Apache Spark
Apache Spark
1. 功能概述
IoTDB 提供 Spark-IoTDB-Table-Connector 作为实现 IoTDB 表模型的 Spark 连接器,支持在 Spark 环境中,通过 DataFrame 以及 Spark SQL 两种方式对 IoTDB 表模型的数据进行读写。
1.1 DataFrame
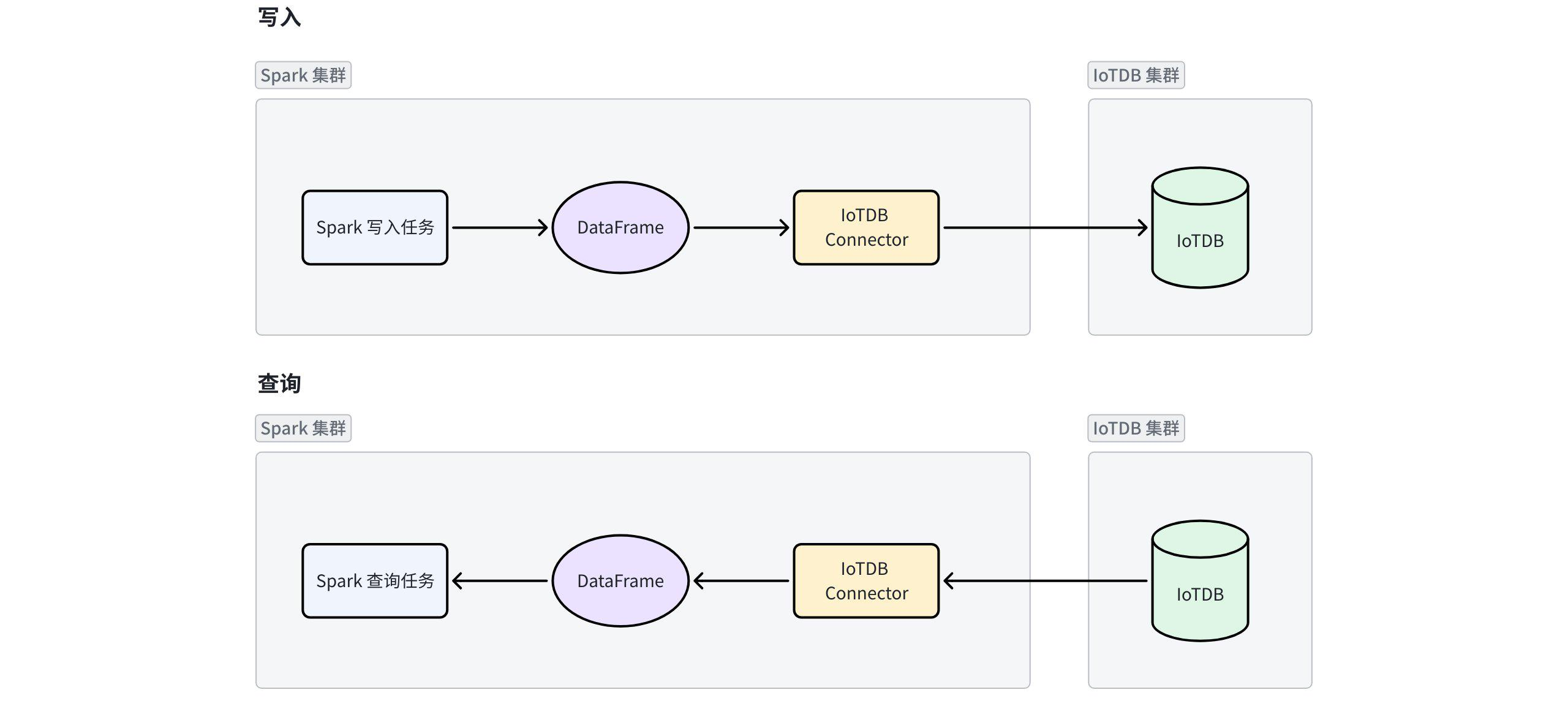
DataFrame 是 Spark 编程中不同算子之间传递数据的常用数据结构,包含表头等元信息。DateFrame 的转换操作均采用惰性执行(Lazy Execution)机制,只有在触发动作时(如输出或存储等)才会实际执行,从而避免冗余计算资源消耗。
在使用时,上游任务处理好的 DataFrame 可以通过 Spark-IoTDB-Table-Connector 直接写入 IoTDB 的表中,也可以从 IoTDB 的表中直接读取数据成 DataFrame 的形式,供下游任务继续分析。
1.2 Spark SQL
Spark-IoTDB-Table-Connector 还支持将 IoTDB 中的表映射成 Spark 中的外表(temporary view),然后在 Spark-SQL Shell 中,使用 Spark SQL 直接读写。
2. 兼容性要求
| 软件 | 版本 |
|---|---|
Spark-IoTDB-Table-Connector | 2.0.3 |
Spark | 3.3-3.5 |
IoTDB | 2.0.1+ |
Scala | 2.12 |
JDK | 8、11 |
3. 部署方式
3.1 DataFrame
通过 DataFrame 方式时,只需要在项目的 pom 中引入 Spark-IoTDB-Table-Connector 的依赖。
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>spark-iotdb-table-connector-3.5</artifactId>
<version>2.0.3</version>
</dependency>3.2 Spark SQL
通过 Spark SQL 方式时,需要先在官网下载 Spark-IoTDB-Table-Connector 的 Jar 包。然后再将 Jar 包拷贝到 ${SPARK_HOME}/jars 目录中即可。

4. 使用方式
4.1 读取数据
4.1.1 DataFrame
val df = spark.read.format("org.apache.iotdb.spark.table.db.IoTDBTableProvider")
.option("iotdb.database", "$YOUR_IOTDB_DATABASE_NAME")
.option("iotdb.table", "$YOUR_IOTDB_TABLE_NAME")
.option("iotdb.username", "$YOUR_IOTDB_USERNAME")
.option("iotdb.password", "$YOUR_IOTDB_PASSWORD")
.option("iotdb.url", "$YOUR_IOTDB_URL")
.load()4.1.2 Spark SQL
CREATE TEMPORARY VIEW spark_iotdb
USING org.apache.iotdb.spark.table.db.IoTDBTableProvider
OPTIONS(
"iotdb.database"="$YOUR_IOTDB_DATABASE_NAME",
"iotdb.table"="$YOUR_IOTDB_TABLE_NAME",
"iotdb.username"="$YOUR_IOTDB_USERNAME",
"iotdb.password"="$YOUR_IOTDB_PASSWORD",
"iotdb.urls"="$YOUR_IOTDB_URL"
);
SELECT * FROM spark_iotdb;4.1.3 参数介绍
