数据同步
数据同步
数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
1. 功能概述
1.1 数据同步
一个数据同步任务包含 3 个阶段:
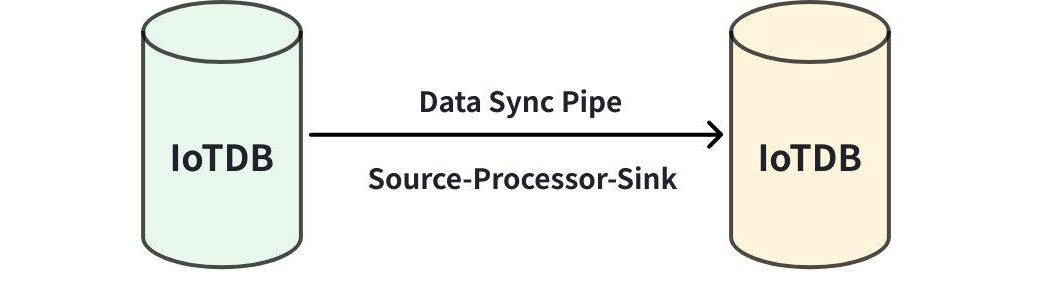
- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
- 处理(Process)阶段:该部分用于处理从源 IoTDB 抽取出的数据,在 SQL 语句中的 processor 部分定义
- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
通过 SQL 语句声明式地配置 3 个部分的具体内容,可实现灵活的数据同步能力。目前数据同步支持以下信息的同步,您可以在创建同步任务时对同步范围进行选择(默认选择 data.insert,即同步新写入的数据):
| 同步范围 | 同步内容 | 说明 |
|---|---|---|
| all | 所有范围 | |
| data(数据) | insert(增量) | 同步新写入的数据 |
| delete(删除) | 同步被删除的数据 | |
| schema(元数据) | database(数据库) | 同步数据库的创建、修改或删除操作 |
| table(表) | 同步表的创建、修改或删除操作 | |
| TTL(数据到期时间) | 同步数据的存活时间 | |
| auth(权限) | - | 同步用户权限和访问控制 |
1.2 功能限制及说明
- 不支持 1.x 系列版本 IoTDB 与 2.x 以及以上系列版本的 IoTDB 之间进行数据同步。
- 在进行数据同步任务时,请避免执行任何删除操作,防止两端状态不一致。
- 树模型与表模型的
pipe及pipe plugins在设计上相互隔离,建议在创建pipe前先通过show命令查询当前-sql_dialect参数配置下可用的内置插件,以确保语法兼容性和功能支持。 - 当 Pipe 向接收端写入数据因字段类型不匹配而失败时,IoTDB 可按照目标端已有 schema 的字段类型对数据进行转换,并重试写入,以提高同步成功率。该能力由
sink.exception.data.convert-on-type-mismatch控制,参数说明见后文 sink 参数表。
类型不匹配时的转换规则如下:
| 源类型 | 目标类型 | 转换规则 |
|---|---|---|
| 数值类型 | 数值类型 | 按目标数值类型进行转换,可能发生截断、精度损失或溢出。 |
| 数值类型 | BOOLEAN | 0转换为false,非0转换为true。 |
| BOOLEAN | 数值类型 | true转换为1,false转换为0。 |
| TEXT、STRING、BLOB | BOOLEAN | 按字符串解析为 BOOLEAN。 |
| TEXT、STRING、BLOB | 数值类型 | 按字符串解析为目标数值类型;解析失败时写入默认值0、0L或0.0。 |
| TEXT、STRING、BLOB | TIMESTAMP | 按字符串解析为 TIMESTAMP;解析失败时写入默认值0L。 |
| TEXT、STRING、BLOB | DATE | 按字符串解析为 DATE;解析失败时写入默认日期1970-01-01。 |
| 非法数值 | DATE | 若无法转换为合法 DATE,则写入默认日期1970-01-01。 |
