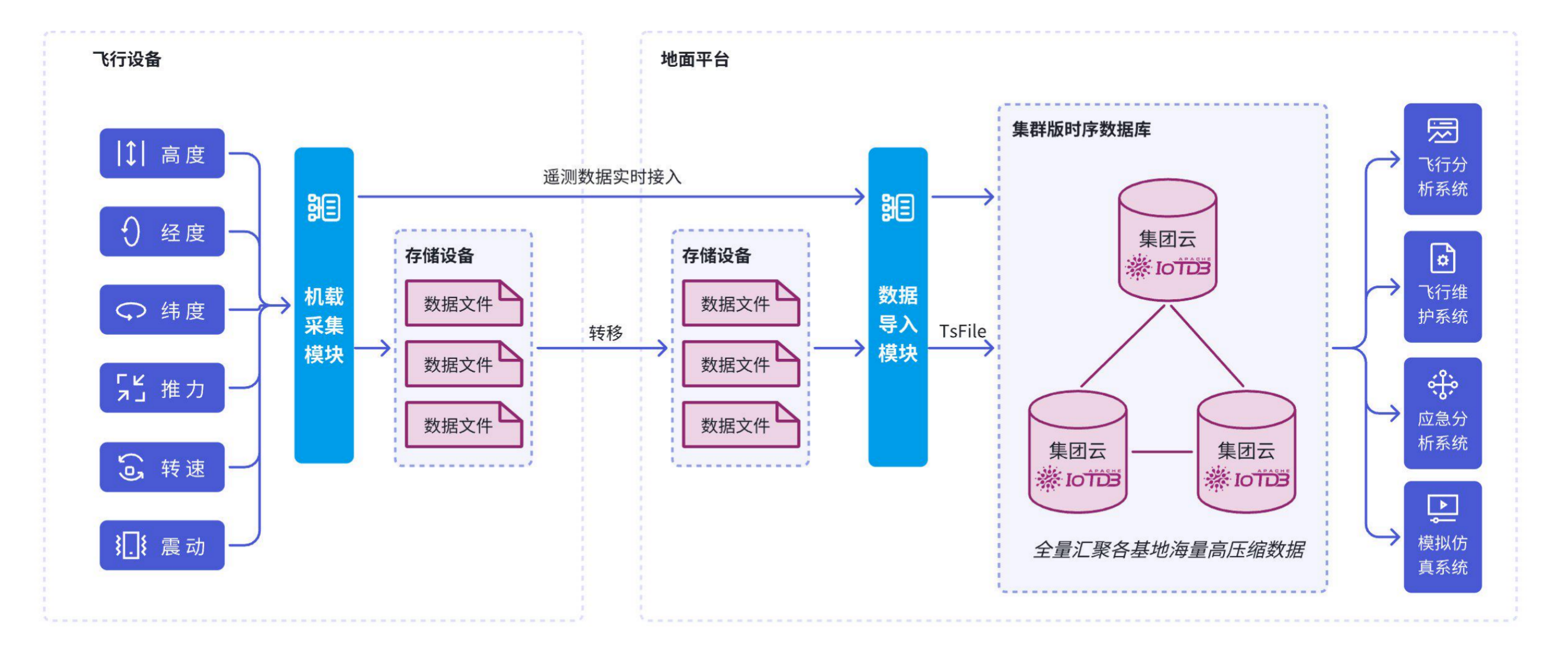
2.2 架构
IoTDB 凭借其国产自研的高效低流量数据同步、离线数据迁移、丰富的部署选择和低资源占用等特点,为行业的数据管理和业务扩展提供了数据基础,为航空航天领域的技术创新和持续发展提供有力支撑。
3. 交通运输
3.1 背景
交通运输行业的快速发展带来了对多样化交通数据管理的需求,尤其在铁路、地铁等关键枢纽中,数据的实时性、可靠性和精准性至关重要。通过对列车、地铁、船舶、汽车等设备的运行、状态、位置信息等多维数据进行实时采集、存储与分析,企业可实现智能调度、故障预警、线路优化和高效运维。企业不仅可以提升交通系统的运转效率,还降低了运营管理成本。