| 参数 | 默认值 | 描述 | 是否必填 |
|---|---|---|---|
iotdb.database | -- | IoTDB 的数据库名,需要是已经在 IoTDB 中存在的数据库 | 是 |
iotdb.table | -- | IoTDB 中的表名,需要是已经在 IoTDB 中存在的表 | 是 |
iotdb.username | root | 访问 IoTDB 用户名 | 否 |
iotdb.password | root | 访问 IoTDB 密码 | 否 |
iotdb.urls | 127.0.0.1:6667 | 客户端连接 datanode rpc 的 url,有多个时以 ',' 分隔 | 否 |
4.1.4 注意事项
查询 IoTDB 时支持在 IoTDB 侧完成部分查询条件的过滤、列裁剪、offset 和 limit 下推。
- 可下推的查询过滤条件包括:
| Name | SQL( IoTDB) |
|---|---|
IS_NULL | expr IS NULL |
IS_NOT_NULL | expr IS NOT NULL |
STARTS_WITH | starts_with(expr1, expr2) |
ENDS_WITH | ends_with(expr1, expr2) |
CONTAINS | expr1 LIKE '%expr2%' |
IN | expr IN (expr1, expr2,...) |
= | expr1 = expr2 |
<> | expr1 <> expr2 |
< | expr1 < expr2 |
<= | expr1 <= expr2 |
> | expr1 > expr2 |
>= | expr1 >= expr2 |
AND | expr1 AND expr2 |
OR | expr1 OR expr2 |
NOT | NOT expr |
ALWAYS_TRUE | TRUE |
ALWAYS_FALSE | FASLE |
注意:
- CONTAINS 的 expr2 只支持常量
- 如果出现某个 child 无法下推的情况,对应的整个合取式都不会下推
- 列裁剪:
支持在拼接 IoTDB 的 SQL 时指定列名,避免传输不需要的列的数据
- offset 和 limit 下推:
支持下推 offset 和 limit,支持直接根据 Spark 提供的 offset 和 limit 参数进行拼接
4.2 写入数据
4.2.1 DataFrame
val df = spark.createDataFrame(List(
(1L, "tag1_value1", "tag2_value1", "attribute1_value1", 1, true),
(2L, "tag1_value1", "tag2_value2", "attribute1_value1", 2, false)))
.toDF("time", "tag1", "tag2", "attribute1", "s1", "s2")
df
.write
.format("org.apache.iotdb.spark.table.db.IoTDBTableProvider")
.option("iotdb.database", "$YOUR_IOTDB_DATABASE_NAME")
.option("iotdb.table", "$YOUR_IOTDB_TABLE_NAME")
.option("iotdb.username", "$YOUR_IOTDB_USERNAME")
.option("iotdb.password", "$YOUR_IOTDB_PASSWORD")
.option("iotdb.urls", "$YOUR_IOTDB_URL")
.save()4.2.2 Spark SQL
CREATE TEMPORARY VIEW spark_iotdb
USING org.apache.iotdb.spark.table.db.IoTDBTableProvider
OPTIONS(
"iotdb.database"="$YOUR_IOTDB_DATABASE_NAME",
