SQL手册
SQL手册
元数据操作
1、数据库管理
创建数据库
CREATE DATABASE root.ln
CREATE DATABASE root.ln.wf01
> Msg: 300: root.ln has already been created as database.查看数据库
show databases
show databases root.*
show databases root.**删除数据库
DELETE DATABASE root.ln
DELETE DATABASE root.sgcc
DELETE DATABASE root.**统计数据库数量
count databases
count databases root.*
count databases root.sgcc.*
count databases root.sgcc2、时间序列管理
创建时间序列
create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE- 简化版
create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN
create timeseries root.ln.wf01.wt01.temperature FLOAT encoding=RLE
create timeseries root.ln.wf02.wt02.hardware TEXT encoding=PLAIN
create timeseries root.ln.wf02.wt02.status BOOLEAN encoding=PLAIN
create timeseries root.sgcc.wf03.wt01.status BOOLEAN encoding=PLAIN
create timeseries root.sgcc.wf03.wt01.temperature FLOAT encoding=RLE- 错误提示
create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
> error: encoding TS_2DIFF does not support BOOLEAN创建对齐时间序列
CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY)删除时间序列
delete timeseries root.ln.wf01.wt01.status
delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
delete timeseries root.ln.wf02.*
drop timeseries root.ln.wf02.*查看时间序列
SHOW TIMESERIES
SHOW TIMESERIES <Path>
show timeseries root.**
show timeseries root.ln.**
show timeseries root.ln.** limit 10 offset 10
show timeseries root.ln.** where timeseries contains 'wf01.wt'
show timeseries root.ln.** where dataType=FLOAT
SHOW LATEST TIMESERIES统计时间序列数量
COUNT TIMESERIES root.**
COUNT TIMESERIES root.ln.**
COUNT TIMESERIES root.ln.*.*.status
COUNT TIMESERIES root.ln.wf01.wt01.status
COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc'
COUNT TIMESERIES root.** WHERE DATATYPE = INT64
COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c'
COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c'
COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1
COUNT TIMESERIES root.** GROUP BY LEVEL=1
COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2
COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2标签点管理
create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)- 重命名标签或属性
ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1- 重新设置标签或属性的值
ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1- 删除已经存在的标签或属性
ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2- 添加新的标签
ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4- 添加新的属性
ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4- 更新插入别名,标签和属性
ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag2=newV2, tag3=v3) ATTRIBUTES(attr3=v3, attr4=v4)- 使用标签作为过滤条件查询时间序列
SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause返回给定路径下的所有满足条件的时间序列信息:
show timeseries root.ln.** where TAGS(unit)='c'
show timeseries root.ln.** where TAGS(description) contains 'test1'- 使用标签作为过滤条件统计时间序列数量
COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=<INTEGER>返回给定路径下的所有满足条件的时间序列的数量:
count timeseries
count timeseries root.** where TAGS(unit)='c'
count timeseries root.** where TAGS(unit)='c' group by level = 2创建对齐时间序列:
create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4))支持查询:
show timeseries where TAGS(tag1)='v1'3、时间序列路径管理
查看路径的所有子路径
SHOW CHILD PATHS pathPattern
- 查询 root.ln 的下一层:show child paths root.ln
- 查询形如 root.xx.xx.xx 的路径:show child paths root..
查看路径的所有子节点
SHOW CHILD NODES pathPattern
- 查询 root 的下一层:show child nodes root
- 查询 root.ln 的下一层 :show child nodes root.ln
查看设备
IoTDB> show devices
IoTDB> show devices root.ln.**查看设备及其 database 信息
IoTDB> show devices with database
IoTDB> show devices root.ln.** with database统计节点数
IoTDB > COUNT NODES root.** LEVEL=2
IoTDB > COUNT NODES root.ln.** LEVEL=2
IoTDB > COUNT NODES root.ln.wf01.* LEVEL=3
IoTDB > COUNT NODES root.**.temperature LEVEL=3统计设备数量
IoTDB> show devices
IoTDB> count devices
IoTDB> count devices root.ln.**4、设备模板管理
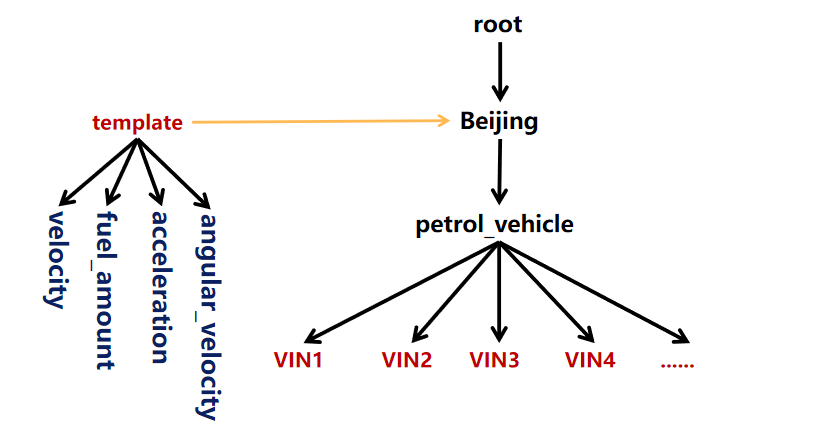
Create template(s1 int, s2 float) on root.sg
Create device root.sg.d1
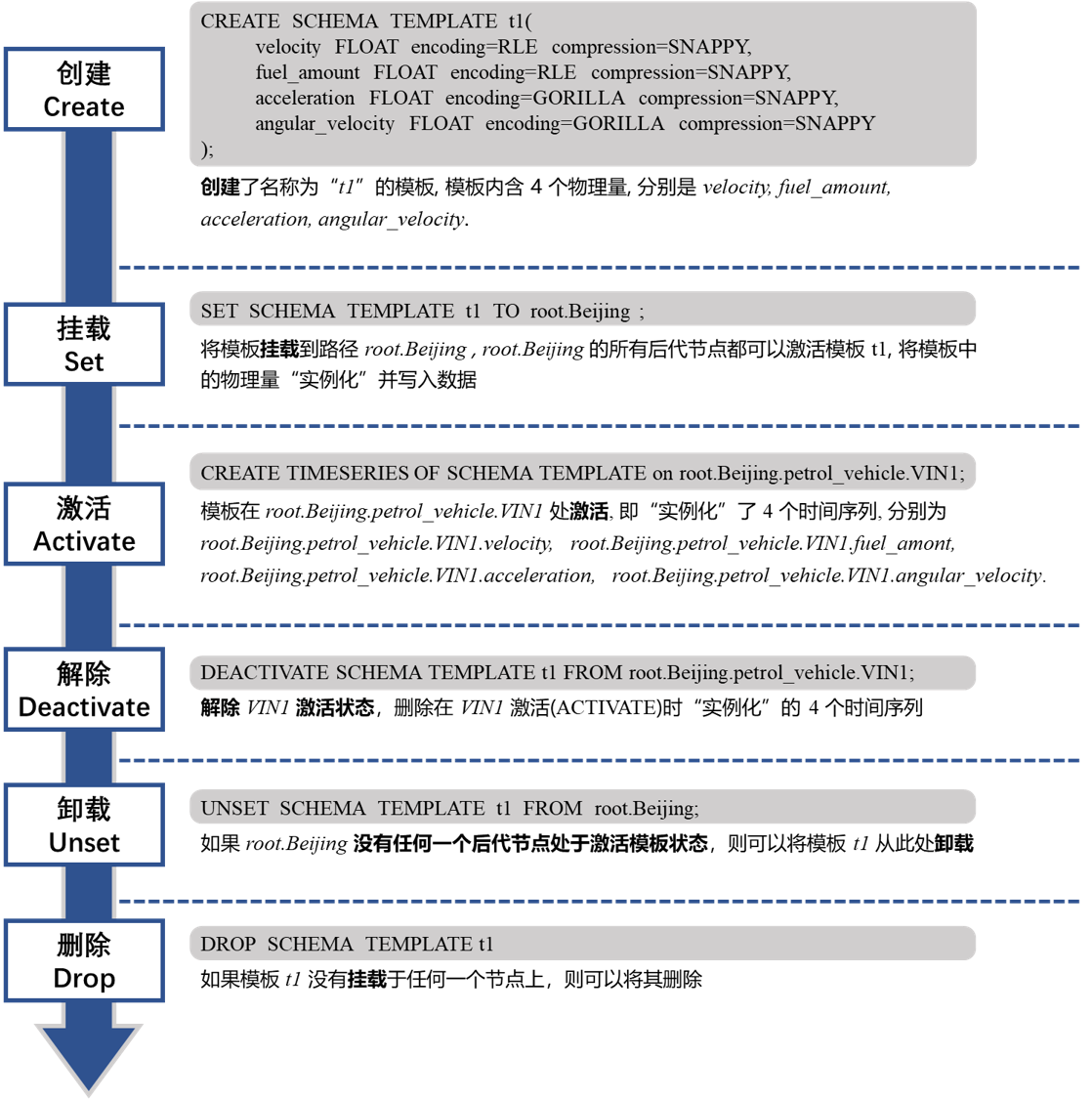
创建元数据模板
CREATE SCHEMA TEMPLATE <templateName> ALIGNED? '(' <measurementId> <attributeClauses> [',' <measurementId> <attributeClauses>]+ ')'创建包含两个非对齐序列的元数据模板
IoTDB> create schema template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY)创建包含一组对齐序列的元数据模板
IoTDB> create schema template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)挂载元数据模板
IoTDB> set SCHEMA TEMPLATE t1 to root.sg1激活元数据模板
IoTDB> create timeseries using SCHEMA TEMPLATE on root.sg1.d1
IoTDB> set SCHEMA TEMPLATE t1 to root.sg1.d1
IoTDB> set SCHEMA TEMPLATE t2 to root.sg1.d2
IoTDB> create timeseries using schema template on root.sg1.d1
IoTDB> create timeseries using schema template on root.sg1.d2查看元数据模板
IoTDB> show schema templates
- 查看某个元数据模板下的物理量
IoTDB> show nodes in schema template t1
- 查看挂载了某个元数据模板的路径
IoTDB> show paths set schema template t1
- 查看使用了某个元数据模板的路径(即模板在该路径上已激活,序列已创建)
IoTDB> show paths using schema template t1
IoTDB> show devices using schema template t1
解除元数据模板
IoTDB> delete timeseries of schema template t1 from root.sg1.d1
IoTDB> deactivate schema template t1 from root.sg1.d1批量处理
IoTDB> delete timeseries of schema template t1 from root.sg1.*, root.sg2.*