| DATE | TIMESTAMP | 按 UTC 转换为当天零点对应的时间戳。 |
| TIMESTAMP | DATE | 按 UTC 转换为对应日期。 |
注意:自动转换基于目标端已有 schema 执行,不会自动修改目标端 schema;该能力优先保证同步继续进行,可能导致精度损失或默认值写入。
2. 使用说明
数据同步任务有三种状态:RUNNING、STOPPED 和 DROPPED。任务状态转换如下图所示:
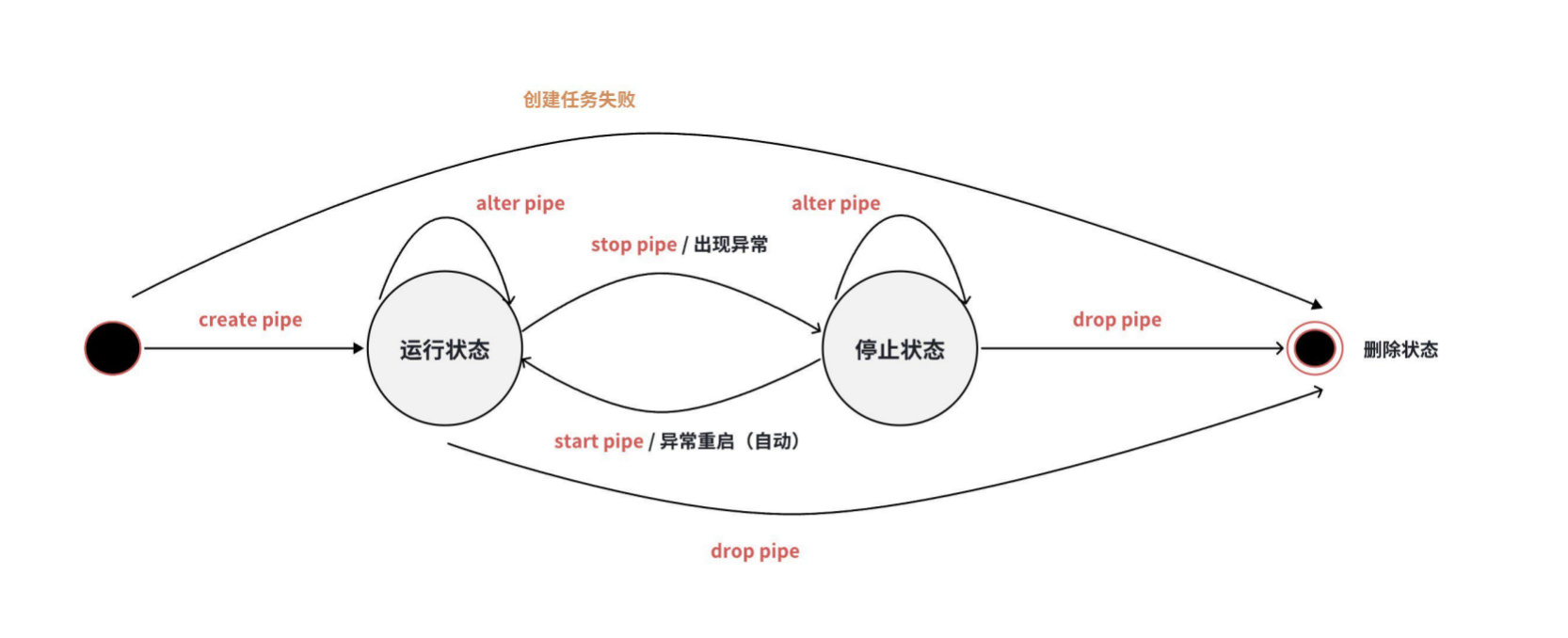
创建后任务会直接启动,同时当任务发生异常停止后,系统会自动尝试重启任务。
提供以下 SQL 语句对同步任务进行状态管理。
2.1 创建任务
使用 CREATE PIPE 语句来创建一条数据同步任务,下列属性中PipeId和sink必填,source和processor为选填项,输入 SQL 时注意 SOURCE与 SINK 插件顺序不能替换。
SQL 示例如下:
CREATE PIPE [IF NOT EXISTS] <PipeId> -- PipeId 是能够唯一标定任务的名字
-- 数据抽取插件,可选插件
WITH SOURCE (
[<parameter> = <value>,],
)
-- 数据处理插件,可选插件
WITH PROCESSOR (
[<parameter> = <value>,],
)
-- 数据连接插件,必填插件
WITH SINK (
[<parameter> = <value>,],
)IF NOT EXISTS 语义:用于创建操作中,确保当指定 Pipe 不存在时,执行创建命令,防止因尝试创建已存在的 Pipe 而导致报错。
注意:V2.0.8 起,创建一个全量数据同步 Pipe (例如 Pipeid : alldatapipe)时,系统会自动将其拆分为两个独立的 Pipe:
历史 Pipe:PipeId 为原名称加 _history后缀(如
alldatapipe_history),source 参数默认携带'realtime.enable'='false', 'inclusion'='data.insert', 'inclusion.exclusion'=''实时 Pipe:PipeId 为原名称加 _realtime后缀(如
alldatapipe_realtime),source 参数默认携带'history.enable'='false',若配置了元数据同步,则由实时 Pipe 负责发送
创建成功后,原 PipeId(如 alldatapipe)将不再作为有效标识符。在进行启动、停止、删除、查看等任务操作时,必须使用拆分后的独立 PipeId(即 *_history或 *_realtime)。操作示例见查看任务小节
2.2 开始任务
创建之后,任务直接进入运行状态,不需要执行启动任务。当使用STOP PIPE语句停止任务时需手动使用START PIPE语句来启动任务,PIPE 发生异常情况停止后会自动重新启动任务,从而开始处理数据:
START PIPE<PipeId>2.3 停止任务
停止处理数据:
STOP PIPE <PipeId>2.4 删除任务
删除指定任务:
DROP PIPE [IF EXISTS] <PipeId>IF EXISTS 语义:用于删除操作中,确保当指定 Pipe 存在时,执行删除命令,防止因尝试删除不存在的 Pipe 而导致报错。
删除任务不需要先停止同步任务。
2.5 查看任务
查看全部任务:
SHOW PIPES查看指定任务:
SHOW PIPE <PipeId>pipe 的 show pipes 结果示例:
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+其中各列含义如下:
- ID:同步任务的唯一标识符
- CreationTime:同步任务的创建的时间
- State:同步任务的状态
- PipeSource:同步数据流的来源
- PipeProcessor:同步数据流在传输过程中的处理逻辑
- PipeSink:同步数据流的目的地
- ExceptionMessage:显示同步任务的异常信息
- RemainingEventCount(统计存在延迟):剩余 event 数,当前数据同步任务中的所有 event 总数,包括数据同步的 event,以及系统和用户自定义的 event。
- EstimatedRemainingSeconds(统计存在延迟):剩余时间,基于当前 event 个数和 pipe 处速率,预估完成传输的剩余时间。
示例:
在 V2.0.8 及之后的版本中,创建一个全量数据同步任务,并查看该任务详情
IoTDB> create pipe alldatapipe with source('inclusion'='all','exclusion'='auth') with sink('node-urls'='127.0.0.1:6668')
IoTDB> show pipe alldatapipe_history
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State| PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
|alldatapipe_history|2025-12-18T15:06:16.697|RUNNING|{exclusion=auth, history.enable=true, inclusion=data.insert, inclusion.exclusion=, realtime.enable=false}| {}|{node-urls=127.0.0.1:6668}| | 0| 0.00|
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
IoTDB> show pipe alldatapipe_realtime
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State| PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
|alldatapipe_realtime|2025-12-18T15:06:16.312|RUNNING|{exclusion=auth, history.enable=false, inclusion=all, realtime.enable=true}| {}|{node-urls=127.0.0.1:6668}| | 0| 0.00|
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+2.6 修改任务
ALTER PIPE 语句用于动态更新已存在的 PIPE,支持修改或替换 source、processor 及 sink 的配置。
ALTER PIPE [IF EXISTS] <PipeId>
MODIFY/REPLACE SOURCE(...)
MODIFY/REPLACE PROCESSOR(...)