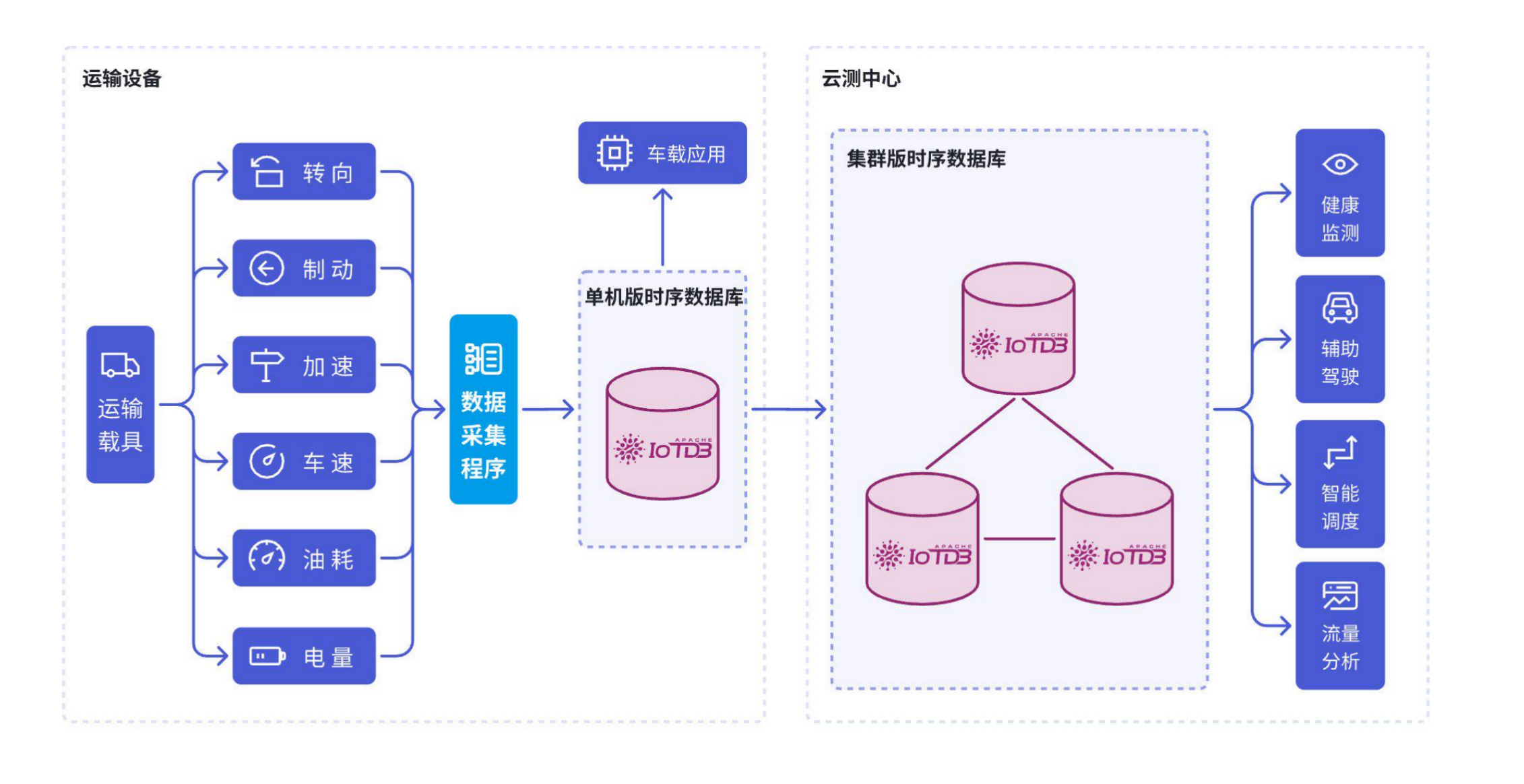
3.2 架构
IoTDB 凭借其高效的时序数据管理和低延迟查询能力,有效应对交通运输行业中的数据爆发式增长,实现多源异构数据高效流转和管理,为铁路、船舶等构建起稳定可靠的智能交通系统管理基础,为行业向智能化和自动化方向发展提供了重要支撑。
4. 钢铁冶炼
4.1 背景
作为传统制造业的典型代表,钢铁冶炼行业近年来逐步推进数字化转型和智能化改造,以应对日益增长的市场竞争和环保、安全等要求。特别是工业物联网平台的部署,已成为钢铁冶炼企业在生产环节中提升产能、优化产品质量、降低能耗的关键手段。