IoTDB> deactivate schema template t1 from root.sg1.*, root.sg2.*卸载元数据模板
IoTDB> unset schema template t1 from root.sg1.d1删除元数据模板
IoTDB> drop schema template t15、数据存活时间管理
设置 TTL
IoTDB> set ttl to root.ln 3600000
IoTDB> set ttl to root.sgcc.** 3600000
IoTDB> set ttl to root.** 3600000取消 TTL
IoTDB> unset ttl to root.ln
IoTDB> unset ttl to root.sgcc.**
IoTDB> unset ttl to root.**显示 TTL
IoTDB> SHOW ALL TTL
IoTDB> SHOW TTL ON StorageGroupNames写入数据
1、写入单列数据
IoTDB > insert into root.ln.wf02.wt02(timestamp,status) values(1,true)
IoTDB > insert into root.ln.wf02.wt02(timestamp,hardware) values(1, 'v1'),(2, 'v1')2、写入多列数据
IoTDB > insert into root.ln.wf02.wt02(timestamp, status, hardware) values (2, false, 'v2')
IoTDB > insert into root.ln.wf02.wt02(timestamp, status, hardware) VALUES (3, false, 'v3'),(4, true, 'v4')3、使用服务器时间戳
IoTDB > insert into root.ln.wf02.wt02(status, hardware) values (false, 'v2')4、写入对齐时间序列数据
IoTDB > create aligned timeseries root.sg1.d1(s1 INT32, s2 DOUBLE)
IoTDB > insert into root.sg1.d1(timestamp, s1, s2) aligned values(1, 1, 1)
IoTDB > insert into root.sg1.d1(timestamp, s1, s2) aligned values(2, 2, 2), (3, 3, 3)
IoTDB > select * from root.sg1.d15、加载 TsFile 文件数据
load '<path/dir>' [sglevel=int][onSuccess=delete/none]通过指定文件路径(绝对路径)加载单 tsfile 文件
load '/Users/Desktop/data/1575028885956-101-0.tsfile'load '/Users/Desktop/data/1575028885956-101-0.tsfile' sglevel=1load '/Users/Desktop/data/1575028885956-101-0.tsfile' onSuccess=deleteload '/Users/Desktop/data/1575028885956-101-0.tsfile' sglevel=1 onSuccess=delete
通过指定文件夹路径(绝对路径)批量加载文件
load '/Users/Desktop/data'load '/Users/Desktop/data' sglevel=1load '/Users/Desktop/data' onSuccess=deleteload '/Users/Desktop/data' sglevel=1 onSuccess=delete
删除数据
1、删除单列数据
delete from root.ln.wf02.wt02.status where time<=2017-11-01T16:26:00;
delete from root.ln.wf02.wt02.status where time>=2017-01-01T00:00:00 and time<=2017-11-01T16:26:00;
delete from root.ln.wf02.wt02.status where time < 10
delete from root.ln.wf02.wt02.status where time <= 10
delete from root.ln.wf02.wt02.status where time < 20 and time > 10
delete from root.ln.wf02.wt02.status where time <= 20 and time >= 10
delete from root.ln.wf02.wt02.status where time > 20
delete from root.ln.wf02.wt02.status where time >= 20
delete from root.ln.wf02.wt02.status where time = 20出错:
delete from root.ln.wf02.wt02.status where time > 4 or time < 0
Msg: 303: Check metadata error: For delete statement, where clause can only contain atomic
expressions like : time > XXX, time <= XXX, or two atomic expressions connected by 'AND'删除时间序列中的所有数据:
delete from root.ln.wf02.wt02.status2、删除多列数据
delete from root.ln.wf02.wt02.* where time <= 2017-11-01T16:26:00;声明式的编程方式:
IoTDB> delete from root.ln.wf03.wt02.status where time < now()
Msg: The statement is executed successfully.数据查询
1、基础查询
时间过滤查询
select temperature from root.ln.wf01.wt01 where time < 2017-11-01T00:08:00.000根据一个时间区间选择多列数据
select status, temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;按照多个时间区间选择同一设备的多列数据
select status, temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);按照多个时间区间选择不同设备的多列数据
select wf01.wt01.status, wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);根据时间降序返回结果集
select * from root.ln.** where time > 1 order by time desc limit 10;2、选择表达式
使用别名
select s1 as temperature, s2 as speed from root.ln.wf01.wt01;运算符
函数
不支持:
select s1, count(s1) from root.sg.d1;
select sin(s1), count(s1) from root.sg.d1;
select s1, count(s1) from root.sg.d1 group by ([10,100),10ms);时间序列查询嵌套表达式
示例 1:
select a,
b,
((a + 1) * 2 - 1) % 2 + 1.5,
sin(a + sin(a + sin(b))),
-(a + b) * (sin(a + b) * sin(a + b) + cos(a + b) * cos(a + b)) + 1
from root.sg1;示例 2:
select (a + b) * 2 + sin(a) from root.sg示例 3:
select (a + *) / 2 from root.sg1示例 4:
select (a + b) * 3 from root.sg, root.ln聚合查询嵌套表达式
示例 1:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware)
from root.ln.wf01.wt01;示例 2:
select avg(*),
(avg(*) + 1) * 3 / 2 -1
from root.sg1示例 3:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware) as custom_sum
from root.ln.wf01.wt01
GROUP BY([10, 90), 10ms);最新点查询
SQL 语法:
select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <whereClause> [ORDER BY TIMESERIES (DESC | ASC)?]查询 root.ln.wf01.wt01.status 的最新数据点
IoTDB> select last status from root.ln.wf01.wt01查询 root.ln.wf01.wt01 下 status,temperature 时间戳大于等于 2017-11-07T23:50:00 的最新数据点
IoTDB> select last status, temperature from root.ln.wf01.wt01 where time >= 2017-11-07T23:50:00查询 root.ln.wf01.wt01 下所有序列的最新数据点,并按照序列名降序排列
IoTDB> select last * from root.ln.wf01.wt01 order by timeseries desc;3、查询过滤条件
时间过滤条件
选择时间戳大于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time > 2022-01-01T00:05:00.000;选择时间戳等于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time = 2022-01-01T00:05:00.000;选择时间区间 [2017-11-01T00:05:00.000, 2017-11-01T00:12:00.000) 内的数据:
select s1 from root.sg1.d1 where time >= 2022-01-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;值过滤条件
选择值大于 36.5 的数据:
select temperature from root.sg1.d1 where temperature > 36.5;选择值等于 true 的数据:
select status from root.sg1.d1 where status = true;选择区间 [36.5,40] 内或之外的数据:
select temperature from root.sg1.d1 where temperature between 36.5 and 40;
select temperature from root.sg1.d1 where temperature not between 36.5 and 40;选择值在特定范围内的数据:
select code from root.sg1.d1 where code in ('200', '300', '400', '500');选择值在特定范围外的数据:
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');选择值为空的数据:
select code from root.sg1.d1 where temperature is null;选择值为非空的数据:
select code from root.sg1.d1 where temperature is not null;模糊查询
查询 root.sg.d1 下 value 含有'cc'的数据
IoTDB> select * from root.sg.d1 where value like '%cc%'查询 root.sg.d1 下 value 中间为 'b'、前后为任意单个字符的数据
IoTDB> select * from root.sg.device where value like '_b_'查询 root.sg.d1 下 value 值为26个英文字符组成的字符串
IoTDB> select * from root.sg.d1 where value regexp '^[A-Za-z]+$'查询 root.sg.d1 下 value 值为26个小写英文字符组成的字符串且时间大于100的
IoTDB> select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 1004、分段分组聚合
未指定滑动步长的时间区间分组聚合查询
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);指定滑动步长的时间区间分组聚合查询
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);滑动步长可以小于聚合窗口
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-01 10:00:00), 4h, 2h);按照自然月份的时间区间分组聚合查询
select count(status) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 group by([2017-11-01T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);每个时间间隔窗口内都有数据
select count(status) from root.ln.wf01.wt01 group by([2017-10-31T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);左开右闭区间
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);与分组聚合混合使用
统计降采样后的数据点个数
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d), level=1;加上滑动 Step 的降采样后的结果也可以汇总
select count(status) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d), level=1;路径层级分组聚合
统计不同 database 下 status 序列的数据点个数
select count(status) from root.** group by level = 1统计不同设备下 status 序列的数据点个数
select count(status) from root.** group by level = 3统计不同 database 下的不同设备中 status 序列的数据点个数
select count(status) from root.** group by level = 1, 3查询所有序列下温度传感器 temperature 的最大值
select max_value(temperature) from root.** group by level = 0查询某一层级下所有传感器拥有的总数据点数
select count(*) from root.ln.** group by level = 2标签分组聚合
单标签聚合查询
SELECT AVG(temperature) FROM root.factory1.** GROUP BY TAGS(city);多标签聚合查询
SELECT avg(temperature) FROM root.factory1.** GROUP BY TAGS(city, workshop);基于时间区间的标签聚合查询
SELECT AVG(temperature) FROM root.factory1.** GROUP BY ([1000, 10000), 5s), TAGS(city, workshop);差值分段聚合
group by variation(controlExpression[,delta][,ignoreNull=true/false])delta=0时的等值事件分段
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6)指定ignoreNull为false
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, ignoreNull=false)delta!=0时的差值事件分段
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, 4)条件分段聚合
group by condition(predict,[keep>/>=/=/<=/<]threshold,[,ignoreNull=true/false])查询至少连续两行以上的charging_status=1的数据
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=true)当设置ignoreNull为false时,遇到null值为将其视为一个不满足条件的行,得到结果原先的分组被含null的行拆分
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=false)会话分段聚合
group by session(timeInterval)按照不同的时间单位设定时间间隔
select __endTime,count(*) from root.** group by session(1d)和HAVING、ALIGN BY DEVICE共同使用
select __endTime,sum(hardware) from root.ln.wf02.wt01 group by session(50s) having sum(hardware)>0 align by device点数分段聚合
group by count(controlExpression, size[,ignoreNull=true/false])
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5)当使用ignoreNull将null值也考虑进来
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5,ignoreNull=false)5、聚合结果过滤
不正确的:
select count(s1) from root.** group by ([1,3),1ms) having sum(s1) > s1
select count(s1) from root.** group by ([1,3),1ms) having s1 > 1
select count(s1) from root.** group by ([1,3),1ms), level=1 having sum(d1.s1) > 1
select count(d1.s1) from root.** group by ([1,3),1ms), level=1 having sum(s1) > 1SQL 示例:
select count(s1) from root.** group by ([1,11),2ms), level=1 having count(s2) > 2;
select count(s1), count(s2) from root.** group by ([1,11),2ms) having count(s2) > 1 align by device;6、结果集补空值
FILL '(' PREVIOUS | LINEAR | constant ')'PREVIOUS 填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(previous);LINEAR 填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(linear);常量填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(2.0);使用 BOOLEAN 类型的常量填充
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(true);7、查询结果分页
按行分页
基本的 LIMIT 子句
select status, temperature from root.ln.wf01.wt01 limit 10带 OFFSET 的 LIMIT 子句
select status, temperature from root.ln.wf01.wt01 limit 5 offset 3LIMIT 子句与 WHERE 子句结合
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time< 2017-11-01T00:12:00.000 limit 5 offset 3LIMIT 子句与 GROUP BY 子句组合
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) limit 4 offset 3按列分页
基本的 SLIMIT 子句
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1带 SOFFSET 的 SLIMIT 子句
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 1SLIMIT 子句与 GROUP BY 子句结合
select max_value(*) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) slimit 1 soffset 1SLIMIT 子句与 LIMIT 子句结合
select * from root.ln.wf01.wt01 limit 10 offset 100 slimit 2 soffset 08、排序