MODIFY/REPLACE SINK(...)说明:
- 执行操作不会改变 PIPE 的运行状态,等价于保留原 PipeId 的处理进度,在原进度位置创建新 PIPE。
- source/processor/sink 的 modify/replace 参数均为非必填;若未指定任何修改参数,等价于删除当前 PIPE 后,按原配置和进度重新创建。
- 对于指定 modify 的插件,保留该插件其他参数,仅替换或新增给定的参数。
- 对于指定 replace 的插件,直接替换该插件所有参数。
- 当使用 [IF EXISTS] 关键字时,即使不存在同名的 Pipe 也会返回执行成功,但是实际未执行任何操作。
示例:
ALTER PIPE A2B REPLACE SINK ('sink'='iotdb-thrift-sink', 'node-urls' = '127.0.0.1:6668');2.7 同步插件
为了使得整体架构更加灵活以匹配不同的同步场景需求,我们支持在同步任务框架中进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 processor 插件 和 Sink 插件,并加载至 IoTDB 系统进行使用。查看系统中的插件(含自定义与内置插件)可以用以下语句:
SHOW PIPEPLUGINS返回结果如下:
IoTDB> SHOW PIPEPLUGINS
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| PluginName|PluginType| ClassName| PluginJar|
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+预置插件详细介绍如下(各插件的详细参数可参考本文参数说明):
| 类型 | 自定义插件 | 插件名称 | 介绍 |
|---|---|---|---|
| source 插件 | 不支持 | iotdb-source | 默认的 extractor 插件,用于抽取 IoTDB 历史或实时数据 |
| processor 插件 | 支持 | do-nothing-processor | 默认的 processor 插件,不对传入的数据做任何的处理 |
| sink 插件 | 支持 | do-nothing-sink | 不对发送出的数据做任何的处理 |
| iotdb-thrift-sink | 默认的 sink 插件,用于 IoTDB 到 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 | ||
| iotdb-thrift-ssl-sink | 用于 IoTDB 与 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 sync blocking IO 模型,适用于安全需求较高的场景 |
3. 使用示例
3.1 全量数据同步
本例子用来演示将一个 IoTDB 的所有数据同步至另一个 IoTDB,数据链路如下图所示:
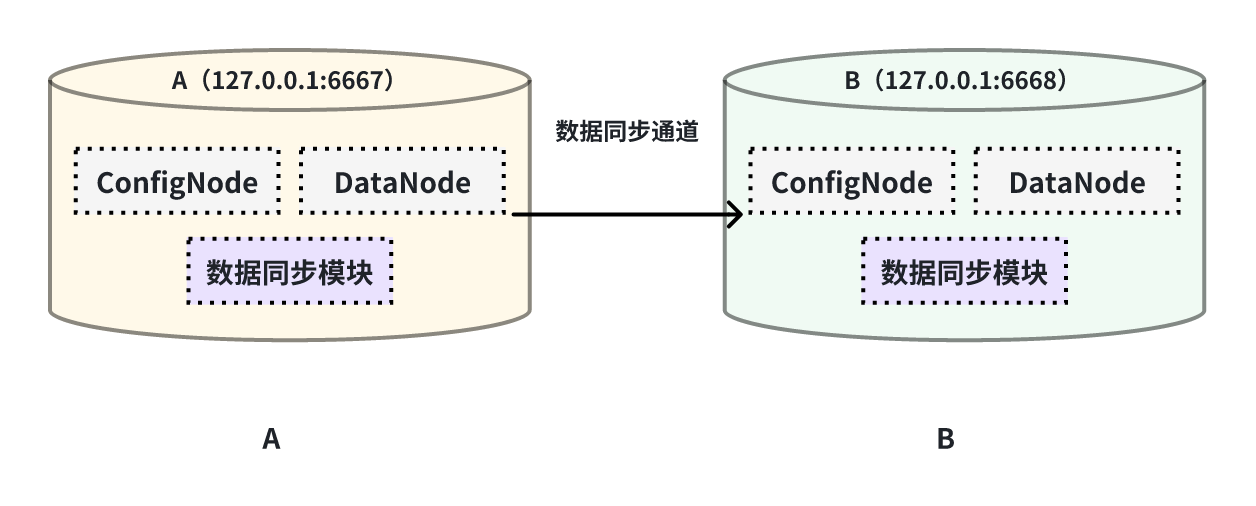
在这个例子中,我们可以创建一个名为 A2B 的同步任务,用来同步 A IoTDB 到 B IoTDB 间的全量数据,这里需要用到用到 sink 的 iotdb-thrift-sink 插件(内置插件),需通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url,如下面的示例语句:
create pipe A2B
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)3.2 部分数据同步
本例子用来演示同步某个历史时间范围( 2023 年 8 月 23 日 8 点到 2023 年 10 月 23 日 8 点)的数据至另一个 IoTDB,数据链路如下图所示:
在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),需要配置数据的起止时间 start-time 和 end-time 以及传输的模式 mode.streaming。通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url。
详细语句如下:
create pipe A2B
WITH SOURCE (
'source'= 'iotdb-source',
'mode.streaming' = 'true' -- 新插入数据(pipe创建后)的抽取模式:是否按流式抽取(false 时为批式)
'database-name'='testdb.*', -- 同步数据的范围
'start-time' = '2023.08.23T08:00:00+00:00', -- 同步所有数据的开始 event time,包含 start-time
'end-time' = '2023.10.23T08:00:00+00:00' -- 同步所有数据的结束 event time,包含 end-time
)
with SINK (
'sink'='iotdb-thrift-async-sink',
'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)3.3 边云数据传输
本例子用来演示多个 IoTDB 之间边云传输数据的场景,数据由 B 、C、D 集群分别都同步至 A 集群,数据链路如下图所示:
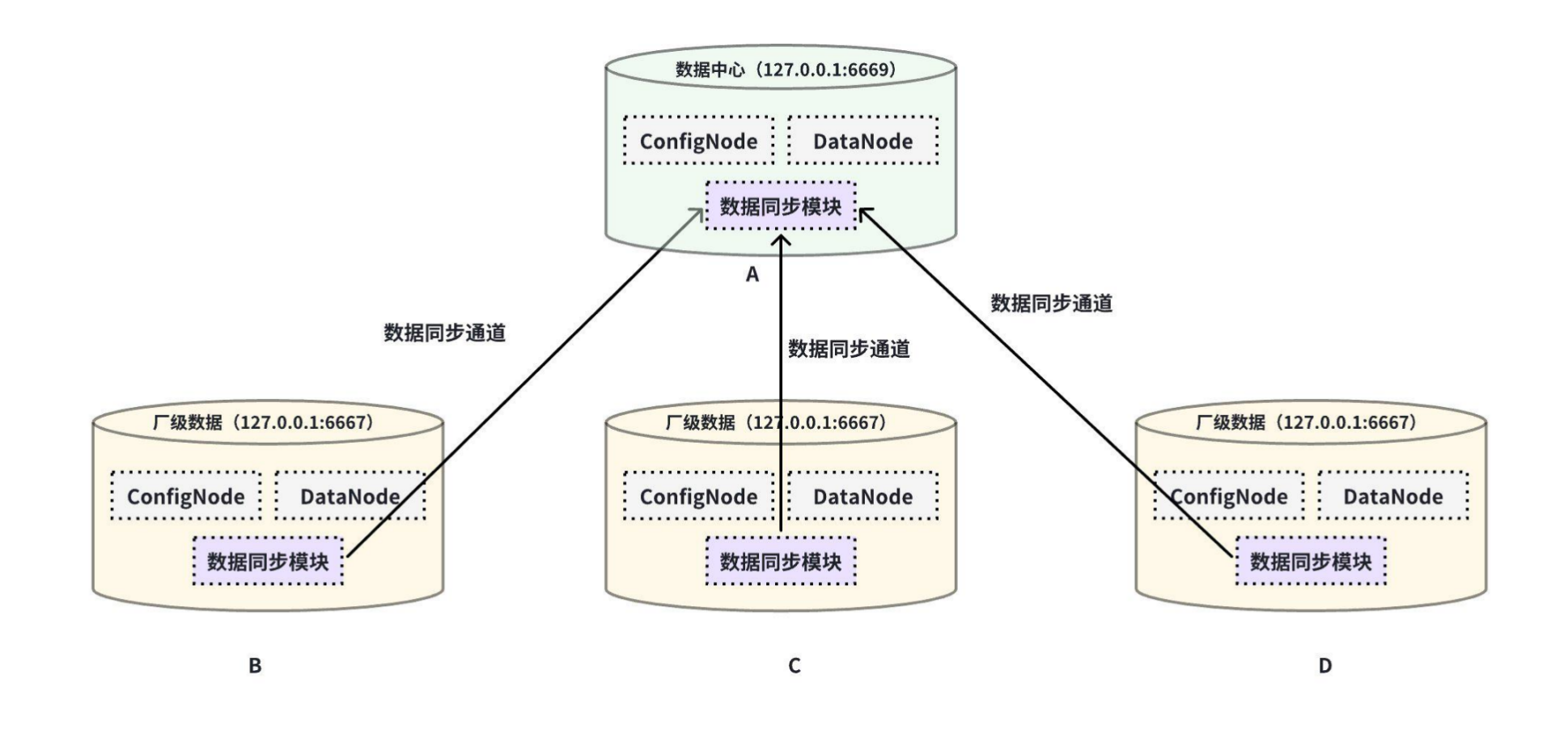
在这个例子中,为了将 B 、C、D 集群的数据同步至 A,在 BA 、CA、DA 之间的 pipe 需要配置database-name 和 table-name 限制范围,详细语句如下:
在 B IoTDB 上执行下列语句,将 B 中数据同步至 A:
create pipe BA
with source (
'database-name'='db_b.*', -- 限制范围
'table-name'='.*', -- 可选择匹配所有
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)在 C IoTDB 上执行下列语句,将 C 中数据同步至 A:
create pipe CA
with source (
'database-name'='db_c.*', -- 限制范围
'table-name'='.*', -- 可选择匹配所有
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)在 D IoTDB 上执行下列语句,将 D 中数据同步至 A:
create pipe DA
with source (
'database-name'='db_d.*', -- 限制范围
'table-name'='.*', -- 可选择匹配所有