通过工业物联网平台,企业能够对冶炼设备和生产线进行实时数据采集、存储和分析,从而实现对核心生产环节的智能监测、精准控制与高效管理。
4.2 架构
IoTDB 通过其强大的数据存储与计算能力,为钢铁冶炼场景提供跨平台支持、低资源占用的灵活部署方案,丰富的外部接口也使其可以与其他系统高效集成,助力钢铁冶炼行业构建智慧工厂,进一步支撑传统工业加快形成新质生产力。
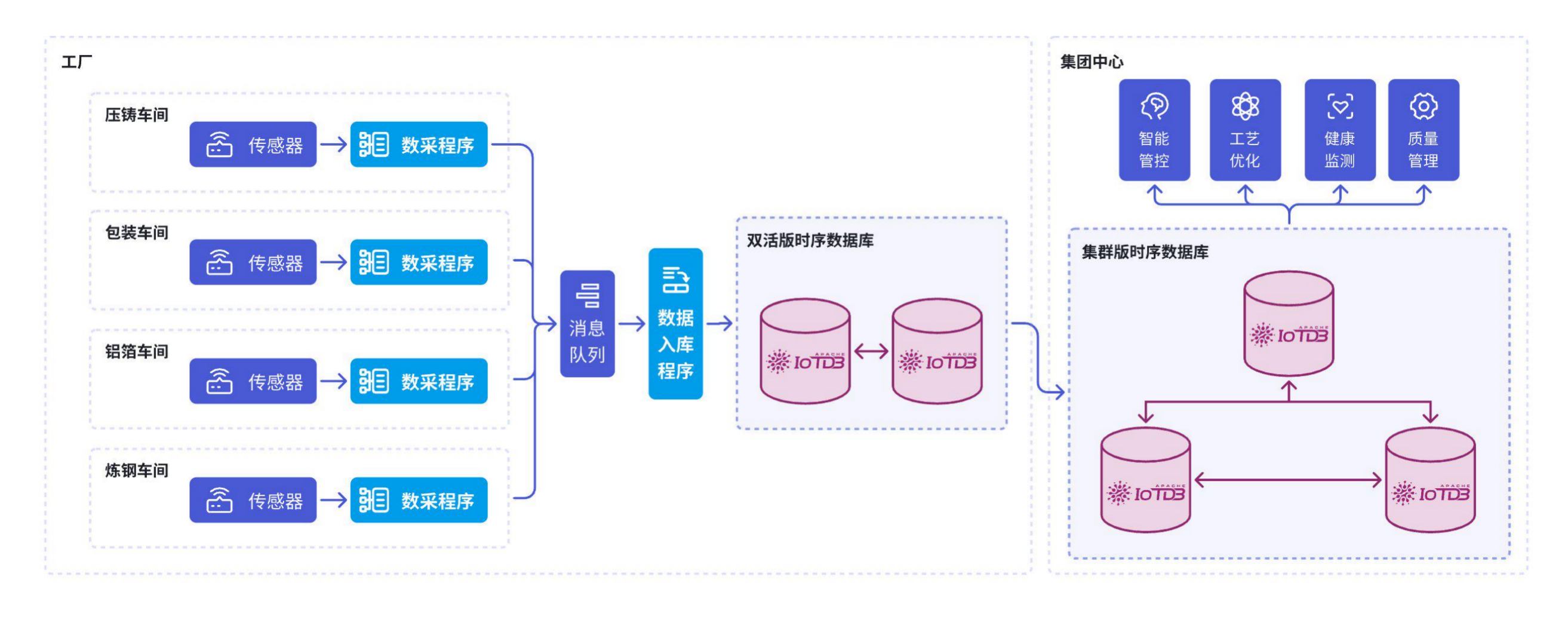
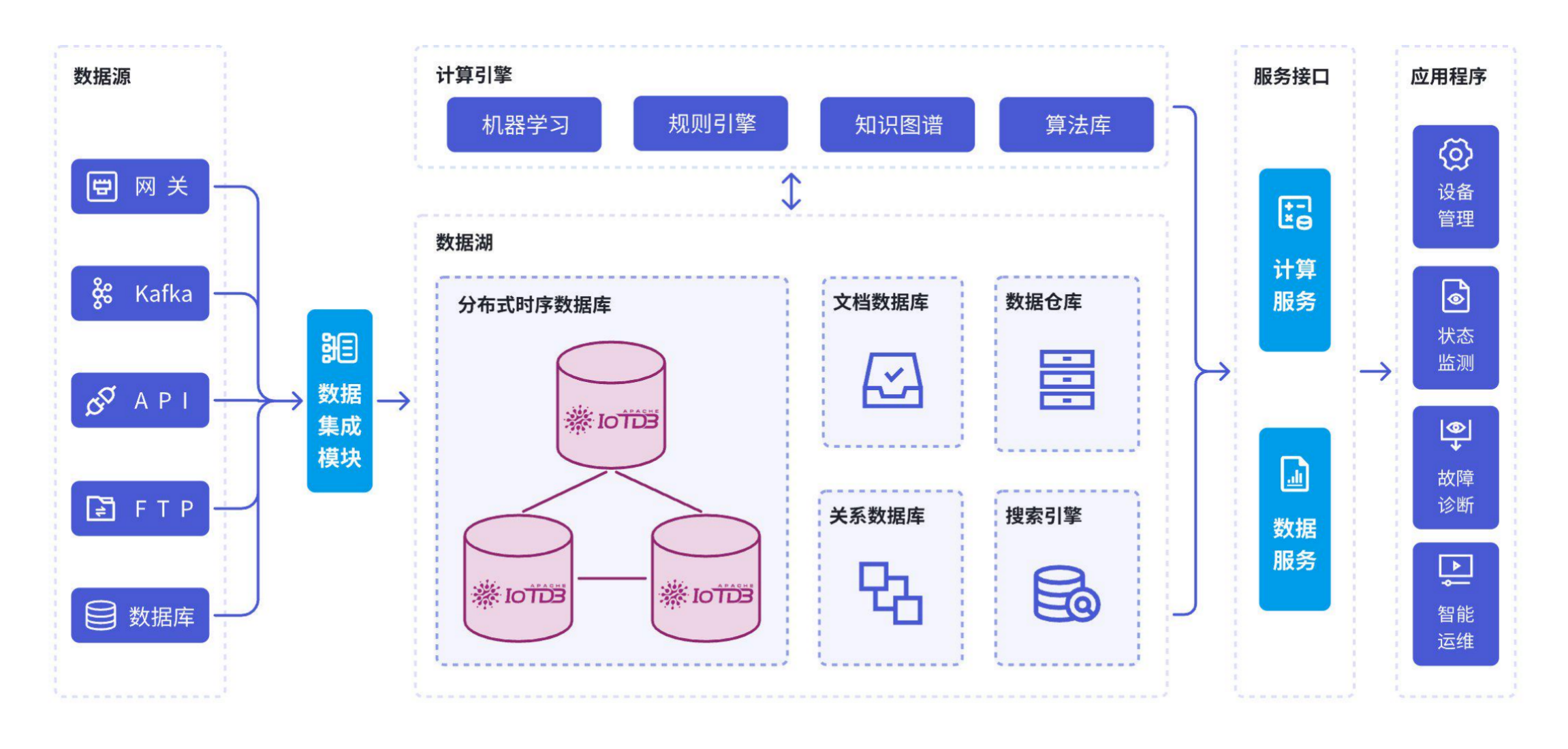
5. 物联网
5.1 背景
物联网(IoT)正在从根本上改变各个行业的运行方式,通过连接海量设备和深度数据分析实现智能化管理。随着物联网设备接入规模的不断扩大,对数据管理系统的处理、存储和分析能力提出了更高要求。企业需要高效管理来自边缘设备和云端的数据流,保证系统的实时性、稳定性和可扩展性,以支持设备状态监测、故障诊断、预测性维护等核心业务应用。
5.2 架构
作为物联网原生的高性能时序数据库,IoTDB 支持从边缘设备到云端的全链路数据同步和存储分析,具备高并发处理能力,能够满足大规模设备接入的需求。IoTDB为企业提供灵活的数据解决方案,助力发掘设备运行数据中的深层次价值,提升运营效率,推动企业物联网业务的全面发展。