时间对齐模式下的排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time desc;设备对齐模式下的排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by device desc,time asc align by device;在时间戳相等时按照设备名排序
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time asc,device desc align by device;没有显式指定时
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;对聚合后的结果进行排序
select count(*) from root.ln.** group by ((2017-11-01T00:00:00.000+08:00,2017-11-01T00:03:00.000+08:00],1m) order by device asc,time asc align by device9、查询对齐模式
按设备对齐
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;10、查询写回(SELECT INTO)
整体描述
selectIntoStatement
: SELECT
resultColumn [, resultColumn] ...
INTO intoItem [, intoItem] ...
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY groupByTimeClause, groupByLevelClause]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
;
intoItem
: [ALIGNED] intoDevicePath '(' intoMeasurementName [',' intoMeasurementName]* ')'
;按时间对齐,将 root.sg database 下四条序列的查询结果写入到 root.sg_copy database 下指定的四条序列中
IoTDB> select s1, s2 into root.sg_copy.d1(t1), root.sg_copy.d2(t1, t2), root.sg_copy.d1(t2) from root.sg.d1, root.sg.d2;按时间对齐,将聚合查询的结果存储到指定序列中
IoTDB> select count(s1 + s2), last_value(s2) into root.agg.count(s1_add_s2), root.agg.last_value(s2) from root.sg.d1 group by ([0, 100), 10ms);按设备对齐
IoTDB> select s1, s2 into root.sg_copy.d1(t1, t2), root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;按设备对齐,将表达式计算的结果存储到指定序列中
IoTDB> select s1 + s2 into root.expr.add(d1s1_d1s2), root.expr.add(d2s1_d2s2) from root.sg.d1, root.sg.d2 align by device;使用变量占位符
按时间对齐(默认)
(1)目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
select s1, s2
into root.sg_copy.d1(::), root.sg_copy.d2(s1), root.sg_copy.d1(${3}), root.sg_copy.d2(::)
from root.sg.d1, root.sg.d2;该语句等价于:
select s1, s2
into root.sg_copy.d1(s1), root.sg_copy.d2(s1), root.sg_copy.d1(s2), root.sg_copy.d2(s2)
from root.sg.d1, root.sg.d2;(2)目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
select d1.s1, d1.s2, d2.s3, d3.s4
into ::(s1_1, s2_2), root.sg.d2_2(s3_3), root.${2}_copy.::(s4)
from root.sg;(3)目标设备使用变量占位符 & 目标物理量列表使用变量占位符
select * into root.sg_bk.::(::) from root.sg.**;按设备对齐(使用 ALIGN BY DEVICE)
(1)目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
select s1, s2, s3, s4
into root.backup_sg.d1(s1, s2, s3, s4), root.backup_sg.d2(::), root.sg.d3(backup_${4})
from root.sg.d1, root.sg.d2, root.sg.d3
align by device;(2)目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
select avg(s1), sum(s2) + sum(s3), count(s4)
into root.agg_${2}.::(avg_s1, sum_s2_add_s3, count_s4)
from root.**
align by device;(3)目标设备使用变量占位符 & 目标物理量列表使用变量占位符
select * into ::(backup_${4}) from root.sg.** align by device;指定目标序列为对齐序列
select s1, s2 into root.sg_copy.d1(t1, t2), aligned root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;运算符
算数运算符
更多见文档 Arithmetic Operators and Functions
select s1, - s1, s2, + s2, s1 + s2, s1 - s2, s1 * s2, s1 / s2, s1 % s2 from root.sg.d1比较运算符
更多见文档Comparison Operators and Functions
# Basic comparison operators
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
# `BETWEEN ... AND ...` operator
select temperature from root.sg1.d1 where temperature between 36.5 and 40;
select temperature from root.sg1.d1 where temperature not between 36.5 and 40;
# Fuzzy matching operator: Use `Like` for fuzzy matching
select * from root.sg.d1 where value like '%cc%'
select * from root.sg.device where value like '_b_'
# Fuzzy matching operator: Use `Regexp` for fuzzy matching
select * from root.sg.d1 where value regexp '^[A-Za-z]+$'
select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100
select b, b like '1%', b regexp '[0-2]' from root.test;
# `IS NULL` operator
select code from root.sg1.d1 where temperature is null;
select code from root.sg1.d1 where temperature is not null;
# `IN` operator
select code from root.sg1.d1 where code in ('200', '300', '400', '500');
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');
select a, a in (1, 2) from root.test;逻辑运算符
更多见文档Logical Operators
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;内置函数
Aggregate Functions
更多见文档Aggregate Functions
select count(status) from root.ln.wf01.wt01;
select count_if(s1=0 & s2=0, 3), count_if(s1=1 & s2=0, 3) from root.db.d1;
select count_if(s1=0 & s2=0, 3, 'ignoreNull'='false'), count_if(s1=1 & s2=0, 3, 'ignoreNull'='false') from root.db.d1;
select time_duration(s1) from root.db.d1;算数函数
更多见文档Arithmetic Operators and Functions
select s1, sin(s1), cos(s1), tan(s1) from root.sg1.d1 limit 5 offset 1000;
select s4,round(s4),round(s4,2),round(s4,-1) from root.sg1.d1;比较函数
更多见文档Comparison Operators and Functions
select ts, on_off(ts, 'threshold'='2') from root.test;
select ts, in_range(ts, 'lower'='2', 'upper'='3.1') from root.test;字符串处理函数
更多见文档String Processing
select s1, string_contains(s1, 's'='warn') from root.sg1.d4;
select s1, string_matches(s1, 'regex'='[^\\s]+37229') from root.sg1.d4;
select s1, length(s1) from root.sg1.d1
select s1, locate(s1, "target"="1") from root.sg1.d1
select s1, locate(s1, "target"="1", "reverse"="true") from root.sg1.d1
select s1, startswith(s1, "target"="1") from root.sg1.d1
select s1, endswith(s1, "target"="1") from root.sg1.d1