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)3.4 级联数据传输
本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由 A 集群同步至 B 集群,再同步至 C 集群,数据链路如下图所示:
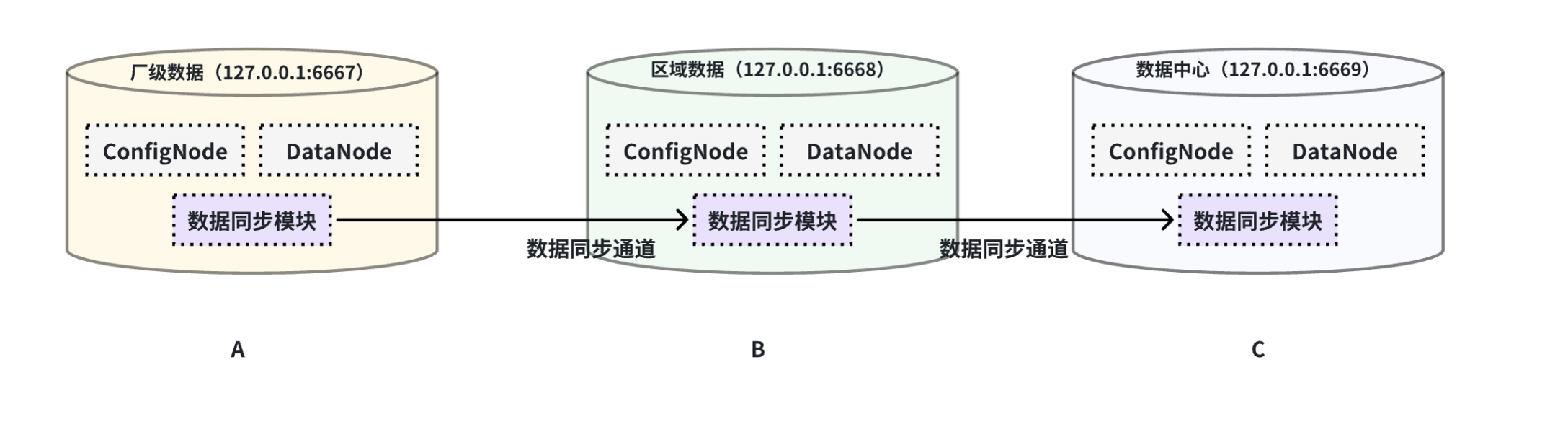
在 A IoTDB 上执行下列语句,将 A 中数据同步至 B:
create pipe AB
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)在 B IoTDB 上执行下列语句,将 B 中数据同步至 C:
create pipe BC
with source (
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
)3.5 压缩同步
IoTDB 支持在同步过程中指定数据压缩方式。可通过配置 compressor 参数,实现数据的实时压缩和传输。compressor目前支持 snappy / gzip / lz4 / zstd / lzma2 5 种可选算法,且可以选择多种压缩算法组合,按配置的顺序进行压缩。rate-limit-bytes-per-second(V1.3.3 及以后版本支持)每秒最大允许传输的byte数,计算压缩后的byte,若小于0则不限制。
如创建一个名为 A2B 的同步任务:
create pipe A2B
with sink (
'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
'compressor' = 'snappy,lz4' --
'rate-limit-bytes-per-second'='1048576' -- 每秒最大允许传输的byte数
)3.6 加密同步
IoTDB 支持在同步过程中使用 SSL 加密,从而在不同的 IoTDB 实例之间安全地传输数据。通过配置 SSL 相关的参数,如证书地址和密码(ssl.trust-store-path)、(ssl.trust-store-pwd)可以确保数据在同步过程中被 SSL 加密所保护。
如创建名为 A2B 的同步任务:
create pipe A2B
with sink (
'sink'='iotdb-thrift-ssl-sink',
'node-urls'='127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
'ssl.trust-store-path'='pki/trusted', -- 连接目标端 DataNode 所需的 trust store 证书路径
'ssl.trust-store-pwd'='root' -- 连接目标端 DataNode 所需的 trust store 证书密码
)参考:注意事项
可通过修改 IoTDB 配置文件(iotdb-system.properties)以调整数据同步的参数,如同步数据存储目录等。完整配置如下::
# pipe_receiver_file_dir
# If this property is unset, system will save the data in the default relative path directory under the IoTDB folder(i.e., %IOTDB_HOME%/${cn_system_dir}/pipe/receiver).