"iotdb.table"="$YOUR_IOTDB_TABLE_NAME",
"iotdb.username"="$YOUR_IOTDB_USERNAME",
"iotdb.password"="$YOUR_IOTDB_PASSWORD",
"iotdb.urls"="$YOUR_IOTDB_URL"
);
INSERT INTO spark_iotdb VALUES ("VALUE1", "VALUE2", ...);
INSERT INTO spark_iotdb SELECT * FROM YOUR_TABLE4.2.3 注意事项
- 向 IoTDB 写入数据时,不支持自动建表/自动扩展列。
- 通过
INSERT INTO VALUES方式写入时,无法指定 VALUES 中对应的列名,VALUES 的顺序必须与表结构(即在 IoTDB 中执行Desc Table输出的列顺序)一致。否则,会抛出SparkException异常。 - 通过
INSERT INTO SELECT方式写入时,所有列必须在 IoTDB 的表中已经存在,当出现 Schema 中缺少的列时,会像INSERT INTO VALUES一样尝试按顺序进行写入。 - 当使用 DataFrame 或
INSERT INTO SELECT方式写入时,如果指定了每一列的列名,则允许与 Table Schema 顺序不一致。 - 当写入的列数超过表的列数时,会抛出
IllegalArgumentException异常。
4.3 数据类型映射
- 读取数据时,从 IoTDB 的数据类型映射到 Spark 的数据类型。
| IoTDB Type | Spark Type |
|---|---|
TsDataType.BOOLEAN | BooleanType |
TsDataType.INT32 | IntegerType |
TsDataType.DATE | DateType |
TsDataType.INT64 | LongType |
TsDataType.TIMESTAMP | LongType |
TsDataType.FLOAT | FloatType |
TsDataType.DOUBLE | DoubleType |
TsDataType.STRING | StringType |
TsDataType.TEXT | StringType |
TsDataType.BLOB | BinaryType |
- 向 IoTDB 写入数据时,需要从 Spark 的数据类型映射到 IoTDB 的数据类型
主要是映射成 Tablet 进行写入,而 Tablet 在写入到 IoTDB 时如果类型不一致可再次进行类型转换。
| Spark Type | IoTDB Type |
|---|---|
BooleanType | TsDataType.BOOLEAN |
ByteType | TsDataType.INT32 |
ShortType | TsDataType.INT32 |
IntegerType | TsDataType.INT32 |
LongType | TsDataType.INT64 |
FloatType | TsDataType.FLOAT |
DoubleType | TsDataType.DOUBLE |
StringType | TsDataType.STRING |
BinaryType | TsDataType.BLOB |
DateType | TsDataType.DATE |
其他 | TsDataType.STRING |
4.4 权限控制
- 身份验证和授权
通过 Spark 连接器进行 IoTDB 的读取和写入时,需要提供用户名和密码,确保只有合法用户才能访问系统。
- 访问控制
- 写入时:与 IoTDB 中对于写入操作的鉴权相同,但因为 Spark 连接器不支持自动建表和自动扩展列,所以需要对应表(或所属 DB 、或 ANY )上的 INSERT 权限
- 查询时:与 IoTDB 中对于查询操作的鉴权相同,所以需要对应表(或所属 DB、或 ANY )上的 SELECT 权限