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB") from root.sg1.d1
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB", "series_behind"="true") from root.sg1.d1
select s1, substring(s1 from 1 for 2) from root.sg1.d1
select s1, replace(s1, 'es', 'tt') from root.sg1.d1
select s1, upper(s1) from root.sg1.d1
select s1, lower(s1) from root.sg1.d1
select s3, trim(s3) from root.sg1.d1
select s1, s2, strcmp(s1, s2) from root.sg1.d1
select strreplace(s1, "target"=",", "replace"="/", "limit"="2") from root.test.d1
select strreplace(s1, "target"=",", "replace"="/", "limit"="1", "offset"="1", "reverse"="true") from root.test.d1
select regexmatch(s1, "regex"="\d+\.\d+\.\d+\.\d+", "group"="0") from root.test.d1
select regexreplace(s1, "regex"="192\.168\.0\.(\d+)", "replace"="cluster-$1", "limit"="1") from root.test.d1
select regexsplit(s1, "regex"=",", "index"="-1") from root.test.d1
select regexsplit(s1, "regex"=",", "index"="3") from root.test.d1数据类型转换函数
更多见文档Data Type Conversion Function
SELECT cast(s1 as INT32) from root.sg常序列生成函数
更多见文档Constant Timeseries Generating Functions
select s1, s2, const(s1, 'value'='1024', 'type'='INT64'), pi(s2), e(s1, s2) from root.sg1.d1;选择函数
更多见文档Selector Functions
select s1, top_k(s1, 'k'='2'), bottom_k(s1, 'k'='2') from root.sg1.d2 where time > 2020-12-10T20:36:15.530+08:00;区间查询函数
更多见文档Continuous Interval Functions
select s1, zero_count(s1), non_zero_count(s2), zero_duration(s3), non_zero_duration(s4) from root.sg.d2;趋势计算函数
更多见文档Variation Trend Calculation Functions
select s1, time_difference(s1), difference(s1), non_negative_difference(s1), derivative(s1), non_negative_derivative(s1) from root.sg1.d1 limit 5 offset 1000;
SELECT DIFF(s1), DIFF(s2) from root.test;
SELECT DIFF(s1, 'ignoreNull'='false'), DIFF(s2, 'ignoreNull'='false') from root.test;采样函数
更多见文档Sample Functions
select equal_size_bucket_random_sample(temperature,'proportion'='0.1') as random_sample from root.ln.wf01.wt01;
select equal_size_bucket_agg_sample(temperature, 'type'='avg','proportion'='0.1') as agg_avg, equal_size_bucket_agg_sample(temperature, 'type'='max','proportion'='0.1') as agg_max, equal_size_bucket_agg_sample(temperature,'type'='min','proportion'='0.1') as agg_min, equal_size_bucket_agg_sample(temperature, 'type'='sum','proportion'='0.1') as agg_sum, equal_size_bucket_agg_sample(temperature, 'type'='extreme','proportion'='0.1') as agg_extreme, equal_size_bucket_agg_sample(temperature, 'type'='variance','proportion'='0.1') as agg_variance from root.ln.wf01.wt01;
select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01;
select equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='avg', 'number'='2') as outlier_avg_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='stendis', 'number'='2') as outlier_stendis_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='cos', 'number'='2') as outlier_cos_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='prenextdis', 'number'='2') as outlier_prenextdis_sample from root.ln.wf01.wt01;
select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1
select M4(s1,'windowSize'='10') from root.vehicle.d1时间序列处理函数
更多见文档Time-Series
select change_points(s1), change_points(s2), change_points(s3), change_points(s4), change_points(s5), change_points(s6) from root.testChangePoints.d1数据质量函数库
数据质量
更多见文档Data-Quality
# Completeness
select completeness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30
select completeness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00
# Consistency
select consistency(s1) from root.test.d1 where time <= 2020-01-01 00:00:30
select consistency(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00
# Timeliness
select timeliness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30
select timeliness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00
# Validity
select Validity(s1) from root.test.d1 where time <= 2020-01-01 00:00:30
select Validity(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00
# Accuracy
select Accuracy(t1,t2,t3,m1,m2,m3) from root.test数据画像
更多见文档Data-Profiling
# ACF
select acf(s1) from root.test.d1 where time <= 2020-01-01 00:00:05
# Distinct
select distinct(s2) from root.test.d2
# Histogram
select histogram(s1,"min"="1","max"="20","count"="10") from root.test.d1
# Integral
select integral(s1) from root.test.d1 where time <= 2020-01-01 00:00:10
select integral(s1, "unit"="1m") from root.test.d1 where time <= 2020-01-01 00:00:10
# IntegralAvg
select integralavg(s1) from root.test.d1 where time <= 2020-01-01 00:00:10
# Mad
select mad(s0) from root.test
select mad(s0, "error"="0.01") from root.test
# Median
select median(s0, "error"="0.01") from root.test
# MinMax
select minmax(s1) from root.test
# Mode
select mode(s2) from root.test.d2
# MvAvg
select mvavg(s1, "window"="3") from root.test
# PACF
select pacf(s1, "lag"="5") from root.test
# Percentile
select percentile(s0, "rank"="0.2", "error"="0.01") from root.test
# Quantile
select quantile(s0, "rank"="0.2", "K"="800") from root.test
# Period
select period(s1) from root.test.d3
# QLB
select QLB(s1) from root.test.d1