# If it is absolute, system will save the data in the exact location it points to.
# If it is relative, system will save the data in the relative path directory it indicates under the IoTDB folder.
# Note: If pipe_receiver_file_dir is assigned an empty string(i.e.,zero-size), it will be handled as a relative path.
# effectiveMode: restart
# For windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is absolute. Otherwise, it is relative.
# pipe_receiver_file_dir=data\\confignode\\system\\pipe\\receiver
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_receiver_file_dir=data/confignode/system/pipe/receiver
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# effectiveMode: first_start
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# effectiveMode: restart
# Datatype: int
pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# effectiveMode: restart
# Datatype: int
pipe_sink_timeout_ms=900000
# The maximum number of selectors that can be used in the sink.
# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
# effectiveMode: restart
# Datatype: int
pipe_sink_selector_number=4
# The maximum number of clients that can be used in the sink.
# effectiveMode: restart
# Datatype: int
pipe_sink_max_client_number=16
# The total bytes that all pipe sinks can transfer per second.
# When given a value less than or equal to 0, it means no limit.
# default value is -1, which means no limit.
# effectiveMode: hot_reload
# Datatype: double
pipe_all_sinks_rate_limit_bytes_per_second=-1参考:参数说明
source 参数
| 参数 | 描述 | value 取值范围 | 是否必填 | 默认取值 |
|---|---|---|---|---|
| source | iotdb-source | String: iotdb-source | 必填 | - |
| inclusion | 用于指定数据同步任务中需要同步范围,分为数据,元数据和权限 | String:all, data(insert,delete), schema(database,table,ttl), auth | 选填 | data.insert |
| inclusion.exclusion | 用于从 inclusion 指定的同步范围内排除特定的操作,减少同步的数据量 | String:all, data(insert,delete), schema(database,table,ttl), auth | 选填 | 空字符串 |
| mode.streaming | 此参数指定时序数据写入的捕获来源。适用于 mode.streaming为 false 模式下的场景,决定inclusion中data.insert数据的捕获来源。提供两种捕获策略:true: 动态选择捕获的类型。系统将根据下游处理速度,自适应地选择是捕获每个写入请求还是仅捕获 TsFile 文件的封口请求。当下游处理速度快时,优先捕获写入请求以减少延迟;当处理速度慢时,仅捕获文件封口请求以避免处理堆积。这种模式适用于大多数场景,能够实现处理延迟和吞吐量的最优平衡。false:固定按批捕获方式。仅捕获 TsFile 文件的封口请求,适用于资源受限的应用场景,以降低系统负载。注意,pipe 启动时捕获的快照数据只会以文件的方式供下游处理。 | Boolean: true / false | 否 | true |
| mode.strict | 在使用 time / path / database-name / table-name 参数过滤数据时,是否需要严格按照条件筛选:true: 严格筛选。系统将完全按照给定条件过滤筛选被捕获的数据,确保只有符合条件的数据被选中。false:非严格筛选。系统在筛选被捕获的数据时可能会包含一些额外的数据,适用于性能敏感的场景,可降低 CPU 和 IO 消耗。 | Boolean: true / false | 否 | true |
| mode.snapshot | 此参数决定时序数据的捕获方式,影响inclusion中的data数据。提供两种模式:true:静态数据捕获。启动 pipe 时,会进行一次性的数据快照捕获。当快照数据被完全消费后,pipe 将自动终止(DROP PIPE SQL 会自动执行)。false:动态数据捕获。除了在 pipe 启动时捕获快照数据外,还会持续捕获后续的数据变更。pipe 将持续运行以处理动态数据流。 | Boolean: true / false | 否 | false |
| database-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响inclusion中的data数据。表示要过滤的数据库的名称。它可以是具体的数据库名,也可以是 Java 风格正则表达式来匹配多个数据库。默认情况下,匹配所有的库。 | String:数据库名或数据库正则模式串,可以匹配未创建的、不存在的库 | 否 | ".*" |
| table-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响inclusion中的data数据。表示要过滤的表的名称。它可以是具体的表名,也可以是 Java 风格正则表达式来匹配多个表。默认情况下,匹配所有的表。 | String:数据表名或数据表正则模式串,可以是未创建的、不存在的表 | 否 | ".*" |