# Resample
select resample(s1,'every'='5m','interp'='linear') from root.test.d1
select resample(s1,'every'='30m','aggr'='first') from root.test.d1
select resample(s1,'every'='30m','start'='2021-03-06 15:00:00') from root.test.d1
# Sample
select sample(s1,'method'='reservoir','k'='5') from root.test.d1
select sample(s1,'method'='isometric','k'='5') from root.test.d1
# Segment
select segment(s1, "error"="0.1") from root.test
# Skew
select skew(s1) from root.test.d1
# Spline
select spline(s1, "points"="151") from root.test
# Spread
select spread(s1) from root.test.d1 where time <= 2020-01-01 00:00:30
# Stddev
select stddev(s1) from root.test.d1
# ZScore
select zscore(s1) from root.test异常检测
更多见文档Anomaly-Detection
# IQR
select iqr(s1) from root.test
# KSigma
select ksigma(s1,"k"="1.0") from root.test.d1 where time <= 2020-01-01 00:00:30
# LOF
select lof(s1,s2) from root.test.d1 where time<1000
select lof(s1, "method"="series") from root.test.d1 where time<1000
# MissDetect
select missdetect(s2,'minlen'='10') from root.test.d2
# Range
select range(s1,"lower_bound"="101.0","upper_bound"="125.0") from root.test.d1 where time <= 2020-01-01 00:00:30
# TwoSidedFilter
select TwoSidedFilter(s0, 'len'='5', 'threshold'='0.3') from root.test
# Outlier
select outlier(s1,"r"="5.0","k"="4","w"="10","s"="5") from root.test
# MasterTrain
select MasterTrain(lo,la,m_lo,m_la,'p'='3','eta'='1.0') from root.test
# MasterDetect
select MasterDetect(lo,la,m_lo,m_la,model,'output_type'='repair','p'='3','k'='3','eta'='1.0') from root.test
select MasterDetect(lo,la,m_lo,m_la,model,'output_type'='anomaly','p'='3','k'='3','eta'='1.0') from root.test频域分析
更多见文档Frequency-Domain
# Conv
select conv(s1,s2) from root.test.d2
# Deconv
select deconv(s3,s2) from root.test.d2
select deconv(s3,s2,'result'='remainder') from root.test.d2
# DWT
select dwt(s1,"method"="haar") from root.test.d1
# FFT
select fft(s1) from root.test.d1
select fft(s1, 'result'='real', 'compress'='0.99'), fft(s1, 'result'='imag','compress'='0.99') from root.test.d1
# HighPass
select highpass(s1,'wpass'='0.45') from root.test.d1
# IFFT
select ifft(re, im, 'interval'='1m', 'start'='2021-01-01 00:00:00') from root.test.d1
# LowPass
select lowpass(s1,'wpass'='0.45') from root.test.d1数据匹配
更多见文档Data-Matching
# Cov
select cov(s1,s2) from root.test.d2
# DTW
select dtw(s1,s2) from root.test.d2
# Pearson
select pearson(s1,s2) from root.test.d2
# PtnSym
select ptnsym(s4, 'window'='5', 'threshold'='0') from root.test.d1
# XCorr
select xcorr(s1, s2) from root.test.d1 where time <= 2020-01-01 00:00:05数据修复
更多见文档Data-Repairing
# TimestampRepair
select timestamprepair(s1,'interval'='10000') from root.test.d2
select timestamprepair(s1) from root.test.d2
# ValueFill
select valuefill(s1) from root.test.d2
select valuefill(s1,"method"="previous") from root.test.d2
# ValueRepair
select valuerepair(s1) from root.test.d2
select valuerepair(s1,'method'='LsGreedy') from root.test.d2
# MasterRepair
select MasterRepair(t1,t2,t3,m1,m2,m3) from root.test
# SeasonalRepair
select seasonalrepair(s1,'period'=3,'k'=2) from root.test.d2
select seasonalrepair(s1,'method'='improved','period'=3) from root.test.d2序列发现
更多见文档Series-Discovery
# ConsecutiveSequences
select consecutivesequences(s1,s2,'gap'='5m') from root.test.d1
select consecutivesequences(s1,s2) from root.test.d1
# ConsecutiveWindows
select consecutivewindows(s1,s2,'length'='10m') from root.test.d1机器学习
更多见文档Machine-Learning
# AR
select ar(s0,"p"="2") from root.test.d0
# Representation
select representation(s0,"tb"="3","vb"="2") from root.test.d0
# RM
select rm(s0, s1,"tb"="3","vb"="2") from root.test.d0Lambda 表达式
更多见文档Lambda
select jexl(temperature, 'expr'='x -> {x + x}') as jexl1, jexl(temperature, 'expr'='x -> {x * 3}') as jexl2, jexl(temperature, 'expr'='x -> {x * x}') as jexl3, jexl(temperature, 'expr'='x -> {multiply(x, 100)}') as jexl4, jexl(temperature, st, 'expr'='(x, y) -> {x + y}') as jexl5, jexl(temperature, st, str, 'expr'='(x, y, z) -> {x + y + z}') as jexl6 from root.ln.wf01.wt01;```条件表达式
select T, P, case
when 1000<T and T<1050 and 1000000<P and P<1100000 then "good!"
when T<=1000 or T>=1050 then "bad temperature"
when P<=1000000 or P>=1100000 then "bad pressure"
end as `result`
from root.test1
select str, case
when str like "%cc%" then "has cc"
when str like "%dd%" then "has dd"
else "no cc and dd" end as `result`
from root.test2
select
count(case when x<=1 then 1 end) as `(-∞,1]`,
count(case when 1<x and x<=3 then 1 end) as `(1,3]`,
count(case when 3<x and x<=7 then 1 end) as `(3,7]`,
count(case when 7<x then 1 end) as `(7,+∞)`
from root.test3
select x, case x when 1 then "one" when 2 then "two" else "other" end from root.test4
select x, case x when 1 then true when 2 then false end as `result` from root.test4
select x, case x
when 1 then 1
when 2 then 222222222222222
when 3 then 3.3
when 4 then 4.4444444444444
end as `result`
from root.test4触发器
使用 SQL 语句注册该触发器
// Create Trigger
createTrigger
: CREATE triggerType TRIGGER triggerName=identifier triggerEventClause ON pathPattern AS className=STRING_LITERAL uriClause? triggerAttributeClause?
;
triggerType
: STATELESS | STATEFUL
;
triggerEventClause
: (BEFORE | AFTER) INSERT
;
uriClause
: USING URI uri
;
uri
: STRING_LITERAL
;
triggerAttributeClause
: WITH LR_BRACKET triggerAttribute (COMMA triggerAttribute)* RR_BRACKET
;
triggerAttribute
: key=attributeKey operator_eq value=attributeValue
;SQL 语句示例
CREATE STATELESS TRIGGER triggerTest
BEFORE INSERT
ON root.sg.**
AS 'org.apache.iotdb.trigger.ClusterAlertingExample'
USING URI 'http://jar/ClusterAlertingExample.jar'
WITH (
"name" = "trigger",
"limit" = "100"
)卸载触发器
卸载触发器的 SQL 语法如下:
// Drop Trigger
dropTrigger
: DROP TRIGGER triggerName=identifier
;示例语句
DROP TRIGGER triggerTest1查询触发器
SHOW TRIGGERS连续查询(Continuous Query, CQ)
语法
CREATE (CONTINUOUS QUERY | CQ) <cq_id>
[RESAMPLE
[EVERY <every_interval>]
[BOUNDARY <execution_boundary_time>]
[RANGE <start_time_offset>[, end_time_offset]]
]
[TIMEOUT POLICY BLOCKED|DISCARD]
BEGIN
SELECT CLAUSE
INTO CLAUSE
FROM CLAUSE
[WHERE CLAUSE]
[GROUP BY(<group_by_interval>[, <sliding_step>]) [, level = <level>]]
[HAVING CLAUSE]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
END配置连续查询执行的周期性间隔
CREATE CONTINUOUS QUERY cq1
RESAMPLE EVERY 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
END
\> SELECT temperature_max from root.ln.*.*;配置连续查询的时间窗口大小
CREATE CONTINUOUS QUERY cq2
RESAMPLE RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
END
\> SELECT temperature_max from root.ln.*.*;同时配置连续查询执行的周期性间隔和时间窗口大小
CREATE CONTINUOUS QUERY cq3
RESAMPLE EVERY 20s RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
END
\> SELECT temperature_max from root.ln.*.*;配置连续查询每次查询执行时间窗口的结束时间
CREATE CONTINUOUS QUERY cq4
RESAMPLE EVERY 20s RANGE 40s, 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
END
\> SELECT temperature_max from root.ln.*.*;没有GROUP BY TIME子句的连续查询
CREATE CONTINUOUS QUERY cq5
RESAMPLE EVERY 20s
BEGIN
SELECT temperature + 1
INTO root.precalculated_sg.::(temperature)
FROM root.ln.*.*
align by device
END
\> SELECT temperature from root.precalculated_sg.*.* align by device;连续查询的管理
查询系统已有的连续查询
展示集群中所有的已注册的连续查询
SHOW (CONTINUOUS QUERIES | CQS)
SHOW CONTINUOUS QUERIES;删除已有的连续查询
删除指定的名为cq_id的连续查询:
DROP (CONTINUOUS QUERY | CQ) <cq_id>DROP CONTINUOUS QUERY s1_count_cq;作为子查询的替代品
\1. 创建一个连续查询
CREATE CQ s1_count_cq
BEGIN
SELECT count(s1)
INTO root.sg_count.d.count_s1
FROM root.sg.d
GROUP BY(30m)
END- 查询连续查询的结果
SELECT avg(count_s1) from root.sg_count.d;用户自定义函数
UDFParameters
SELECT UDF(s1, s2, 'key1'='iotdb', 'key2'='123.45') FROM root.sg.d;UDF 注册
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME> (USING URI URI-STRING)?不指定URI
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample'指定URI
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample' USING URI 'http://jar/example.jar'UDF 卸载
DROP FUNCTION <UDF-NAME>DROP FUNCTION exampleUDF 查询
带自定义输入参数的查询
SELECT example(s1, 'key1'='value1', 'key2'='value2'), example(*, 'key3'='value3') FROM root.sg.d1;
SELECT example(s1, s2, 'key1'='value1', 'key2'='value2') FROM root.sg.d1;与其他查询的嵌套查询
SELECT s1, s2, example(s1, s2) FROM root.sg.d1;
SELECT *, example(*) FROM root.sg.d1 DISABLE ALIGN;
SELECT s1 * example(* / s1 + s2) FROM root.sg.d1;
SELECT s1, s2, s1 + example(s1, s2), s1 - example(s1 + example(s1, s2) / s2) FROM root.sg.d1;查看所有注册的 UDF
SHOW FUNCTIONS权限管理
1、创建用户
CREATE USER `ln_write_user` 'write_pwd'
CREATE USER `sgcc_write_user` 'write_pwd'2、展示用户
LIST USER3、赋予用户权限
INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
系统不允许用户进行此操作,会提示错误:
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
Msg: 602: No permissions for this operation, please add privilege INSERT_TIMESERIES.