| start-time | 此参数决定时序数据的捕获范围,影响inclusion中的data数据。当数据的 event time 大于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] (unix 裸时间戳)或 String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MIN_VALUE(unix 裸时间戳) |
| end-time | 此参数决定时序数据的捕获范围,影响inclusion中的data数据。当数据的 event time 小于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE](unix 裸时间戳)或String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MAX_VALUE(unix 裸时间戳) |
| mods | 同 mods.enable,是否发送 tsfile 的 mods 文件 | Boolean: true / false | 选填 | false |
| skipIf | 出现哪些错误可以跳过,当前只有无权限的错误 | String:no-privileges | 选填 | no-privileges |
💎 说明:数据抽取模式 mode.streaming 取值 true 和 false 的差异
- true(推荐):该取值下,任务将对数据进行实时处理、发送,其特点是高时效、低吞吐
- false:该取值下,任务将对数据进行批量(按底层数据文件)处理、发送,其特点是低时效、高吞吐
sink 参数
iotdb-thrift-sink
| 参数 | 描述 | value 取值范围 | 是否必填 | 默认取值 |
|---|---|---|---|---|
| sink | iotdb-thrift-sink 或 iotdb-thrift-async-sink | String: iotdb-thrift-sink 或 iotdb-thrift-async-sink | 必填 | - |
| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
| user/username | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
| batch.max-delay-ms | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:ms) (V2.0.5及以后版本支持) | Integer | 选填 | 1 |
| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 1610241024 |
| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
| load-tsfile-strategy | 文件同步数据时,接收端请求返回发送端前,是否等待接收端本地的 load tsfile 执行结果返回。 sync:等待本地的 load tsfile 执行结果返回; async:不等待本地的 load tsfile 执行结果返回。 | String: sync / async | 选填 | sync |
| format | 数据传输的payload格式, 可选项包括: - hybrid: 取决于 processor 传递过来的格式(tsfile或tablet),sink不做任何转换。 - tsfile:强制转换成tsfile发送,可用于数据文件备份等场景。 - tablet:强制转换成tsfile发送,可用于发送端/接收端数据类型不完全兼容时的数据同步(以减少报错)。 | String: hybrid / tsfile / tablet | 选填 | hybrid |
| exception.data.convert-on-type-mismatch | 接收端类型不同时是否转换 | Boolean: true / false | 选填 | true |
iotdb-thrift-ssl-sink
| 参数 | 描述 | value 取值范围 | 是否必填 | 默认取值 |
|---|---|---|---|---|
| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | 必填 | - |
| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
| user/username | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
| batch.max-delay-ms | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:ms)(V2.0.5及以后版本支持) | Integer | 选填 | 1 |
| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 1610241024 |
| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
| load-tsfile-strategy | 文件同步数据时,接收端请求返回发送端前,是否等待接收端本地的 load tsfile 执行结果返回。 sync:等待本地的 load tsfile 执行结果返回; async:不等待本地的 load tsfile 执行结果返回。 | String: sync / async | 选填 | sync |
| ssl.trust-store-path | 连接目标端 DataNode 所需的 trust store 证书路径 | String: 'pki/trusted' | 必填 | - |
| ssl.trust-store-pwd | 连接目标端 DataNode 所需的 trust store 证书密码 | String: 'root' | 必填 | - |
| format | 数据传输的payload格式, 可选项包括: - hybrid: 取决于 processor 传递过来的格式(tsfile或tablet),sink不做任何转换。 - tsfile:强制转换成tsfile发送,可用于数据文件备份等场景。 - tablet:强制转换成tsfile发送,可用于发送端/接收端数据类型不完全兼容时的数据同步(以减少报错)。 | String: hybrid / tsfile / tablet | 选填 | hybrid |
| exception.data.convert-on-type-mismatch | 接收端类型不同时是否转换 | Boolean: true / false | 选填 | true |