用root用户分别赋予他们向对应 database 数据的写入权限
GRANT USER `ln_write_user` PRIVILEGES INSERT_TIMESERIES on root.ln.**
GRANT USER `sgcc_write_user` PRIVILEGES INSERT_TIMESERIES on root.sgcc1.**, root.sgcc2.**
GRANT USER `ln_write_user` PRIVILEGES CREATE_USER
使用ln_write_user再尝试写入数据
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp, status) values(1509465600000, true)
Msg: The statement is executed successfully.4、撤销用户权限
用root用户撤销ln_write_user和sgcc_write_user的权限:
REVOKE USER `ln_write_user` PRIVILEGES INSERT_TIMESERIES on root.ln.**
REVOKE USER `sgcc_write_user` PRIVILEGES INSERT_TIMESERIES on root.sgcc1.**, root.sgcc2.**
REVOKE USER `ln_write_user` PRIVILEGES CREATE_USER撤销权限后,ln_write_user就没有向root.ln.**写入数据的权限了
INSERT INTO root.ln.wf01.wt01(timestamp, status) values(1509465600000, true)
Msg: 602: No permissions for this operation, please add privilege INSERT_TIMESERIES.5、SQL 语句
- 创建用户
CREATE USER <userName> <password>;Eg: IoTDB > CREATE USER thulab 'passwd';
- 删除用户
DROP USER <userName>;Eg: IoTDB > DROP USER xiaoming;
- 创建角色
CREATE ROLE <roleName>;Eg: IoTDB > CREATE ROLE admin;
- 删除角色
DROP USER <userName>;Eg: IoTDB > DROP USER xiaoming;
- 赋予用户权限
GRANT USER <userName> PRIVILEGES <privileges> ON <nodeNames>;Eg: IoTDB > GRANT USER tempuser PRIVILEGES INSERT_TIMESERIES, DELETE_TIMESERIES on root.ln., root.sgcc.;
Eg: IoTDB > GRANT USER tempuser PRIVILEGES CREATE_ROLE;
- 赋予用户全部的权限
GRANT USER <userName> PRIVILEGES ALL;Eg: IoTDB > GRANT USER tempuser PRIVILEGES ALL;
- 赋予角色权限
GRANT ROLE <roleName> PRIVILEGES <privileges> ON <nodeNames>;Eg: IoTDB > GRANT ROLE temprole PRIVILEGES INSERT_TIMESERIES, DELETE_TIMESERIES ON root.sgcc., root.ln.;
Eg: IoTDB > GRANT ROLE temprole PRIVILEGES CREATE_ROLE;
- 赋予角色全部的权限
GRANT ROLE <roleName> PRIVILEGES ALL;Eg: IoTDB > GRANT ROLE temprole PRIVILEGES ALL;
- 赋予用户角色
GRANT <roleName> TO <userName>;Eg: IoTDB > GRANT temprole TO tempuser;
- 撤销用户权限
REVOKE USER <userName> PRIVILEGES <privileges> ON <nodeNames>;Eg: IoTDB > REVOKE USER tempuser PRIVILEGES DELETE_TIMESERIES on root.ln.**;
Eg: IoTDB > REVOKE USER tempuser PRIVILEGES CREATE_ROLE;
- 移除用户所有权限
REVOKE USER <userName> PRIVILEGES ALL;Eg: IoTDB > REVOKE USER tempuser PRIVILEGES ALL;
- 撤销角色权限
REVOKE ROLE <roleName> PRIVILEGES <privileges> ON <nodeNames>;Eg: IoTDB > REVOKE ROLE temprole PRIVILEGES DELETE_TIMESERIES ON root.ln.**;
Eg: IoTDB > REVOKE ROLE temprole PRIVILEGES CREATE_ROLE;
- 撤销角色全部的权限
REVOKE ROLE <roleName> PRIVILEGES ALL;Eg: IoTDB > REVOKE ROLE temprole PRIVILEGES ALL;
- 撤销用户角色
REVOKE <roleName> FROM <userName>;Eg: IoTDB > REVOKE temprole FROM tempuser;
- 列出所有用户
LIST USER
Eg: IoTDB > LIST USER
- 列出指定角色下所有用户
LIST USER OF ROLE <roleName>;Eg: IoTDB > LIST USER OF ROLE roleuser;
- 列出所有角色
REVOKE <roleName> FROM <userName>;Eg: IoTDB > REVOKE temprole FROM tempuser;
- 列出指定用户下所有角色
LIST USER OF ROLE <roleName>;Eg: IoTDB > LIST USER OF ROLE roleuser;
- 列出用户所有权限
LIST PRIVILEGES USER <username>;Eg: IoTDB > LIST PRIVILEGES USER tempuser;
- 列出用户在具体路径上相关联的权限
LIST PRIVILEGES USER <username> ON <paths>;Eg: IoTDB> LIST PRIVILEGES USER tempuser ON root.ln., root.ln.wf01.;
IoTDB> LIST PRIVILEGES USER tempuser ON root.ln.wf01.wt01.**;
- 列出角色所有权限
LIST PRIVILEGES ROLE <roleName>;Eg: IoTDB > LIST PRIVILEGES ROLE actor;
- 列出角色在具体路径上相关联的权限
LIST PRIVILEGES ROLE <roleName> ON <paths>;Eg: IoTDB> LIST PRIVILEGES ROLE temprole ON root.ln., root.ln.wf01.wt01.;
IoTDB> LIST PRIVILEGES ROLE temprole ON root.ln.wf01.wt01.**;
- 更新密码
ALTER USER <username> SET PASSWORD <password>;Eg: IoTDB > ALTER USER tempuser SET PASSWORD 'newpwd';
6、非root用户限制进行的操作
TsFile管理
- 加载TsFile
Eg: IoTDB > load '/Users/Desktop/data/1575028885956-101-0.tsfile'
- 删除TsFile文件
Eg: IoTDB > remove '/Users/Desktop/data/data/root.vehicle/0/0/1575028885956-101-0.tsfile'
- 卸载TsFile文件到指定目录
Eg: IoTDB > unload '/Users/Desktop/data/data/root.vehicle/0/0/1575028885956-101-0.tsfile' '/data/data/tmp'
删除时间分区(实验性功能)
- 删除时间分区(实验性功能)
Eg: IoTDB > DELETE PARTITION root.ln 0,1,2
连续查询
- 连续查询(CQ)
Eg: IoTDB > CREATE CONTINUOUS QUERY cq1 BEGIN SELECT max_value(temperature) INTO temperature_max FROM root.ln.. GROUP BY time(10s) END
运维命令
- FLUSH
Eg: IoTDB > flush
- MERGE
Eg: IoTDB > MERGE
Eg: IoTDB > FULL MERGE
- CLEAR CACHE
Eg: IoTDB > CLEAR CACHE
- SET SYSTEM TO READONLY / WRITABLE
Eg: IoTDB > SET SYSTEM TO READONLY / WRITABLE
- 查询终止
Eg: IoTDB > KILL QUERY 1
水印工具
- 为新用户施加水印
Eg: IoTDB > grant watermark_embedding to Alice
- 撤销水印
Eg: IoTDB > revoke watermark_embedding from Alice